
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Remember me
Objective. Wearable biosignal-based hand gesture recognition is a key enabling technology for prosthetic hand control, but its reliability is often affected by limb-position variability and other real-world confounding factors. This study aims to systematically compare dual-path temporal fusion architectures for co-located surface electromyography (sEMG) and pressure-based force myography (pFMG), with emphasis on robustness, computational efficiency, and interpretability under conditions relevant to practical prosthetic use. Approach. Three dual-path fusion temporal convolutional network (DFF-TCN) architectures were structured and investigated to integrate sEMG and pFMG using different fusion strategies: (1) a baseline concatenation-based model combining decision-level (DL) and feature-level (FL) fusion, (2) a DL cross-attention variant, and (3) a FL cross-attention variant. All models were evaluated under identical training and testing protocols using a custom dataset collected from ten participants performing nine functional hand gestures across multiple static and dynamic arm positions. Main results. Across all evaluated conditions, the concatenation-based DFF-TCN achieved balanced performance, with a mean classification accuracy of 95.88%, while the attention-based variants achieved accuracies of 90.65% and 94.02%, respectively. Computational profiling showed that the concatenation-based model also achieved the lowest inference latency (1.70 ms), indicating suitability for real-time deployment. Explainable artificial intelligence analysis using integrated gradients revealed complementary contributions from sEMG (54.08%) and pFMG (45.92%), with contribution patterns varying across gestures and subjects. Significance. The results demonstrate that different fusion strategies offer distinct trade-offs between recognition performance, computational cost, and robustness. In particular, the concatenation-based model provides a favorable balance for real-time prosthetic hand control, while attention-based variants offer additional modeling flexibility. These findings provide practical guidance for selecting multi-modal fusion architectures in wearable human–machine interface systems and support the continued use of co-located sEMG-pFMG sensing in prosthetic and rehabilitation applications.
Export citation and abstractBibTeXRIS
Hand gesture recognition (HGR) serves as a crucial component of wearable human–machine interface (HMI) systems, enabling intuitive and non-verbal communication between humans and machines [1, 2]. Such systems are increasingly adopted in applications ranging from prosthetic hand control to immersive interactions in virtual and augmented reality. To ensure reliable performance in these scenarios, signal acquisition and processing techniques must accurately capture the dynamics of human motor intention [2, 3].
A persistent challenge for HGR is achieving robustness under real-world conditions, where biosignal variability often degrades recognition accuracy [4, 5]. A major source of performance degradation is the limb position effect, whereby variations in arm posture alter the spatial relationship between muscles and sensors, producing distinct signal patterns for the same gesture [4]. This phenomenon has been shown to significantly reduce system performance, highlighting the need for more resilient sensing strategies and fusion frameworks.
Surface electromyography (sEMG) has been widely used for HGR due to its ability to capture electrical activity of motor units in a non-invasive manner [6]. However, sEMG is prone to noise, electrode shift, and skin impedance variability, which limit its robustness. Pressure-based force myography (pFMG), which measures mechanical deformation of soft tissues during muscle contraction, offers complementary advantages: it is less sensitive to electrical noise and does not require direct skin contact [2, 7]. Combining sEMG and pFMG can therefore provide a richer neuromuscular representation by integrating electrical and mechanical perspectives of muscle activation. Recent studies confirm that multimodal fusion improves accuracy and robustness in HGR tasks [8, 9].
Although attention mechanisms have been increasingly adopted in wearable HMI systems and have shown promising results [10, 11], their associated limitations, such as increased architectural complexity and computational cost, are also well recognized. These limitations formed an important part of the motivation for this study. Few studies have explored whether the increased complexity introduced by attention mechanisms is always worthwhile, particularly for wearable applications where data availability and computational resources are limited. As a result, the question of whether attention improves multi-modal temporal fusion in limb-position-variant HGR remains open. Motivated by this consideration, we conducted a systematic investigation of three dual-path temporal fusion variants based on a lightweight temporal convolutional network (TCN). The baseline employs simple concatenation of FL and decision-level (DL) pathways, while two variants introduce cross-attention at different fusion stages. This comparative design allows us to evaluate the trade-offs between architectural simplicity and the potential benefits of attention mechanisms in multi-modal gesture recognition under limb position variation. The goal is not to propose a new architecture, but to understand how attention influences multi-modal fusion performance, robustness, and computational efficiency.
