
Remember me


In the previous section, I argued that Implicit Self captures an important aspect of perception. It describes perceptual representations in which the locations of objects are specified relative to an egocentric reference frame. I contended that in basic representations like these, we have reason to believe that the frame used is implicit, and consequently, that the information it carries about the self is also implicit. However, we should be cautious about accepting Implicit Self as a general principle. This skepticism arises because egocentric reference frames are not limited to functioning as reference frames, as they do in standard cases; they also seem to function as objects whose locations are specified. This occurs in creatures like us, whose perceptual systems use many egocentric reference frames and must track their variable spatial relations. When one reference frame is represented at a location relative to another, the former assumes the role of an object while the latter serves as a reference frame. To account for these cases, this section proposes the Nested Frames View as a new theory of how egocentric reference frames are used in perception. As I will discuss, the view seems to show how the information about the self carried by such frames comes to be explicitly represented in perception.
For context, empirical research on reference frames has often focused on where in the brain different frames are implemented and what cognitive processes they underwrite (Andersen and Zipser 1988; Barendregt et al. 2015; Chen et al. 2013; Colby and Duhamel 1996; Groh 2014; O’Keefe and Dostrovsky 1971). In philosophy, a central concern has been why our experiences appear unified despite the use of many frames (Alsmith 2020; Briscoe 2009; Grush 2000). My question here is different: how are reference frames represented relative to one another, and what does this reveal about how the self is represented in perception?
The Nested Frames View addresses this question in two parts. The first concerns the representational relations between the egocentric reference frames used by a creature in perception.Footnote 10 The view proposes that within a given perceptual system, one reference frame is nested within another, meaning that the former is represented at a location relative to the latter. This nesting relation then iterates. Imagine a creature that uses three reference frames: RF0, RF1, RF2. If RF0 is nested within RF1 and RF1 is nested within RF2, this means that RF0 is represented at a location relative to RF1 and RF1 is represented at a location relative to RF2.Footnote 11
