
Remember me

In a clinical trial, patient data is typically collected as repeated measures over time, tracking pivotal health measurements of all patients during the course of a trial. As patients can enter the trial at different times and thus the individual length of each time series depends on the time that has passed since enrollment. The number of data points collected depends on how often a measurement was collected and may contain missing values when assessments have been skipped. The actual values measured may also depend on scheduled treatments and assessment as well as on disease progression. All these factors complicate active SDM of ongoing trials. CTAS has been developed to only compare time series composed of the same time points. It will actively comb through the data and find as many groups of timeseries of equal length that fulfill a set of parametrized minimum requirements. Detailed parameter descriptions can be found in the project’s public code repository (see Supplementary Information). Alternatively, time series can also be defined manually to include fixed sets of visits. CTAS expects measurements to be numerical, thus any categorical values need to be transformed to an appropriate numerical format. CTAS will then calculate a set of relevant aggregate features for each time series which can then be used to identify site and subject outliers.
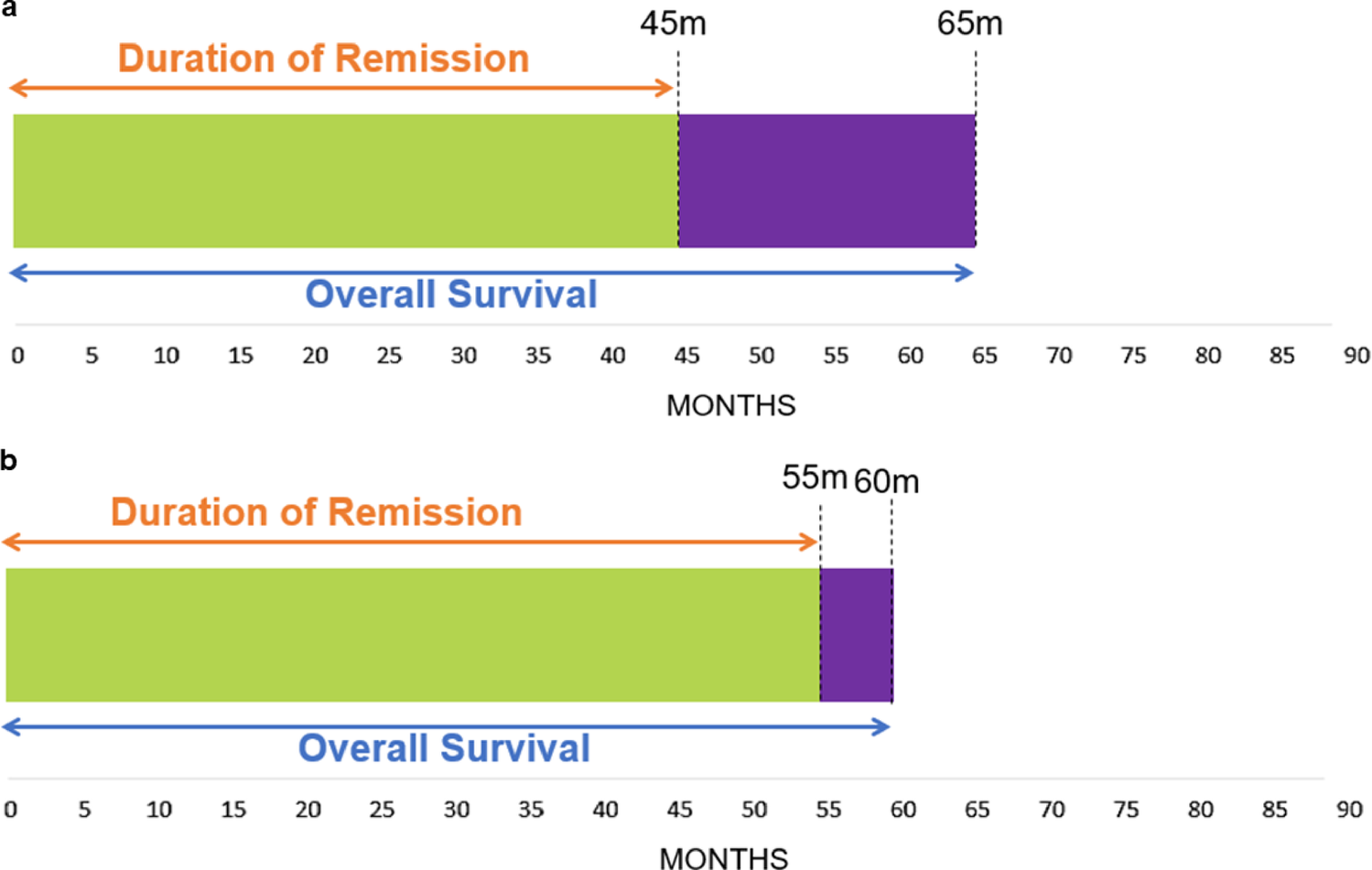