Furthermore, classification accuracy alone is insufficient to fully assess multi-modal frameworks. Equally important is understanding how each modality contributes to the final decision, as this insight not only guides sensor placement and hardware design, but also informs the choice of learning architectures and fusion strategies. In practice, effective wearable HMI systems require the co-optimization of sensing hardware and algorithms, since the relative importance of sEMG and pFMG can vary depending on both the user and the task. By jointly considering modality contributions from both perspectives, researchers can better design systems that are robust, efficient, and adaptable to real-world conditions. To this end, explainable artificial intelligence (XAI) techniques are applied, specifically the integrated gradients (IGs) method [12], to quantify the relative contributions of sEMG and pFMG within the DFF-TCN. This analysis highlights the complementary roles of sEMG and pFMG across gestures and subjects, offering practical guidance for building robust, efficient, and adaptable multi-modal HMI systems.
The central objective of this study is to systematically examine how different dual-path temporal fusion strategies influence the performance of multi-modal HGR systems under limb-position variability. By systematically comparing different fusion strategies under controlled conditions, we aim to understand not only the resulting recognition performance, but also how architectural choices affect robustness, computational efficiency, and interpretability. The main contributions of this work can be summarized as follows:
Comprehensive evaluation of three dual-path architectures: we present a controlled comparison of three dual-path temporal fusion architectures within a unified modeling framework: a baseline DFF-TCN with FL and DL concatenation, and two DFF-TCN variants incorporating cross-attention at either the DL or the FL. All models are trained and tested under identical conditions using co-located sEMG and pFMG signals collected across both static and dynamic arm positions. This ensures a fair evaluation of how attention mechanisms influence HGR performance, particularly under limb position variability.Computational profiling for practical deployment: we provide detailed computational profiling of all models, including parameter counts, floating-point operations, inference latency, and peak memory usage. These results highlight differences between architectural complexity and real-world performance, showing how additional attention layers affect speed and efficiency. Such profiling is critical for wearable HMI applications, where real-time performance and lightweight execution on embedded hardware are often necessary. Our findings highlight how architectural complexity translates into actual runtime performance and resource demands, offering practical guidance for different deployment contexts.Explainable analysis of modality contributions: we employ XAI techniques to interpret how each modality contributes to classification. Using IG, we quantify the relative contributions of sEMG and pFMG across gestures and subjects. The results reveal how electrical and mechanical signals play complementary roles in gesture recognition, and how their importance varies depending on the task and the user.sEMG has historically been the dominant signal source for HGR because it directly reflects motor unit action potentials that precede visible movement [6]. Its fine temporal resolution enables the capture of subtle neural activation patterns, making it an attractive modality for prosthetic and rehabilitation applications [13]. However, sEMG is inherently stochastic, with high variability across sessions and individuals [14]. Issues such as electrode displacement, skin impedance fluctuations, perspiration, and external electrical noise can reduce signal reliability and, in turn, degrade classification accuracy [15]. To improve robustness, inertial measurement units (IMUs) are frequently fused with sEMG as IMUs provide stable kinematic cues and have shown strong recognition performance in practice [16, 17]. However, IMUs offer limited predictive information about user intent when used alone. This has motivated interest in mechanical sensing as complementary or alternative sources of information. Force myography measures volumetric changes in muscle and surrounding tissues during contraction [2]. Its pressure-based variant, pFMG, is particularly suited to wearable systems, as it can be implemented using soft chambers or sensors that do not require direct skin contact [9]. Compared to sEMG, pFMG signals exhibit higher signal-to-noise ratio (SNR) ratios and show greater robustness to electrode-skin interface issues [9]. Recent developments in co-located hybrid sEMG-pFMG armbands have demonstrated that combining electrical and mechanical modalities leads to higher recognition accuracy and system robustness than using either modality alone [5, 9]. This hybrid approach provides a richer description of neuromuscular activity by capturing both electrical excitation and mechanical output.
