
Remember me
Data Collection and Preprocessing: A total of 1,465 cells were missing in the dataset, resulting in an overall missing rate of 4.27%. No variable had a missing rate exceeding 50%, and all variables met the data quality requirements for modeling. Among the 83.82% of patients with incomplete data, 67.1% were missing only 1–2 variables (316 + 306).For example, no patients had data rendered unusable due to excessive missing values; the missing rates for CRP (overall missing rate: 42.93%) and urinary red blood cell count (39.05%) both exceeded 30%. Based on clinical practice analysis, these high levels of missing data likely stem from differences in testing indications among non-sepsis patients. Retaining such variables with high missing rates could introduce modeling bias; therefore, we excluded these two variables from the analytical model. The sepsis group exhibited significantly better data completeness than the non-sepsis group (42.47% vs. 13.93%), possibly because clinical records for critically ill patients tend to be more detailed. We employed Multiple Imputation by Chained Equations (MICE) to impute missing values, using patient age, underlying comorbidities, and relevant laboratory indicators as auxiliary variables to build the imputation model in Table 1.
Table 1 Baseline characteristics and univariate analysis of modeling set and validation setUnivariate analysis of risk factors for urinary-source sepsisAmong the 927 patients who underwent ureteroscopic lithotripsy, 73 developed urinary-source sepsis, while 854 did not. Univariate analysis revealed that the occurrence of urinary-source sepsis following upper urinary tract stone disease was statistically associated with 24 factors (P < 0.05), of which 21 factors showed strong statistical associations (P < 0.001), 2 factors showed moderate statistical associations (P < 0.01), and 1 factor showed a weak statistical association (P < 0.05). Specifically, these included 17 continuous variables: age, heart rate, respiration, BMI, frailty score, number of previous stone procedures, degree of hydronephrosis, procedure duration, maximum diameter of the stone (mm), albumin, creatinine, procalcitonin, white blood cell count, neutrophil count, lymphocyte count, platelet count, and urinary white blood cell count per microliter; as well as 7 categorical variables: gender, non-independent functional status, diabetes, hypertension, urinary tract infection, stone obstruction, stone location, and urine culture results (all P < 0.05).
Feature standardization and selectionThis study employs a multi-step feature selection strategy to develop a urinary sepsis prediction model that balances predictive performance with clinical interpretability in Fig. 1. First, the Boruta algorithm, which is based on random forests, is used for feature screening by comparing real features with randomly generated ones.The “shadow features” were iteratively compared, and a total of 17 predictors with statistical significance were identified, including age, heart rate, BMI, frailty score, urinary tract infection, degree of hydronephrosis, surgical duration, stone location, maximum stone diameter, albumin, creatinine, procalcitonin, white blood cell count, neutrophil count, lymphocyte count, platelet count, and urinary white blood cells. The distribution of feature importance was visualized using box plots. LASSO regression was employed to screen the variables that showed statistical significance in the univariate analysis of the modeling dataset, with five-fold cross-validation used to prevent overfitting. The results indicated that, among the variables selected between Lambda.1se (λ = 0.00247) and Lambda.min (λ = 0.0327), nine predictors—gender, frailty score, urinary tract infection, stone obstruction, degree of hydronephrosis, maximum stone diameter, albumin, procalcitonin, and urine culture—were retained. Finally, a Venn diagram was used to compare the feature-selection results obtained by the Boruta and LASSO methods, identifying six core predictors that were consistently confirmed by both approaches (frailty score, urinary tract infection, degree of hydronephrosis, maximum stone diameter, albumin, and procalcitonin), thereby enhancing the robustness of feature selection and improving the interpretability of the results.
Fig. 1
