
Remember me

A narrative search engine with query suggestions was built for searching case narratives from case series in VigiBase, the World Health Organization global database of adverse event reports for medicines and vaccines. The search engine takes a series of case narratives and a query, which can consist of one or multiple search terms, and returns a ranked list of case narratives that are considered relevant to the search query. Additional query terms are suggested and presented for potential inclusion to the original search query.
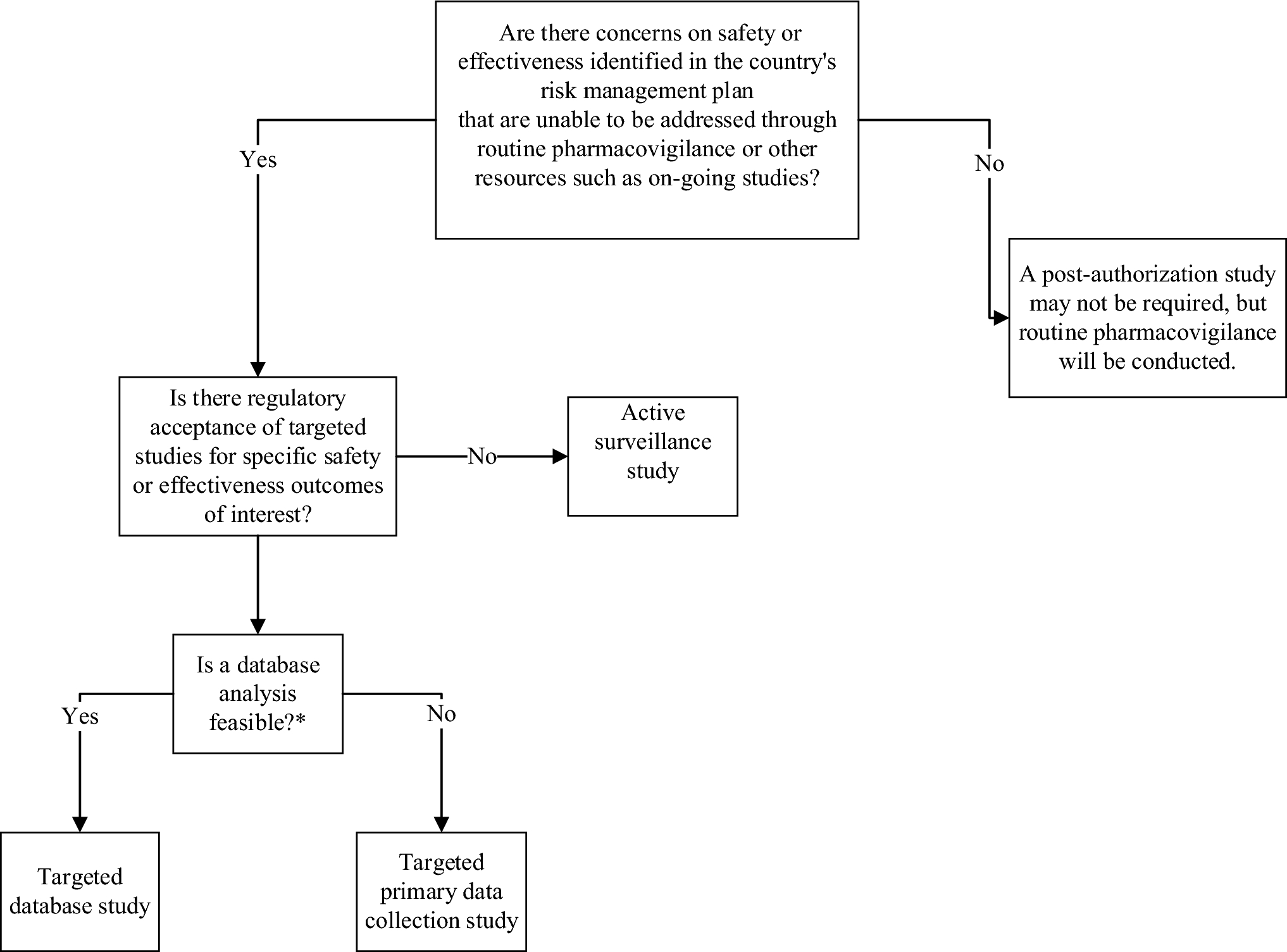
For an overview of this setup, see Fig. 1.