This growing emphasis on hybrid systems has underscored the critical role of multi-modal fusion in advancing HGR research. Fusion strategies can be applied at multiple levels: data-, FL, and DL [2]. At the data-level fusion, raw sensor data from multiple sources are combined before any processing. FL fusion extracts features from each modality before combining them into a high-dimensional feature vector [18]. DL fusion combines the outputs from separate classifiers, each trained on a different modality [19]. Among these, FL fusion is widely used in wearable systems, as it balances information richness with computational efficiency [18]. Nevertheless, developing effective data fusion architectures that leverage the complementary strengths of multiple sensing modalities remains a key research challenge in multi-modal systems.
Historically, early HGR systems primarily relied on traditional machine learning classifiers such as support vector machines, linear discriminant analysis, and random forests [20–22]. These models depend on carefully designed hand-crafted features in the time, frequency, or time-frequency domains. While feature extraction itself is relatively lightweight, these pipelines typically require extensive experimentation to identify optimal feature subsets [21]. The inclusion of irrelevant or suboptimal features can result in overlapping class boundaries and degraded classification performance [22]. With advances in deep learning, it enables end-to-end representation learning and have shown strong potential for biosignal-based HGR. TCNs, in particular, are well suited for modeling sequential biosignals due to their use of dilated convolutions, which capture long-range temporal dependencies while remaining computationally efficient [1].
Recently, attention mechanisms have been introduced to further enhance fusion models. Originating in natural language processing, attention has been successfully applied in computer vision and speech recognition for its ability to dynamically emphasize the most informative features. In the context of multi-modal biosignals, attention mechanisms can adaptively emphasize the more reliable modality when one is degraded by noise, fatigue, or motion artifacts [10, 11]. However, attention-based models introduce additional parameters and require substantially more training data to avoid overfitting [23]. They also increase computational complexity due to non-parallelizable operations, which in turn raises inference latency and memory usage [18, 24]. These constraints limit their practicality in embedded systems and real-time HMIs, where computational resources are scarce and rapid responsiveness is essential. While some studies have experimented with attention for biosignal-based HGR [25–27], there remains little research specifically on integrating attention within dual-path TCN frameworks for co-located sEMG-pFMG fusion under limb position variability.
Additionally, DL models, while powerful, often operate as ‘black boxes,’ obscuring how predictions are derived [28]. This lack of transparency poses challenges in clinical and rehabilitation contexts, where system trustworthiness and interpretability are critical [29]. XAI has emerged to address this need by providing methods that make model decision-making processes more transparent [29]. IGs is a widely adopted approach in XAI that establishes a link between a model’s output and its input features. It does this by accumulating the gradients along a path that gradually transitions from a chosen baseline input to the actual input, thereby identifying which features contribute most strongly to the final output [12, 30]. To the best of our knowledge, no prior study has employed XAI to systematically examine the relative contributions of co-located sEMG and pFMG signals to hand gesture classification across different gestures and subjects. In this work, XAI is used to verify whether electrical and mechanical sensing modalities contribute cooperatively within the fusion architecture, rather than one modality dominating the decision process. This analysis supports the effectiveness of the proposed fusion strategy and provides qualitative insights that may inform future investigations into sensor selection, placement strategies, and system design for wearable HMI applications.
In summary, while sEMG has been the dominant modality for HGR, its inherent variability motivates the integration of complementary mechanical signals such as pFMG. Multi-modal fusion strategies, particularly at the feature and DLs, have shown promise in enhancing recognition accuracy, yet the optimal architectures remain an open question. Attention mechanisms present a potential avenue for improved multi-modal fusion, but their computational demands and data requirements may restrict their practicality for real-time HMI systems. At the same time, XAI provides a unique opportunity to uncover how each modality contributes to final predictions, yet has not been systematically applied to sEMG-pFMG fusion tasks. These gaps collectively highlight the need for a systematic comparison of light-weight dual-path fusion and attention-based models, coupled with explainable analysis, to identify architectures that balance accuracy, efficiency, and interpretability for deployment in real-world wearable HMI applications.