The second component of the Nested Frames View describes when egocentric reference frames are implicit and explicit based on their role in the nested structure. This builds on insights from existing work suggesting that egocentric frames can shift between being implicit and explicit. Grush (2000), for instance, argues that what he calls a point of view (POV) functions as the implicit anchor of an egocentric space but becomes explicitly represented when coordinated with an allocentric frame (p. 82). While Grush focuses on egocentric-to-allocentric coordination, the Nested Frames View extends his idea to egocentric-to-egocentric relations. Specifically, the view holds that for any given pair of nested frames, the nested frame is explicit and the nesting frame is implicit. In other words, when one frame is represented at a location relative to another, the former is explicitly represented and the latter is architecturally encoded. This entails that when RF0 is nested within RF1, which is nested within RF2, RF0 is explicitly represented at a location relative to RF1, which is architecturally encoded, and RF1 is explicitly represented at a location relative to RF2, which is architecturally encoded.
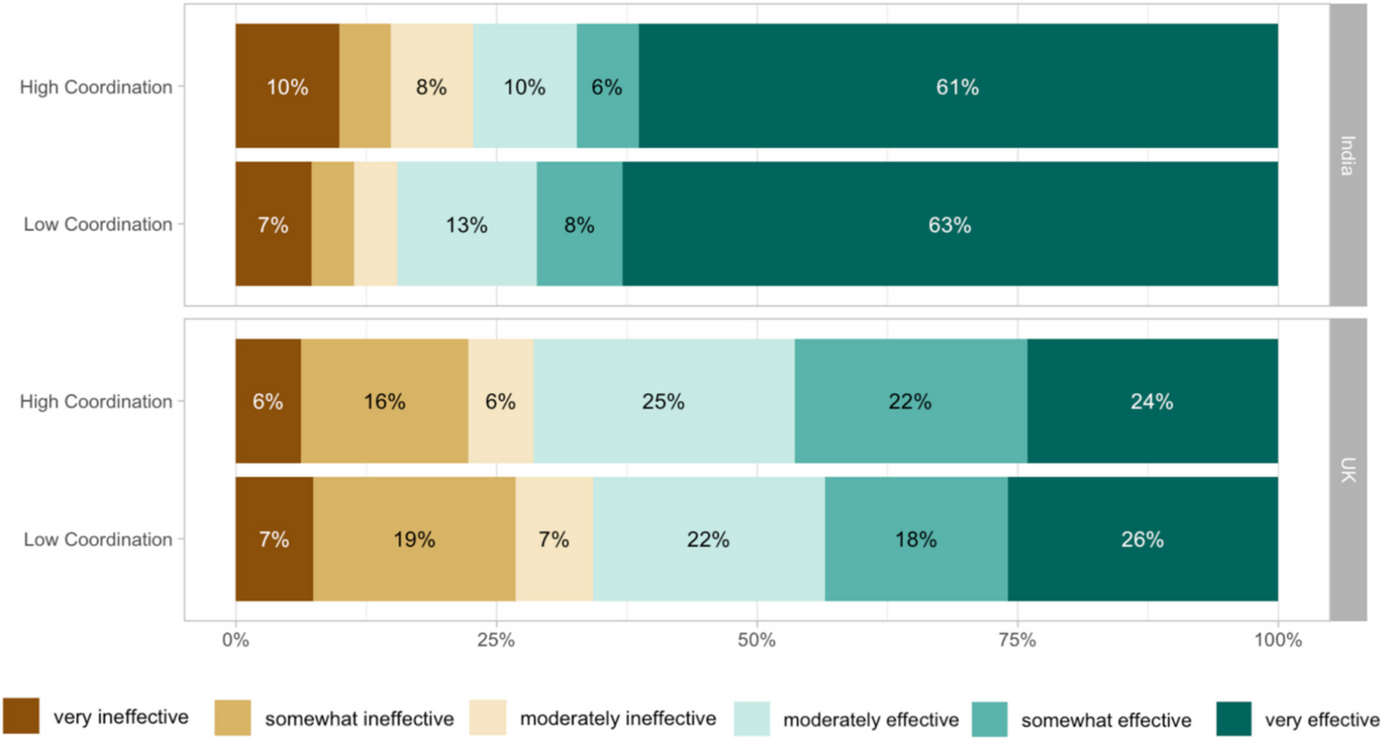
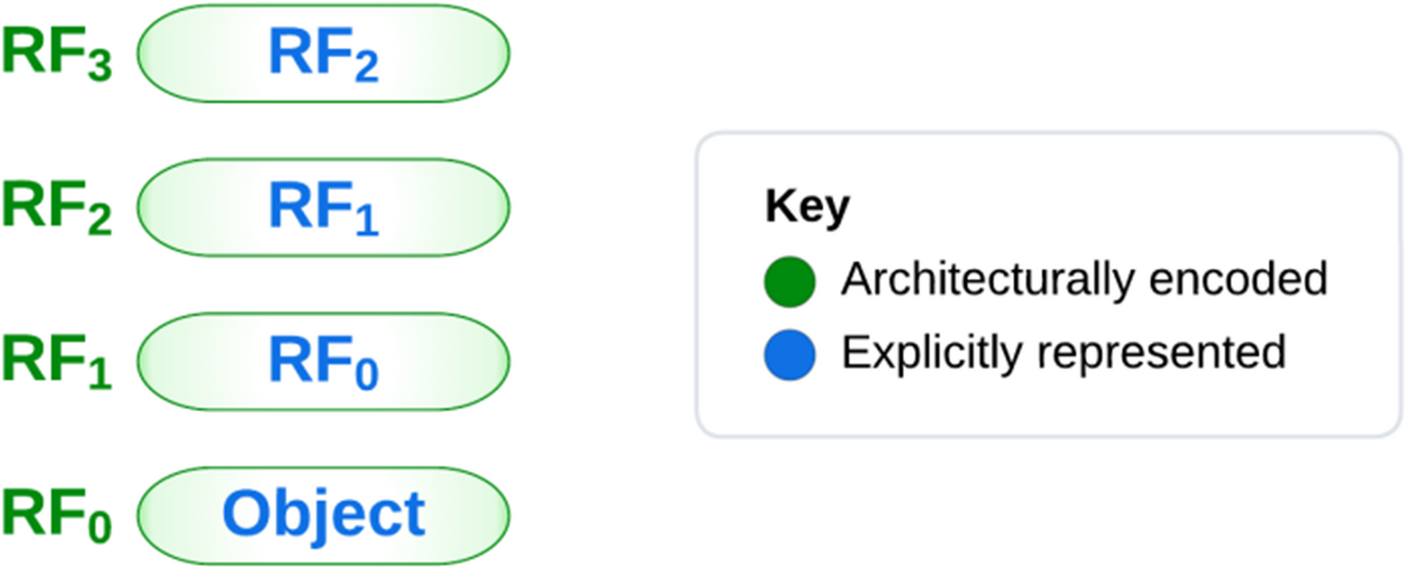
To illustrate this nested structure more concretely, let’s look at an example. Imagine a creature whose visual system uses four egocentric reference frames that are arranged such that RF0 is nested within RF1, RF1 is nested within RF2, and RF2 is nested within RF3. I will stipulate that perceived objects are first represented at locations relative to the maximally nested reference frame, RF0; the reason for this will become clear later. When perceived objects are explicitly represented at locations relative to RF0, it remains architecturally encoded. But when its location is specified relative to RF1, RF0 is explicitly represented. This pattern, in which one reference frame is architecturally encoded at one level of the nested structure and explicitly represented in the next, continues, as shown in Fig. 1. The pattern stops with the outermost frame, RF3, which is not explicitly represented because it is not nested within another frame.