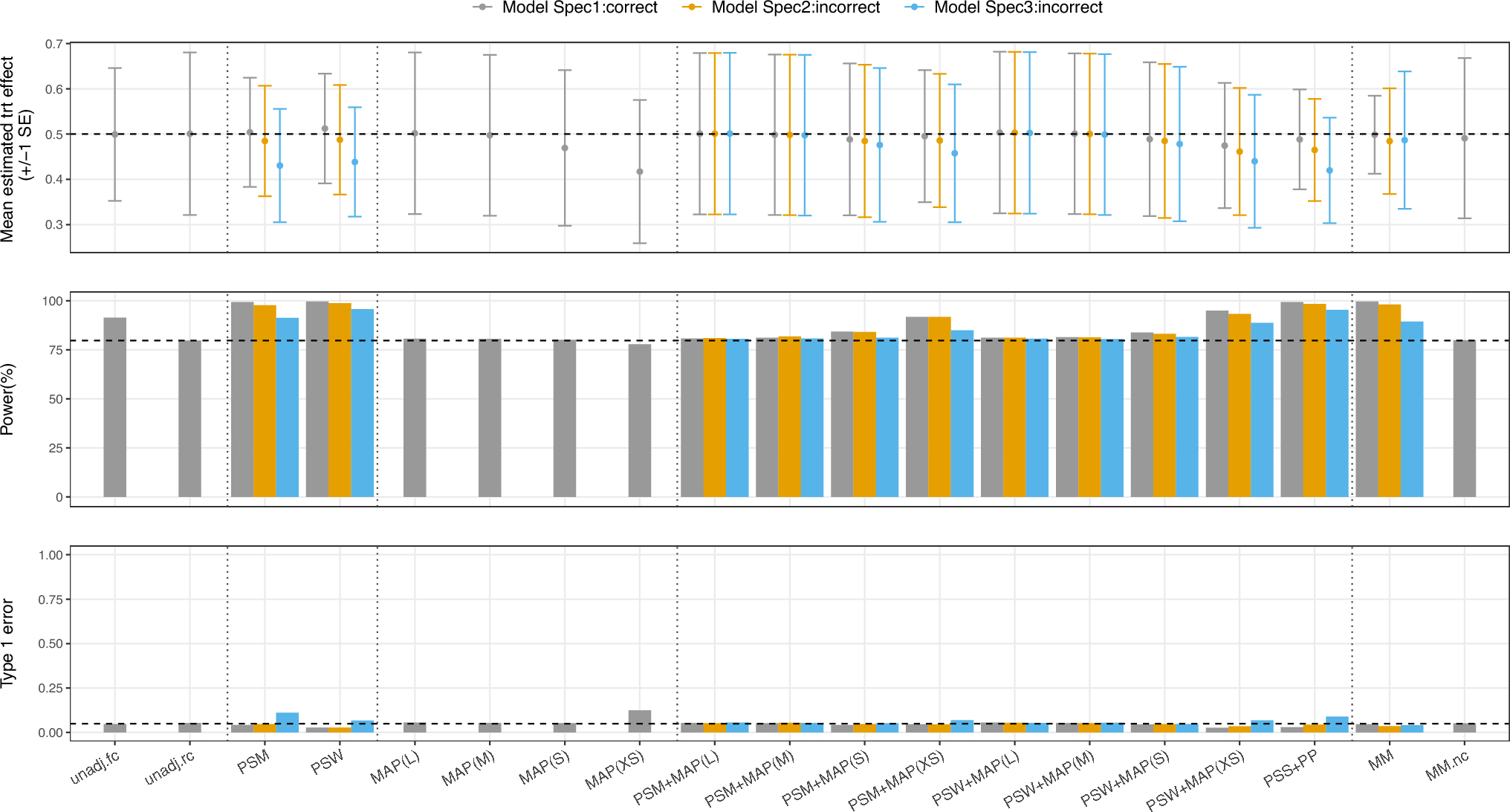
Defining Time SeriesIn an ongoing study, some subjects might have only taken the first visits while some have already finished the study. For this reason, more than one group of time series with various lengths per parameter should be defined. One group would include almost all planned time points and compares subjects which have largely finished the trial. Another shorter group includes only the first few visits to also include subjects which have been recently enrolled. As illustrated in Fig. 1 individual subject data points may also be missing. These time series groups can be manually defined or CTAS will start to iteratively look for suitable groups starting with the longest possible group and decrease the length if the number of eligible subjects can be increased by at least 20 percent. Regardless of whether timeseries groups are defined manually or automatically timeseries groups of different length will be evaluated simultaneously by CTAS to balance length and the number of patients. Figure 1 illustrates two timeseries groups TS1 with 3 patients of length 8 and TS4 with 6 patients of length 4. A time series group should have a minimum group size which can be set via a CTAS parameter, we currently recommend a minimum group size of 25 subjects. Eligible subjects must also not exceed the maximum ratio of missing values, which is another CTAS parameter for which the recommendation is 30%. Traditionally, time series should have at least three data points, however some measurements will only be taken once possibly during screening. Therefore, CTAS also allows time series of length one, although not all subsequent time series features e.g. autocorrelation (see the following section) will be meaningful.
Fig. 1
Simplified example of time series group definitions. Blue cells denote subjects with a measurement at a given time point. Two time series groups have been defined. TS1 includes subjects (S1–S3) which have finished the study TS2 focuses on the first four time points and includes also subjects S4-S6 in addition to those in the TS1. Remaining subjects have data for too few time points to be considered in either of the time series groups
Timeseries FeaturesEach time series is characterized by a set of time series features, which summarize the measurements of a time series into a single metric. These features are central to the algorithm as they are used to flag anomalous sites (see below). In addition, the features can be used to identify individual subjects with peculiar time series. Available time series features are listed in Table 1.
Table 1 Time series featuresAll feature types except LOF (local outlier factor) [6] are context-free meaning that only measurements in the time series are needed to calculate them. LOF on the other hand is context dependent as its value depends also on the other time series in the study.