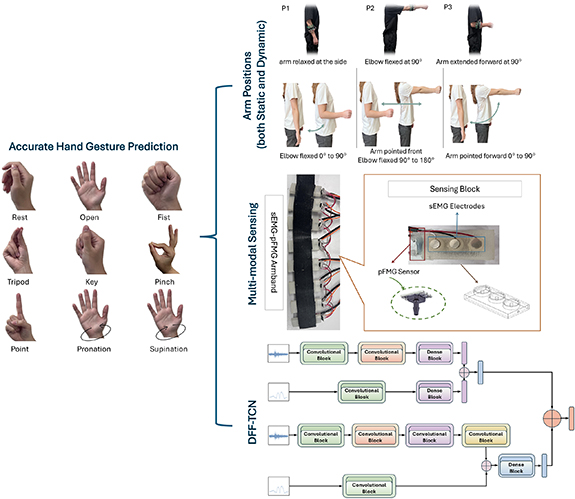
3.1. sEMG-pFMG sensing systemTo evaluate the proposed TCN architectures, we used a custom multi-modal armband that integrates sEMG and pFMG sensors in a co-located configuration (figure 1). The design was motivated by the complementary nature of these two biosignals: sEMG captures the electrical activation of muscles, while pFMG records the mechanical deformation of soft tissue during contraction. By combining both modalities at the same anatomical sites, the system enables richer representations of neuromuscular activity without requiring multiple separate devices.
Figure 1. Overview of the hand gesture recognition procedure and experimental setup. Nine functional hand gestures (rest, open, fist, tripod, key, pinch, point, pronation, and supination) are considered for gesture recognition. Data are collected under both static and dynamic arm position conditions to capture limb-position variability. A custom-built multi-modal sEMG-pFMG armband is worn on the forearm, integrating co-located sEMG electrodes and soft-chamber pFMG sensors to simultaneously capture electrical muscle activity and mechanical tissue deformation. Representative segments of real sEMG and pFMG signals recorded in this study are shown to illustrate the multi-modal inputs. The recorded signals are processed by the proposed dual-path fusion TCN (DFF-TCN), which integrates decision-level and feature-level fusion pathways to achieve robust hand gesture recognition under limb-position variability.
Download figure:
Standard image High-resolution imageThe armband consists of a flexible band housing eight pairs of sensing units evenly distributed around the forearm. Each unit integrates three NeuroSky stainless steel electrodes dedicated to sEMG acquisition alongside a soft air-chamber containing an embedded pressure sensor for pFMG detection. The air chambers are 3D-printed using NinjaFlex TPU, a flexible and cost-effective material that deforms under muscle bulging, producing pressure variations captured by the integrated pFMG sensors. This arrangement allows pFMG to operate without direct electrical contact, improving comfort and reducing issues such as electrode-skin impedance variability.The entire system measures approximately 45 mm × 20 mm × 12 mm, highlighting its compact size and lightweight construction. Such a form factor not only reduces user discomfort during long recording sessions but also makes the system suitable for embedding into prosthetic sockets, ensuring smooth integration into practical HMI applications. In addition to compactness, the system emphasizes durability and comfort. The flexible TPU maintains resilience under repeated deformation cycles [31], while its soft texture distributes pressure evenly around the forearm to prevent discomfort during extended wear. The co-located design ensures that both sEMG and pFMG respond to the same muscle contractions, thereby improving signal synchronization and reducing misalignment between modalities across sessions. This synergy enhances the robustness of gesture recognition by capturing both electrical excitation and mechanical deformation at the same anatomical site.
Overall, the system’s combination of compactness, ease of integration, and multi-modal sensing capability makes it particularly suitable for experimental studies and future translation into wearable prosthetic or rehabilitation devices. More detailed specifications of the sensing principles, fabrication steps, and validation experiments can be found in our previous study [9].