Fig. 1
Reference frames in a nested structure. Perceived objects are nested within RF0, RF0 is nested within RF1, RF1 is nested within RF2, and RF2 is nested within RF3
Now, let me outline what the nested structure used in human visual perception might look like. For simplicity, let us assume that only four reference frames are used: the cyclopean reference frame, the head-centered reference frame, the body-centered reference frame, and an allocentric reference frame.Footnote 12 We should expect that the cyclopean frame is nested within the head-centered frame, which is nested within the body-centered frame, which is nested within an allocentric frame.Footnote 13 This is because objects in the environment that are visually perceived are represented relative to the eyes before the head; they are represented relative to the head before the body; and they are represented relative to the body before the environment. In this way, maximally embedded egocentric reference frames are located at the beginning of the visual processing stream; but as processing continues, information is passed to frames that occupy less and less embedded positions. In fact, moving along the processing path critically involves contextualizing incoming information in wider and wider spatial frameworks.
I now turn to consider three lines of support for the Nested Frames View: empirical findings from spatial neglect, robot kinematics, and an analysis of proprioceptive information. Together, these reinforce not only the general idea of a hierarchy of egocentric reference frames in perception but also the specific structure outlined above for human visual perception.
First, studies of spatial neglect reveal error patterns consistent with a hierarchy of reference frames in perception. Before considering the empirical findings, it is helpful to clarify how errors would propagate within such a hierarchy. Given that information flows upward, errors in lower-level reference frames should propagate upward to higher-level frames, but not downward. For instance, using Fig. 1, an error in RF2 should produce errors in RF3, while leaving RF0 and RF1 unaffected. Applied to the hierarchy proposed for human visual perception, errors in the body-centered frame should affect allocentric representations but not head-centered or cyclopean representations.
Empirical evidence supports this prediction. Li et al. (2014) studied patients with left-sided spatial neglect using triangular targets that either contained a gap or were intact. The targets appeared at different positions relative to the patient’s trunk, while the gap’s location varied in allocentric space. Crucially, neglect of gaps on the left of allocentric space was worse when stimuli appeared to the left of the trunk. The authors concluded that ‘not only were allocentric and egocentric biases present simultaneously, but that egocentric information can influence the severity of allocentric neglect’ (p. 166).Footnote 14 Focused on disambiguating between different egocentric reference frames, Karnath et al. (1991) also studied patients with left-sided spatial neglect and found that it was specifically trunk-centered: leftward trunk movements compensated for neglect, while head movements did not. This suggested that the patients’ spatial neglect was localized to their body-centered frame and did not affect their head-centered frame (see also Karnath et al. (1993)).
Taken together, these findings provide empirical grounds for a hierarchical organization of egocentric reference frames used in visual perception. The influence of body-centered errors on allocentric representations, alongside the absence of errors in the head-centered frame, suggests a structure in which the body-centered frame falls between the lower-level head-centered frame and a higher-level allocentric frame. By contrast, a non-hierarchical model appears incompatible with these results. If, for example, the body-centered reference frame were explicitly represented relative to both an allocentric frame and the head-centered frame, it would be difficult to explain why errors in the body-centered frame do not propagate to the head-centered frame.