Fig. 1
Overview of the search engine supported by query suggestions
2.1 Narrative Search EngineThe narrative search engine uses BM25 [15] as its search method and applies stemming to the search query terms (e.g. “exercise”, “exercising” and “exercises” are all stemmed to “exercis”). To enhance search results and to support the user in refining the search, the narrative search engine provides query suggestions, recommending other terms that are similar to the original query terms. The user may add any number of the suggested query terms to the initial search, forming queries such as “workout training exercise” to look for case narratives containing one or a multiple of these words. In practice, this can be an iterative process of adding and removing query terms depending on the search results.
The suggested query terms are based on the meaning of the terms already included in the query. Similar terms are suggested per query term, and two different sets of suggestions are made using underlying word embedding models: a Global Vectors for Word Representation (GloVe) model [26] for general English text (with 300-dimensional embeddings) and a word2vec model [27] trained on biomedical literature (with 200-dimensional embeddings). Word2vec is a neural-network-based model that learns vector representations of words by predicting surrounding words, while GloVe is a model that generates word embeddings by leveraging word co-occurrence statistics from a large corpus. Both are relatively small models, making them computationally efficient. The reason for using two different word embedding models is that they may complement each other. For example, for “exercise”, the general English model could be more appropriate, while for medical terms such as “fever”, the biomedical one could be more helpful. We did not choose contextual embeddings such as those derived from BERT, since these rely on context, and we expected queries to often only contain single words without any context. These embeddings are also larger and the cost–benefit considerations were not favourable for their use. For general language, both word2vec and GloVe have shown good performance on word analogy datasets, word2vec in particular on word similarity datasets [28]. Another advantage of using GloVe was its availability within the spaCy python package.
Not only are the suggested query terms semantically related to the original query terms, but they are also filtered to include only words that appear in the narratives of the case series. This helps the user build the best query for the given case series.
In summary, throughout this process, each word embedding model recommends ten terms for each search term, not already present in the search query. All suggested terms are words present in the narratives. The suggested terms are ordered on the basis of their similarity to the original search term. There is no stipulated minimum similarity requirement, and thus, no threshold is applied.
Figure 2 presents how the query suggestions may be presented in a user interface.
Fig. 2
Query suggestions for the search query “exercise” on a case series used during development (built using the streamlit python package)
2.2 Evaluation DataTo systematically assess the performance of search engines, one can use evaluation datasets. These consist of a set of query topics that cover a range of themes that users might search for, a collection of texts and relevance judgements. The relevance judgements are the manual annotations for query topic–text pairs indicating whether the text is relevant for the topic. Evaluation metrics then compare the search engine output, i.e., a list of texts retrieved and ranked according to relevance by the search engine, to the evaluation dataset’s relevance judgements.
For the evaluation of the narrative search engine, we created an evaluation dataset from COVID-19 vaccine case series in VigiBase. We chose to focus on COVID-19 vaccine reports since the narrative search engine was originally developed to address the challenge of an unprecedented increase in reports of adverse events following immunisation related to COVID-19 vaccination campaigns.
We selected five COVID-19 vaccine case series on the basis of the European Medicines Agency’s public listing of safety signals discussed at the Pharmacovigilance Risk Assessment Committee. The COVID-19 vaccine case series selected were the adverse events heavy menstrual bleeding, myocarditis, erythema multiforme, deep vein thrombosis and myositis. We sampled 150 narratives for each of the case series, resulting in 750 annotated narratives in total.
Each case narrative in the evaluation dataset was independently annotated by two experienced pharmacovigilance assessors. The experts evaluated each case narrative to determine its relevance to a predefined search topic. Each case narrative was assigned one label as defined in Table 1. Disagreements between the annotators were discussed and joint decisions were made.