3.2. DatasetThis study was conducted using an offline dataset collected from ten right-handed healthy adults (three males and seven females, aged between 23 and 37 years). This research was conducted in accordance with the principles embodied in the Declaration of Helsinki and in accordance with local statutory requirements. All participants (or their parent or legal guardian in the case of children under 16) gave written informed consent to participate in the study. The study protocol received ethical approval (2023/006) from the University of Wollongong Human Research Ethics Committee. Recordings were obtained using a custom-built multimodal armband equipped with co-located sEMG electrodes and soft-chamber pFMG sensors (figure 1). The armband was worn on the right forearm, positioned in a similar anatomical region near the elbow across all subjects, and integrated eight pairs of co-located sEMG-pFMG sensors evenly distributed around the forearm circumference. This placement primarily covered major extrinsic forearm muscles involved in hand and finger movements, including the extensor digitorum, brachioradialis, and flexor digitorum superficialis. The armband can capture both electrical activity from the muscle surface and mechanical deformation of the underlying tissues.
The sEMG signals represent differential muscle electrical activity at the microvolt-to-millivolt level. The pFMG signals were acquired using analog gauge pressure sensors with a defined measurement range of 0–15 psi (ABPDANT015PGAA5, 0.25% full-scale accuracy; Honeywell International Inc. USA). Both sEMG and pFMG sensors were powered at 3.3 V and digitized using the analog inputs of a Teensy 4.1 microcontroller. Data acquisition was performed using a high-frequency embedded microcontroller system operating at 2000 Hz, providing high-resolution recordings that were stored for subsequent offline processing and analysis.
Signal preprocessing was performed in a modality-specific manner, following the protocol adopted in our previous study [9]. For sEMG, a high-pass filter with a cut-off frequency of 20 Hz was applied to remove low-frequency motion artefacts, a low-pass filter with a cut-off frequency of 150 Hz was used to suppress high-frequency noise, and a notch filter at 50 Hz was employed to eliminate power-line interference. The pFMG signals exhibited a higher SNR compared to the sEMG signals. Therefore, no additional filtering was applied to pFMG in order to preserve its pressure-based deformation characteristics. For model input preparation, both modalities were segmented using a sliding window of 200 ms with a stride of 10 ms (corresponding to 400 samples per window and a 20-sample stride at 2000 Hz).
Data collection was structured to capture a wide range of gestures under both static and dynamic arm positions. A set of nine gestures was selected to represent functional and commonly used actions (figure 1): rest, open, fist, tripod, key, pinch, point, pronation, supination. For static recordings, three distinct arm postures were adopted (figure 1): a relaxed arm at the side, an elbow flexed to approximately 90∘, and an arm fully extended forward. Each gesture was performed five times in every static posture, resulting in fifteen repetitions per gesture across the three static arm positions. Dynamic recordings were designed to mimic practical use cases in which limb positions naturally shift during activities. Three movement trajectories were chosen (figure 1): elbow flexion-extension from 0∘ to 90∘, forward pointing with elbow flexion from 90∘ to 180∘, and arm lifting from 0∘ to 90∘. During these recordings, participants continuously performed each gesture while moving their arms smoothly along the specified trajectories, completing at least one full cycle per trial. Each gesture was repeated five times under each dynamic condition, yielding fifteen trials per gesture for the dynamic dataset. Participants were not restricted to a fixed movement speed but were instructed to maintain smooth and continuous motion to ensure consistency while still capturing natural variability. Each recording lasted one second per gesture, corresponding to 2000 samples per channel, followed by a two-second rest interval to minimize fatigue. To further reduce the risk of muscle exhaustion, participants were provided with five-minute breaks between rounds. The full experiment consisted of three rounds: two rounds of static trials for training and testing purposes, and one round of dynamic recordings to capture movement-related variability during training. All models were trained and evaluated in a subject-specific manner, with a model trained for each participant using only that participant’s data.
From a practical point of view, users of prosthetic hands typically maintain gestures in arbitrary static arm positions during everyday tasks, rather than consistently operating from a single fixed posture. This means that reliable gesture recognition requires robustness across a wide range of possible limb orientations. To reflect this practical demand, our study placed particular emphasis on evaluating the prediction performance across multiple static arm positions. In addition to discrete static postures, dynamic arm movements were included as a data-efficient strategy to introduce continuous positional variability during data collection. Capturing a large number of discrete static arm positions would require substantially longer recording sessions, which can be difficult to achieve in practice, especially for amputee participants. By incorporating smooth and continuous arm motion, a broader range of arm orientations can be included within a shorter time, enriching the dataset with diverse positional information. By combining data from static and dynamic movement protocols, the resulting dataset provides increased variability for training, improving the model’s ability to generalize and accurately recognize gestures under random static arm positions encountered during practical use.