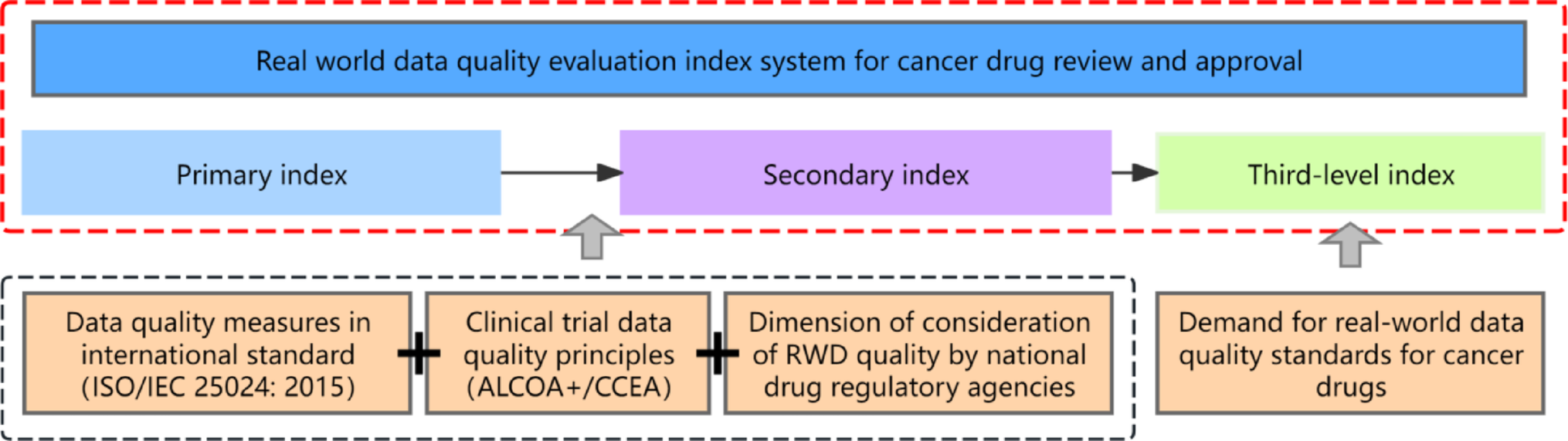
For an illustration of features for a time series, please see Fig. 2.
Fig. 2
Example of a time series with four time points and the features calculated from it. The context-free features can be calculated by using the data in the time series itself. In contrast, Local Outlier Factor (LOF) are context-dependent, and its value depends on the time series of other subjects in the study
Flagging SitesFlagging sites with a systematic bias in their data collection is an important part of study monitoring. If identified early enough, the site can be offered further training if the site has had trouble in interpreting the study protocol. In the extreme case, if the bias is due to intentional misconduct, the site can be closed and excluded from analysis.
Sites are flagged based on the bias in their time series feature values versus other sites in the study. CTAS offers three options for flagging sites: Kolmogorov–Smirnov, mixed effects modelling and the simple average of the feature values. P-values derived from those methods are corrected for multiplicity using the Benjamini Yekutieli correction accounting for interdependency between samples as data is reused between control groups [7]. The negative logarithm of the corrected p-values provides the CTAS score which is provided for every timeseries feature and time series group. We used the maximum score from all predefined or autogenerated time series groups with a threshold of 1.3 (p-value: ~ 0.05) to flag site outliers.
Kolmogorov–SmirnovThe Kolmogorov–Smirnov (K-S) statistical test compares time series feature values of individual sites against the combined values from all other sites. This non-parametric test evaluates the null hypothesis that the feature values from a specific site and the feature values from all other sites are drawn from the same distribution [8].
The K-S test calculates the maximum difference between the empirical cumulative distribution functions (ECDFs) of the two samples, providing a D-statistic and a p-value for each comparison. The p-value indicates the significance of the difference between the distributions. A low p-value suggests that the feature values from the site are significantly different to those from other sites, potentially indicating an anomaly.