Table 1 Label assigned during manual annotation of the datasetThe following topics were chosen for annotation of the COVID-19 case series:
For the adverse event heavy menstrual bleeding, the topic “ability to work”, which represents a qualifier of the event, indicating its impact on quality of life;
For the adverse event myocarditis, the topic “autoimmune disease”, which represents a potential alternative cause for the event;
For the adverse event erythema multiforme, the topic “oral lesions”, which represents a key diagnostic symptom of the event;
For the adverse event deep vein thrombosis, the topic “cancer”, which represents a risk factor for the event;
For the adverse event myositis, the topic “dysphagia”, which represents a qualifier of the event, indicating the severity of the event.
These topics represent alternative causes, risk factors and other subsets of the case narratives, each with an evidence-based association to the respective adverse event. In the selection of the topics, we also made an informal estimate of their prevalence in the case narratives on the basis of clinical expertise and aimed to strike a prevalence balance. Specifically, we wanted to select topics that were likely to appear in the case narratives but not so prevalent that they would not require a search engine.
The final annotated evaluation dataset included 55 relevant narratives: heavy menstrual bleeding and ability to work with 6% relevant case narratives, myocarditis and autoimmune diseases with 4%, erythema multiforme and oral lesions with 16%, deep vein thrombosis and cancer with 7% and myositis and dysphagia with 3%.
Inter-annotator agreement was measured to evaluate their agreement during the creation of the evaluation dataset using Cohen’s kappa [29]. The overall Cohen’s kappa score for the evaluation dataset annotations was 0.64, which can be considered moderate agreement [29]. However, inter-annotator agreement varied between case series with a Cohen’s kappa score ranging from 0.39 (minimal agreement) for heavy menstrual bleeding to 0.81 (strong agreement) for erythema multiforme.
To evaluate the search engine and test how well it retrieves relevant case narratives, we needed concrete search queries for the annotated topics. The search queries serve as the input made to the narrative search engine, simulating real-world user interactions.
For the query selection, a medical assessor who had not seen the case narratives of the COVID-19 vaccine case series defined three single-word queries for each topic. This search query definition was based on experience from working with different case series, which would reflect of a pharmacovigilance assessor’s workflow. Single-word queries were chosen to facilitate comparison between different models.Footnote 1
The search queries, which should not be seen as complete definitions of the topics, were as follows:
for the topic ability to work the queries “work”, “job” and “leave”;
for the topic autoimmune disease the queries “autoimmune”, “lupus” and “rheumatoid”;
for the topic oral lesions the queries “lip”, “oral” and “mouth”;
for the topic cancer the queries “cancer”, “metastasis” and “malignant”;
for the topic dysphagia the queries “dysphagia”, “swallowing” and “choking”.
2.3 EvaluationsRelevance-based metrics, such as recall and precision, are most commonly used when evaluating the retrieval performance of information retrieval systems. These metrics quantify the number of relevant texts retrieved during a search. Recall is the proportion of relevant texts retrieved in the search and answers the question “what fraction of the relevant texts was retrieved?”:
Precision is the proportion of texts retrieved in the search that were relevant. In other words, precision answers the question “what fraction of the retrieved texts were relevant?”:
These metrics do not account for the ranking of the retrieved texts and do not capture the real-life search experience of the user, who will likely read the list of retrieved texts from top to bottom. A user reading the list in a sequential order might stop reading after a certain number of texts, particularly when many of the top-ranked results are not relevant. It is therefore desirable to have quality ranking with the most relevant texts on top.
In this study, we used recall and precision for retrieval evaluation and evaluated the ranking quality by manually examining visualisations of the rankings in so called rank–recall curves. These curves present the recall at every position in the ranked list (see Fig. 3 in the Results section for an example). From these curves, it is possible to visually compare two rankings to see how recall differs at various positions in the ranked list. Depending on the use case, different rankings might be preferable.