3.3. XAI-IGsTo provide deeper insight into how each sensing modality supports the overall decision-making process, we applied XAI. The analysis employed the IGs method [12, 32], which attributes the model’s predictions to input features by computing path-IGs from a baseline to the actual input. This approach is particularly well suited for biosignals, as it highlights the temporal regions and modalities that exert the greatest influence on classification outcomes.
Formally, IG for feature i of input x with baseline 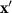 is defined as [32]:
is defined as [32]:
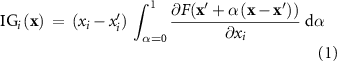
where 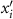 denotes the baseline input, xi represents the
denotes the baseline input, xi represents the 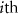 input feature, f is the target model under explanation, and
input feature, f is the target model under explanation, and 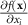 corresponds to the gradient of the model output with respect to the
corresponds to the gradient of the model output with respect to the 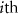 input dimension.
input dimension.
In practice, the integral is approximated using a Riemann sum with m steps [32, 33]:
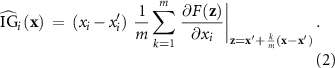
where m denotes the number of discrete steps used to approximate the path integral, k is the index of each step (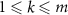 ), and z represents the interpolated input at step k, defined as
), and z represents the interpolated input at step k, defined as 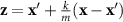 , which linearly progresses from the baseline input
, which linearly progresses from the baseline input 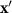 (when k = 0) to the actual input x (when k = m).
(when k = 0) to the actual input x (when k = m).
To quantify modality-level contributions, attributions were aggregated across features belonging to each modality:
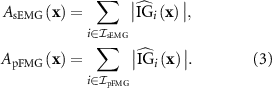
Relative percentage contributions were then calculated as:
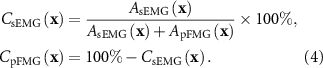
In our implementation, the IG method was applied to paired sEMG-pFMG inputs using Captum’s PyTorch library. For each input, attributions were computed jointly for the two modalities along a linear interpolation path from a baseline to the actual input. To ensure physiological relevance, we employed class-conditional ‘rest’ as the baseline. Following equations (3) and (4), absolute IG values were aggregated across channels and time for each modality, normalized, and then averaged across all samples. This yielded modality-specific contribution percentages that quantify how much sEMG and pFMG influence the network’s predictions. Aggregating contributions across gestures and participants provided robust estimates of modality importance at both the per-class and global levels, thereby offering a transparent view of the model’s decision-making process.
Embedding IG into the evaluation framework not only strengthens the interpretability of the proposed architectures but also bridges the gap between algorithm development and practical system integration. By explicitly linking modality contributions to both hardware design and algorithmic strategies, this analysis establishes a foundation for building wearable HMI systems that are not only accurate but also transparent, efficient, and adaptable in real-world environments.
To systematically investigate multi-modal fusion strategies for HGR, we considered a set of dual-path TCN architectures that integrate both DL and FL strategies. The central aim was not to reintroduce a single architecture, but rather to compare how different design choices, DFF-TCN with simple concatenation versus attention-based variants, impact accuracy, computational efficiency, and interpretability under limb position variability. By structuring the network into parallel pathways, one emphasizing independent modality-specific processing and the other early feature integration, these frameworks allow us to evaluate both modality contributions and the benefits of different fusion stages.
This study begins with the baseline DFF-TCN with concatenation, which employs parallel DL and FL fusion paths to integrate sEMG and pFMG. Here, the model serves as a controlled benchmark: a lightweight but effective dual-fusion design that avoids hand-crafted features and instead learns directly from raw inputs. We then extend this baseline with attention-based variants, embedding cross-attention modules either at the DL or FL fusion stage. These variants were specifically constructed to examine whether explicit modeling of inter-modality dependencies improves recognition performance and robustness under signal variability. By directly contrasting the three variants including simple concatenation, DL cross-attention, and FL cross-attention, this study offers a complementary evaluation that provides a clearer understanding of the balance between simplicity and adaptability in multi-modal fusion for wearable HMI systems.