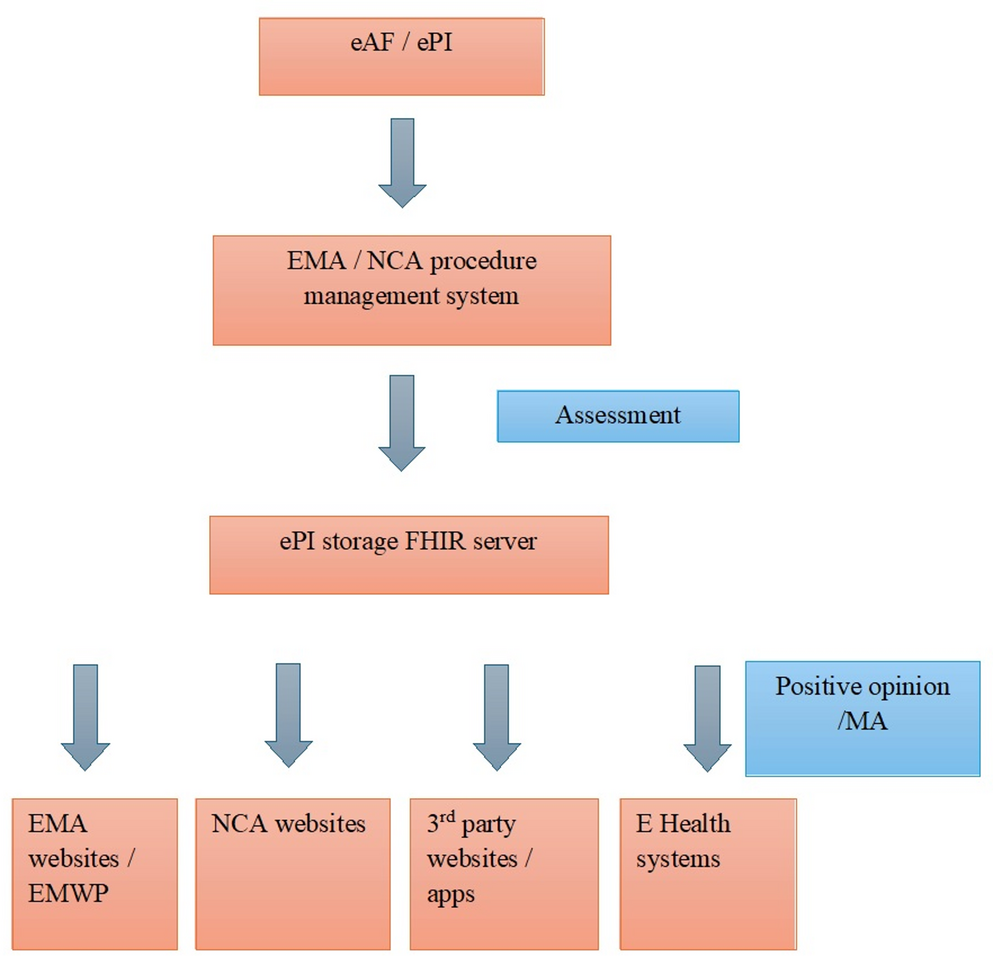
Figure 3 gives an example on how the method is used to identify a site with few unique values per time series.
Fig. 3
Example of site flagging. The timeseries has eight time points and the question is whether the site (six subjects) has reported fewer unique values per time series than other sites in the study. Part (1) has the individual subject time series and the unique value counts. It is clear from the histograms (2) that the site is biased when compared to other sites. To quantify the bias, the distributions are compared with the Kolmogorov–Smirnov test (3) which gives us a raw p-value. As we perform several tests per study, the p-value must be corrected (4). Finally, the negative logarithm of the corrected p-value is taken to come up with the final score for the site (5)
Mixed Effects ModellingThis approach allows us to account for both fixed and random effects in the data, providing a robust framework for detecting anomalies.
We fit a mixed effects model to the data, where the hierarchical structure of the data is taken into account by including random effects for different levels (i.e. sites nested within countries and regions). After fitting the model, we simulate the random effects to obtain estimates for each entity (sites, countries, and regions). For each entity, we calculate the median and standard deviation of the random effects. Consequently, the median and standard deviation are used to calculate a p-value for each entity’s deviation from zero, providing a statistical measure of the significance of the anomaly.
Average Feature ValueAs a simple baseline model for anomaly detection, we also scored sites based on the average feature values of the subjects at each site. Then outliers were defined as being outside of the interquartile range multiplied by 1.5 [9]. This straightforward approach involves calculating the mean feature value for each site and using these averages to identify potential anomalies. It is included to have a benchmark to see if the more complex site flagging methods are able to outperform it. Note that the method does not produce a p-value but a binary outcome on whether the site is an outlier or not.