Fig. 3
Rank–recall curves for COVID-19 vaccine and (a) deep vein thrombosis with topic cancer and query cancer, (b) myocarditis with topic autoimmune disease and query rheumatoid, (c) erythema multiforme with topic oral lesions and query oral and (d) heavy menstrual bleeding with topic ability to work and query work. The rank–recall curves show the recall (proportion of all relevant narratives that were retrieved by the method) at every rank in the ranked list returned by the method. The “x” indicates the rank of the last document, i.e., the number of retrieved documents (x-axis) and the overall recall of that method (y-axis). Since none of the methods retrieved more than 50 cases, the x-axis is cut off at 50 instead of 150
2.3.1 Retrieval Performance EvaluationWe evaluated the narratives retrieved by the search engine after a human selection of additional query terms from the search engine’s suggestions. For each of the search queries defined above, the narrative search engine’s word embedding models produced 10 query suggestions, resulting in a total of 20 query suggestions. From those, a domain expert had the option to select and add any number of terms (0–20) to the query. For this experiment, the selection was done blindly without access to the narratives. We refer to this system as “BM25+ QS + Human”, where “QS” stands for “query suggestion”.
For comparison, we used an exact-match search as a baseline method and BM25 with RM3, a commonly used query expansion method and available off-the-shelf, as a benchmark. In exact-match search, the system retrieves results that precisely match the provided search term, ignoring any word boundaries. RM3 performs automatic query expansions without the use of an external word embedding model for semantic meaning when choosing additional query terms. Instead, it uses a relevance-based language model [18], that expands the original query on the basis of term frequencies within the narratives retrieved by the initial query. We refer to this system as “BM25 + RM3”.
We computed the recall and precision of the systems by running each query separately and averaging the true positive, false positive, true negative and false negative counts (classification outcomes) over the three queries per topic. This simulates a setting in which the user runs only one query. We then computed recall and precision as a micro averageFootnote 2 over all case narratives from the five topics. Using micro averages makes it possible to perform significance testing. To assess whether observed differences were unlikely to be due to random chance, we performed a McNemar test [30] for the recall and a weighted generalised score statistic test for the precision [31], using a significance level of 0.05. For these calculations we created the required confusion matrices per query and averaged the cells across these matrices and rounded to whole numbers to obtain a single confusion matrixFootnote 3 used to perform the significance tests. As the aim of the evaluation was to provide initial results on the performance on a limited number of topics, we refrain from adjustments for multiple testing; i.e., the study should be interpreted as hypothesis-generating.
We also computed the recall when combining retrieved narratives for all three queries per topic, i.e., using the union of the retrieved narratives. This simulates a setting in which a user runs three queries and combines the results.
2.3.2 Analysis of RankingsThe quality of the ranking of case narratives was analysed by plotting the results per query as rank–recall curves for the 15 queries and manually examining the ranking visualisations.
2.3.3 Analysis of Query SuggestionsTo analyse the query suggestions, we manually examined the suggestions from the word embedding models and the choices made by the domain expert and compared them to the automatically expanded terms according to RM3.
2.3.4 Error AnalysisWe performed manual error analysis to get an in-depth understanding of the performance. We manually inspected the relevant narratives not retrieved by the methods (false negatives) and the narratives retrieved by the method but not manually annotated as relevant (false positives).
2.3.5 Computational EfficiencyTo compute computational efficiency, we computed the time it took the search engine to index each case series with 150 narratives and how long it took to search for a query while at the same time computing the query suggestions.
2.4 Implementation and Hyperparameter SelectionThe narrative search engine was built using the Apache Lucene open-source search engine software library through the python package Pyserini [32] version 0.18.0. We used Pyserini to perform tokenisation and stemming using the Porter stemmer [33] with Lucene and to apply BM25 during search.
For the query suggestions, we used the open-source natural language processing library spaCy to implement the word embeddings and scikit-learn’s NearestNeighbors class to find the ten nearest neighbours in the vector space using cosine similarity. We use spaCy’s GloVe model for general English text, en_core_web_lg version 3.4.1, and scispaCy’s word2vec model trained on biomedical literature, en_core_sci_lg version 0.5.1.
As with BM25, we implemented RM3 using Pyserini. We expanded with up to three terms identified by RM3 from the top ten BM25-retrieved narratives and set the weight for the original query term to 0.5.
For the evaluation, we used our own implementation of recall and precision. The recall values used for the rank–recall curves were calculated using the python package ir_measures version 0.3.1.
Comments (0)