To ensure a fair and consistent comparison, all model variants were trained under identical settings. Specifically, the Adam optimizer was used for training, and categorical cross-entropy was adopted as the cost function for multi-class gesture classification. Training was conducted using the same protocol across all architectures, such that any observed performance differences can be attributed to the fusion design rather than to differences in optimization or training configuration.
4.1. Concatenation-based DFF-TCNIn this work, we employed a feature-free architecture in which raw sEMG and pFMG signals were directly input into TCN models, thereby eliminating the need for hand-crafted feature extraction. This choice reflects a growing trend in biosignal-based recognition, where reliance on hand-engineered features can fail to capture the full complexity and informative content of raw signal data. By skipping manual feature design, the model lets the deep network learn useful patterns directly from the raw signals. This makes it more reliable when dealing with changes between recording sessions or unexpected signal conditions. In real-world wearable applications, where sensors often face issues like electrode shift, sweat, or motion artifacts, this automatic learning ability helps the system adapt better and maintain stable performance without requiring constant recalibration or redesign of features.
To account for the modality-specific characteristics of sEMG and pFMG signals, the architecture incorporated two independent TCN branches, one dedicated to each modality, within both the DL and FL fusion pipelines. This ensures that the system fully considers the electrical activity measured by sEMG and the mechanical tissue deformation captured by pFMG before integrating them. TCNs were chosen as the backbone because their use of dilated convolutions provides large receptive fields and efficient modeling of long-term signal dynamics, without the common issues of vanishing gradients seen in recurrent networks.
In the DL branch, each signal stream is processed independently through its dedicated TCN, producing a vector of logits that reflects the relative likelihood of each gesture class. These outputs represent the confidence of each modality in predicting the gesture. At the final stage, the two logit vectors are combined to produce an aggregated decision representation. This structure is advantageous because it preserves the classification strength of each modality while providing a safeguard against noise or partial signal loss. For example, if the sEMG stream is disturbed by electrode shift or electrical interference, the pFMG stream can still provide reliable predictions, keeping the system stable. Conversely, if the pFMG stream is affected by motion artifacts or soft-tissue shifts during movement, the sEMG stream can compensate by delivering consistent electrical activity patterns.
The FL branch integrates information earlier in the process. Here, sEMG and pFMG sequences are first transformed into temporal feature embeddings through convolutional layers. These embeddings are then concatenated and processed together in FC layers to produce a joint logit-level classification output. This pathway allows the model to explicitly learn interactions between modalities. By modeling these interdependencies, the FL branch can exploit complementary patterns that would not be captured by either modality on its own.