The primary advantage of this method is its simplicity and ease of understanding. It provides a clear and straightforward way to identify sites with unusual feature values. However, this approach does not take into account the size of the site. A site with only one subject who has an extreme feature value may get flagged, even though this could be due to chance alone and may not indicate a systematic issue with the site.
Identifying Anomalies in Subject-Level Time SeriesIn addition to flagging sites, the results are valuable for identifying individual subjects with anomalous time series. Sites which exhibit no systematic bias might still contain individual anomalous subjects and time series. One way is to visually inspect similarity plots for subjects with few near neighbors. Figure 4 gives an example of a subject-level outlier with an anomalous weight profile. Another approach is to compare time series features and review subject time series with extreme values for one or more features. Please see Fig. 5 for an example. Note that outliers identified with the two approaches often correlate, e.g. subjects with unusually high standard deviations also tend to be outliers on the similarity plot.
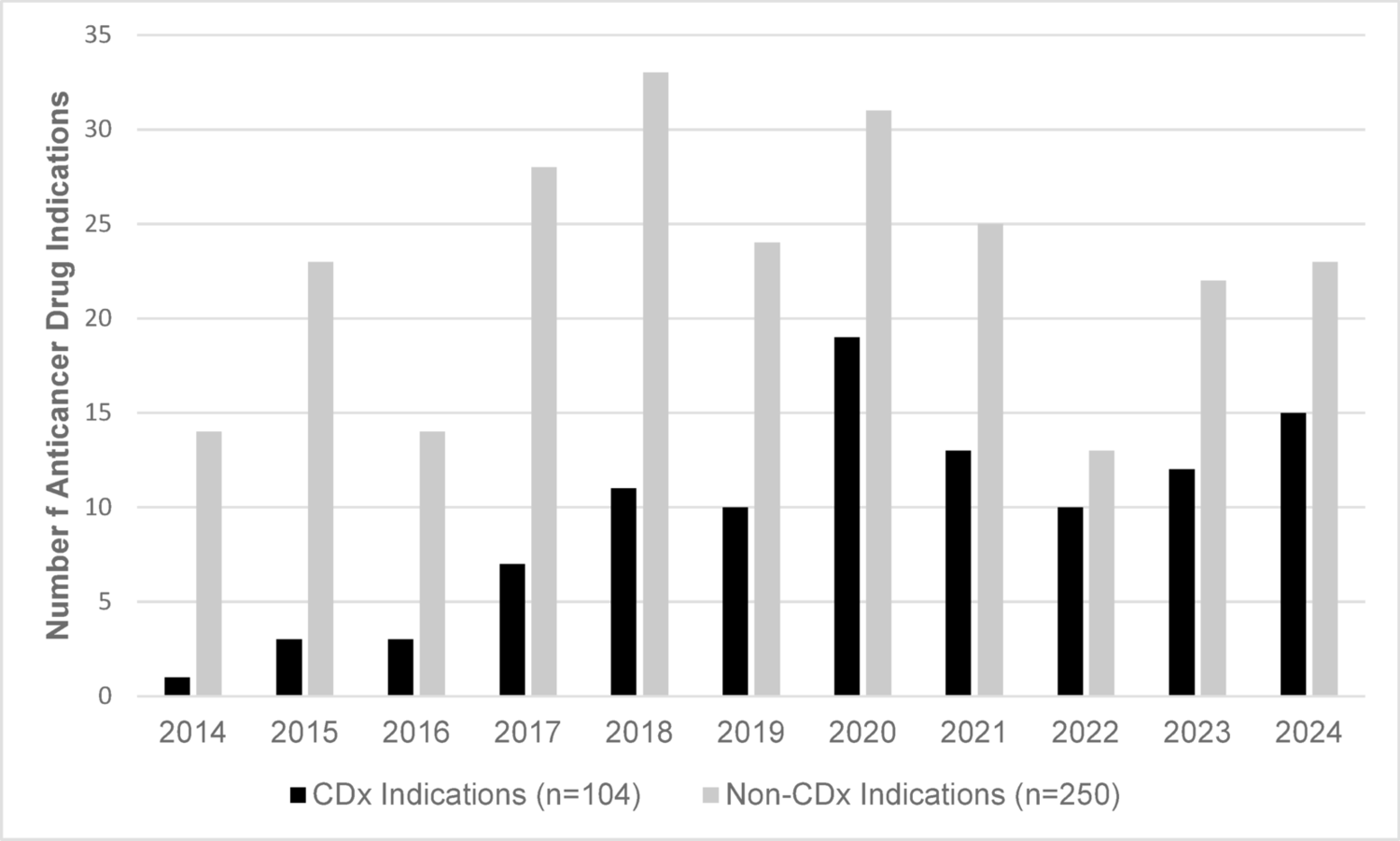
Fig. 4
An anomalous weight profile identified based on its distance from other profiles on the similarity plot (left). The profile is given on the right with a sudden drop in weight followed by a return to the previous values. In this case, the reason is probably a data entry error at site
Fig. 5
Identifying an individual time series outlier based on a time series feature. In this case the subject with most variable bilirubin profile (1) has been selected and highlighted with the other subjects (2). In this case, it is possible that the site has collected the data correctly, but this might be interesting for someone performing medical review to identify safety issues, for example
ValidationThe primary goal of the evaluation is to demonstrate CTAS performance to detect outliers of varying degrees in a clinical trial data set using the different statistical methods offered by CTAS (mixed effect modelling, K-S, or average feature value) for flagging site-level outlier. Secondarily, we check whether CTAS is suitable for different types of clinical time series measurements: two laboratory (Alanine Aminotransferase, Creatinine) and two vital sign measurements (Systolic Blood Pressure, Weight). We created test data sets from clinical trial data sets from which we removed potentially preexisting site-specific signal as well as regional and country-specific effects by reassigning all patients to different sites.