That said, it is important to recognize that a hierarchical model does not preclude top-down influences from higher-level frames on lower-level ones. Increasing evidence shows that hippocampal information, which encodes an allocentric (or cognitive) map, can modulate early visual processing. As Fernandez Velasco (2024) emphasizes, ‘The classical picture (be it in neuroscience, psychology, or philosophy) of the interaction between the systems in charge of visual processing and spatial location is bottom-up… A wealth of discoveries is now turning this classical picture on its head’ (p. 162). For example, recent studies have demonstrated that V1 neural responses to landmarks are modulated by allocentric information about self-location (Saleem et al. 2018) and that some V1 neurons exhibit stimulus-predictive responses possibly ‘scaffolded’ by hippocampal activity (Fiser et al. 2016, p. 1664). While these findings reveal top-down effects on early visual processing, they do not constitute evidence that higher-level frames systematically alter the spatial positions of objects represented in lower-level frames, which would suggest that reference frames are mutually represented relative to each other rather than nested. Thus, the current findings appear compatible with the Nested Frames View.
A second source of support for a hierarchy of reference frames in perception comes from robotics (see standard robotics textbooks such as Craig (2009) and Siciliano et al. (2008)). In robot kinematics, each of a robot’s links or articulated body parts is assigned its own reference frame. These frames are then arranged hierarchically, with each defined relative to a parent frame. The root of the hierarchy, known as the ‘base frame,’ is typically anchored to the most stable part of the system (e.g. the torso in humanoid robots). Other frames represent links beyond the base that can move given the robot’s joints. Movement is modeled by specifying the spatial relations between each frame and its parent, tracing all the way back to the base frame.
Like robotic systems, biological systems might also use a hierarchy of reference frames because they too must track a hierarchy of physical relations introduced by joints. Consider the relationship between the eyes and head. Physically, the eyes can move while the head remains fixed, but the head cannot move while keeping the absolute position of the eyes fixed. In keeping with computational models in robotics, the nested frames structure I have proposed for visual perception suggests that this asymmetry is mirrored at the representational level: the cyclopean frame can be represented at different positions within the architecturally encoded head-centered frame, but not vice versa. Like the head relative to the eyes, the head-centered reference frame functions as the anchor relative to which the cyclopean reference frame is represented. Given that the asymmetrical relations between body parts continue (e.g. the head moves relative to the torso), we should expect the asymmetrical relations between reference frames to continue, thereby forming a hierarchy.
The use of hierarchical spatial structures like those found in robotics has precedent in other models of perception. Bermúdez (2017) explicitly draws on robotics in developing a model of bodily awareness. He proposes that the human body is represented ‘as a hierarchy of generalized cones linked by mechanical joints’ and anchored to the immovable torso (p. 136). According to his view, a sensation in the hand, for example, is located in a cylindrical coordinate system centered on the wrist that is then located relative to the torso via joint angles at the elbow and shoulder. In this way, a wrist-centered frame is nested within an elbow-centered frame, which is nested within a shoulder-centered frame, which is nested within the torso-centered frame. While Bermúdez uses this kind of hierarchical structure to model spatial representation in interoceptive perception, the Nested Frames View uses it to model spatial representation in exteroceptive perception.
The third and final source of support for the Nested Frames View that I will discuss concerns the proprioceptive information used to track spatial relations between reference frames. I’ll explicate my idea by previewing an example discussed in §4. During gaze shifts, cognition must track object positions relative to the eyes and eye position relative to the head in order to represent visual objects relative to the head (Andersen et al. 1993, pp. 171–173; Briscoe 2021, p. S3926; Grush 2000, p. 68; Zipser & Andersen 1988). Mathematically, representing eye position relative to the head is equivalent to representing head position relative to the eyes. But when we consider the source of this spatial information, a clear asymmetry emerges, one closely related to the asymmetry between body parts. The information used is proprioceptive and derives from eye muscle activity during eye movements (Balslev and Miall 2008; Briscoe 2021, p. S3926; Zipser & Andersen 1988). Thus, this information is best construed as concerning the position of the eyes relative to the head rather than vice versa. This indicates a possible asymmetry between the relevant reference frames, namely, that the cyclopean reference frame is represented at a location relative to the head-centered frame rather than vice versa. More broadly, this suggests a hierarchy of reference frames in which each frame is represented relative to another, mirroring the asymmetric proprioceptive signals that track the spatial relations between body parts.