Feature standardization and selection. A: Significant features identified by the Boruta algorithm and their importance distribution in random forest. B: Regularization path and cross-validation error curve of LASSO regression, with the optimal λ and the λ value corresponding to the 1-SE rule labeled. C: Path plot of LASSO regression coefficients varying with regularization strength. D: Venn diagram of results from LASSO and Boruta feature selection methods, showing the number of overlapping and distinct features
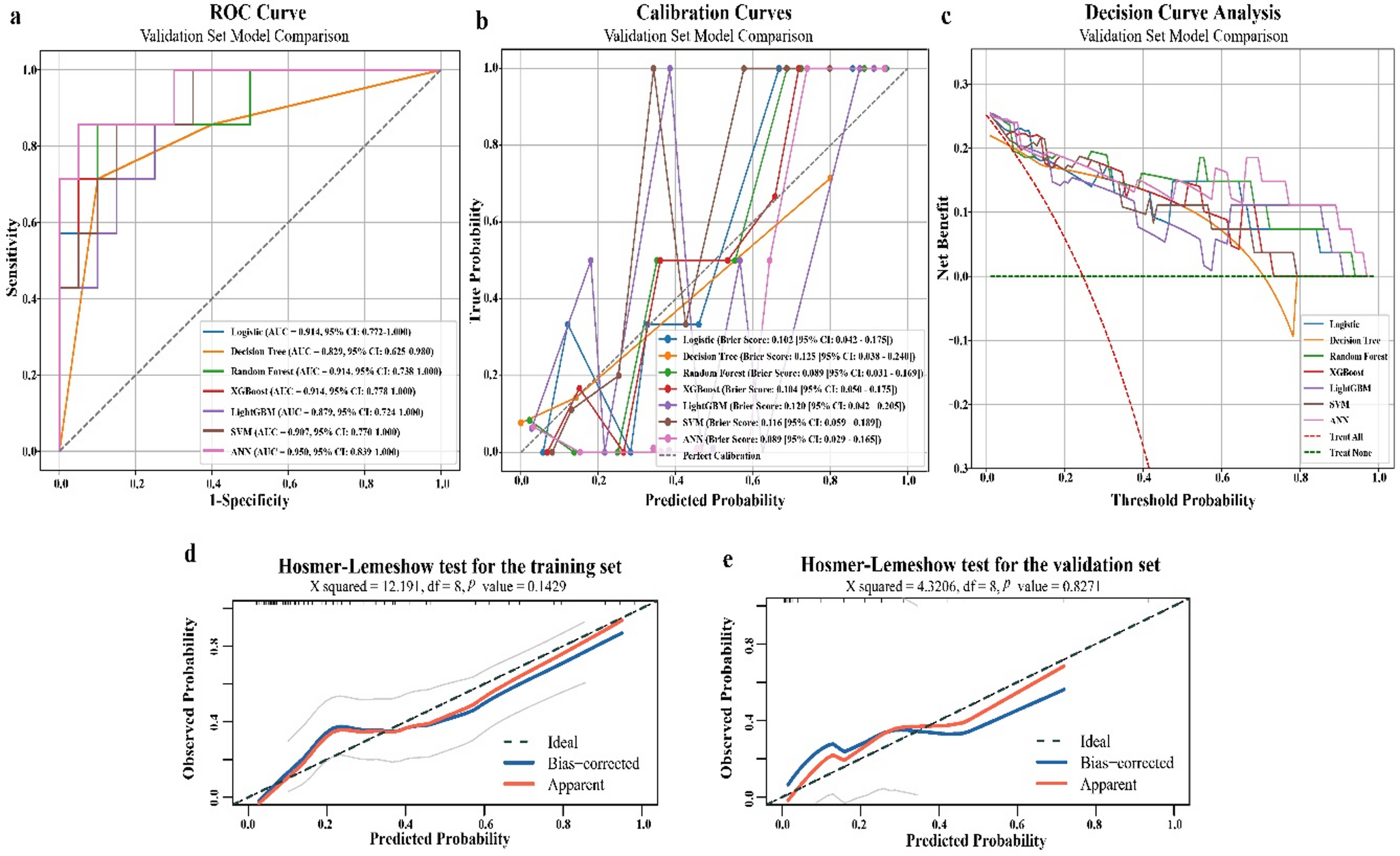
Model construction and comparisonWe constructed and compared the performance of four machine learning models (SVM, LR, RF, and XGBoost) in predicting urinary sepsis in Fig. 2. On the training set, all models demonstrated excellent discrimination ability, with XGBoost achieving the highest AUC (0.998; 95% CI: 0.99–1.00). Moreover, XGBoost outperformed other models in terms of sensitivity (0.82), accuracy (0.98), and F1 score (0.87), indicating its exceptional fitting capability. On the internal test set, the performance of each model declined slightly; however, XGBoost still maintained the highest F1 score (0.77) and sensitivity (0.74), with an AUC that remained stable at 0.98 (95% CI: 0.97–1.00), suggesting good generalization on the internal data. In the critical external validation phase, model performance showed significant divergence. Both RF and XGBoost achieved an AUC of 0.99 and an accuracy of 0.96; however, RF’s sensitivity was only 0.43, whereas XGBoost’s sensitivity improved to 0.57, and it also had the highest F1 score (0.67). By contrast, SVM and LR exhibited markedly reduced sensitivity and F1 scores in the external validation (both at 0.38 and 0.46, respectively), indicating insufficient generalization capability.
Overall, the XGBoost model demonstrated robust and excellent performance in training, internal testing, and external validation, with particular advantages in sensitivity. This makes it more clinically valuable for the early prediction of urosepsis, effectively reducing the risk of missed diagnoses in Table 2.
Fig. 2
Model construction and comprision.Figure A–C: ROC curves evaluating the predictive performance of models in the training, internal test, and external validation cohorts, using AUCas the efficacy metric.D–F: Decision curve analysis (DCA) assessing the clinical utility of each model in the training, internal test, and external validation datasets. The y-axis represents net benefit, and the x-axis indicates threshold probability.G–I: Calibration curves for the three datasets, illustrating the calibration of different machine learning models by comparing predicted probabilities against observed outcomes. The black dashed line represents ideal calibration, while solid lines denote the performance of individual models. Solid lines closely aligned with the dashed line indicate superior calibration.
Table 2 Performance Comparison of the Predictive ModelsOptimal model for SHAPAs shown in Fig. 3, the SHAP values are used to explain the contribution of each variable to the XGBoost predictive model. The variables are ranked in order of importance as follows: procalcitonin, albumin, degree of hydronephrosis, frailty score, maximum diameter of the stone, and urinary tract infection. The specific value assignments for each indicator are shown in the figure. From the single-sample explanation analysis, we can clearly determine the contribution value, direction of impact, and predicted risk of each feature in an individual sample with respect to the patient’s development of urosepticemia, thereby enabling us to assess the patient’s risk of urosepticemia.
Fig. 3
SHAP-based explanation of model mechanisms. Figure A shows the relative importance of each feature in the model, with dots color-coded to reflect the actual feature values, where red indicates higher feature values and blue indicates lower feature values. An increase in SHAP values is associated with an increased probability of urosepsis. Figures B and C show the relevant feature conditions of patients who may progress to urosepsis and those who do not have urosepsis, respectively
Web applicationThe application based on this combined model has been deployed online (https://urosepsis-app-ans3rh7lykhda9p9mh95pf.streamlit.app/) to promote its practicality in clinical settings. When the actual feature values for each patient are entered, the application generates a probability of urosepsis.
Comments (0)