Further we removed data points from unscheduled visits and data from screening failures. A total of 15 completed studies were selected from 3 different IMPALA members. These studies were divided into groups of three studies with each group having comparable numbers of patients and sites.
In order to simulate detectable anomalies, we randomly selected three sites to which we applied the following transformations:
Average: Add the site mean multiplied by the anomaly degree to original values.
Standard Deviation: Add site mean multiplied with the anomaly degree to each observation and randomly apply a negative or positive fore-sign.
Range: Add one outlier data point per patient. The extremity of the outlier is based on the anomaly degree.
Unique Value Ratio: Replace a ratio of observations with the first observed value per patient. The ratio would be determined by the anomaly degree.
Autocorrelation: Add the preceding value multiplied by the anomaly degree to each value.
Local outlier factor: Transform data for each patient by a randomly chosen non-normal distribution. The anomaly degree would determine the ratio of affected patients.
The anomalies introduced are visualized in Fig. 6 based on a simulated Standard Data Tabulation Model (SDTM) test data set [10]. These anomalies pair with the time series features that are measured by CTAS and listed in Table 1 which also gives examples of how they might occur in a clinical trial setting. The simulated anomalies mimic these events to different degrees.
Fig. 6
Examples of simulated site-level anomalies (for Alkaline Phosphatase) of varying degree across different anomaly types based on a simulated test data set. Timelines from regular sites are shown in grey and timelines from anomalous sites in red
Subsequently we tried to detect the three anomalous sites using different site scoring methods among the compliant sites in the study data set. We set the minimum time series length to one and required at least 25 patients per time series group with a maximum ratio of missing values of 30% per subject. For each combination of a site, parameter and feature, we took the highest CTAS score, across all potential time series groups and employed a threshold of 1.3 (p-value: ~ 0.05). This was repeated a 100 times and true positive rate (TPR) and false positive rate (FPR) were calculated using the combined results.
Comments (0)