Beyond providing evidence for a hierarchy, this analysis of proprioceptive information helps highlight a key feature of the Nested Frames View: that some reference frames are explicitly represented, in addition to being architecturally encoded. This likely occurs because our perceptual systems must track the variable relations between different reference frames. We’ve seen, for example, how representing visual objects relative to the head requires tracking both their positions relative to the eyes and the eyes’ position relative to the head. This suggests that the cyclopean reference frame plays two roles: it serves as a frame relative to which objects are represented and as an object represented relative to the head-centered frame. When objects are represented at locations relative to the cyclopean frame, it remains architecturally encoded. As we saw in §2, there is no need for it to be represented. Yet when the eyes shift, downstream parts of cognition must track and compensate for this shift. I propose that at one step higher in the processing stream, the cyclopean frame is now explicitly represented at a location relative to the architecturally encoded head-centered frame. Thus, the cyclopean frame is encoded twice over: first, implicitly, for representing other objects at locations relative to it; second, explicitly, for representing itself relative to another frame. This reflects a broader functional trend: an implicit egocentric reference frame functions as the frame relative to which other objects are represented, while an explicit egocentric reference frame functions as an object that is itself represented relative to another frame.
The dual use of egocentric reference frames mirrors the self’s roles as subject and object of perception. To see this, notice how the functions of the cyclopean reference frame map onto the two roles of the eyes: to perceive and to be perceived. When the cyclopean reference frame is architecturally encoded and used as the frame relative to which objects are represented, it carries information about the eyes in their perceiving role. The eyes are perceiving the objects represented at locations relative to the cyclopean frame. By contrast, when the cyclopean reference frame is explicitly represented at a location relative to another frame, it carries information about the eyes as they are being perceived. In this case, the eyes are objects of proprioception, whose positions relative to the head must be tracked for downstream perceptual processing. Interestingly, even while reflecting the role of the eyes as objects of proprioception, the cyclopean reference frame serves as an input to downstream perceptual processing and so facilitates one’s role as a perceiver. In this way, as a whole, the nested structure of reference frames is marshaled in support of the self’s role as the subject of perception.
The nested structure of egocentric reference frames illustrates how indexical information about the self comes to be explicitly represented in perception. When an egocentric reference frame that is architecturally encoded at one level of the nested structure becomes explicitly represented in the next, the information that it carries is likewise articulated. This follows from my analysis of egocentric reference frames as structures that jointly encode indexical locational information and indexical information about the self (§2).
Another source of support for the idea that explicit representation of an egocentric reference frame entails explicit representation of information about the self comes from consideration of conscious access. The positions of our body parts relative to one another are consciously accessible (Bermúdez 1998, ch. 6; Evans 1982, ch. 7). I can, for example, feel where my eyes are located relative to my head and report on this. Crucially, this feeling is accompanied by a sense of ownership (de Vignemont 2018). When I feel the position of my eyes relative to my head, they feel like my eyes. That something is consciously accessible in this way is generally taken to be indicative of explicit representation. Thus, this consciously accessible sense of ownership provides evidence that when information about eye position is explicitly represented, information about the self – here, information that the eyes are my eyes – is also explicitly represented. More generally, this suggests that information about the self is explicitly represented when egocentric reference frames are so represented.
We can use the nested structure of reference frames proposed earlier to sketch the use of explicit information about the self in human visual perception. The cyclopean reference frame’s nesting within the head-centered frame marks explicit information about one’s eyes, used to specify their position relative to the head. The head-centered reference frame’s nesting within the body-centered frame marks explicit information about one’s head, used to specify its position relative to the body. And the body-centered reference frame’s nesting within an allocentric frame marks explicit information about one’s body, used to specify its position relative to the environment.
In summary, the Nested Frames View proposes that egocentric reference frames are hierarchically organized such that they can be both architecturally encoded and explicitly represented depending on their role. I have provided support for this hierarchical organization using studies of spatial neglect, robot kinematics, and an analysis of proprioceptive information. Crucially, the view entails that when an egocentric reference frame moves from being architecturally encoded at one level to being explicitly represented at the next, the indexical information about the self that it carries likewise becomes articulated. I now turn to argue that the Nested Frames View is well-suited to describe two phenomena in human perception.
Comments (0)