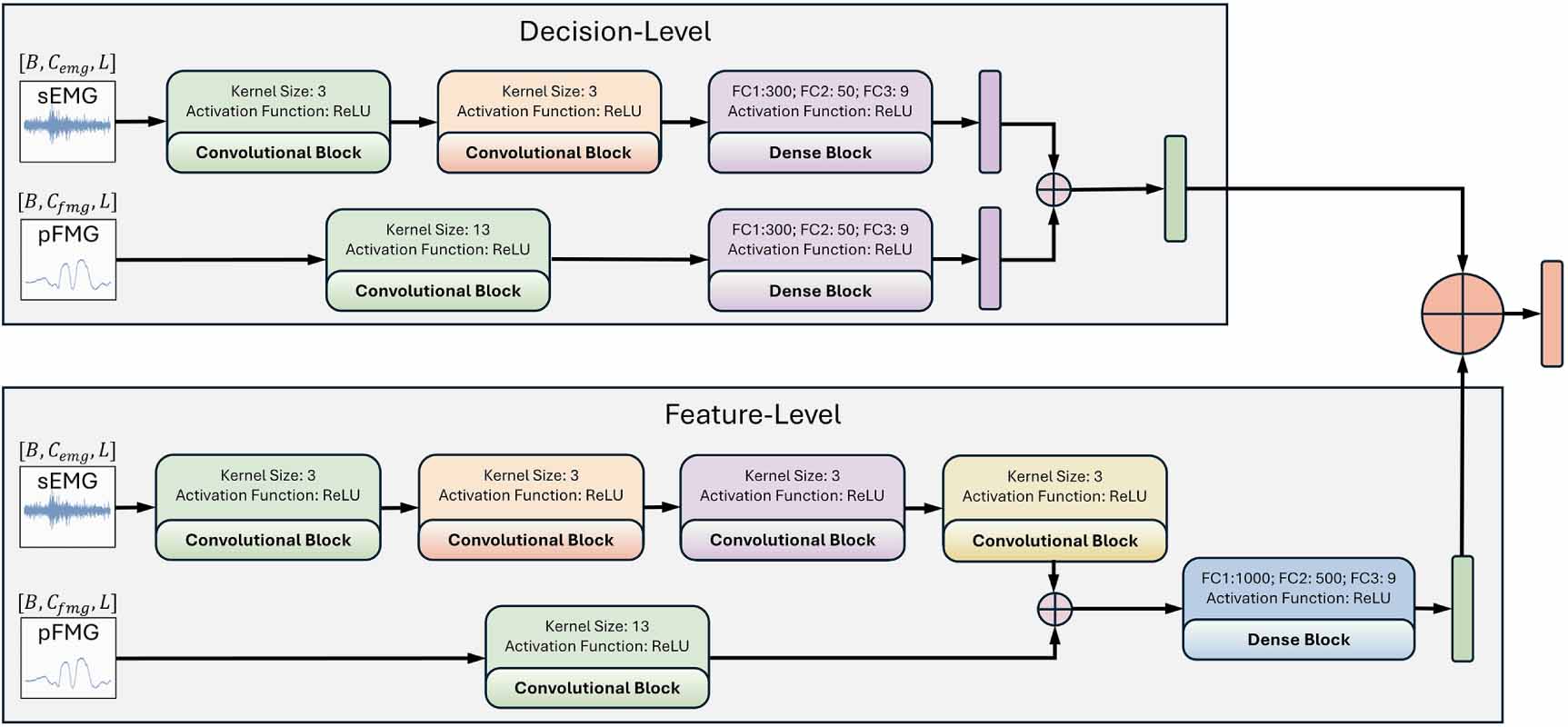
The dual-path fusion TCN (DFF-TCN) (figure 2) combines both DL and FL outputs to complement the strengths of each fusion strategy. In this way, the DL branch contributes robustness by maintaining independent decisions, while the FL branch provides richer cross-modal feature integration. Together, they form a complementary system that balances independence with synergy. The final prediction is obtained by performing logit-level fusion through element-wise summation of the DL and FL outputs, followed by selection of the class with the highest combined score:
Figure 2. The architecture of the DFF-TCN with concatenation consists of two parallel pipelines: the feature-level temporal convolutional network (FL-TCN), designed to merge features, and the decision-level Temporal Convolutional Network (DL-TCN), which fuses predictions. Each branch is trained independently before being combined in the final stage. Raw sEMG and pFMG signals with batch size B = 512, channel count 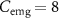 and
and 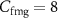 , and window length L = 400. Kernel sizes, activation functions, and fully connected (FC) layers used in each convolutional block are shown within the corresponding blocks. Representative segments of real sEMG and pFMG signals recorded in this study are shown to illustrate the multi-modal inputs.
, and window length L = 400. Kernel sizes, activation functions, and fully connected (FC) layers used in each convolutional block are shown within the corresponding blocks. Representative segments of real sEMG and pFMG signals recorded in this study are shown to illustrate the multi-modal inputs.
Download figure:
Standard image High-resolution image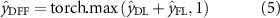
where 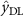 and
and 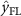 are the prediction score vectors (logits) from the DL and FL branches, respectively. This late-stage integration ensures that both independent classification confidence (from DL) and joint feature representation (from FL) contribute to the final output.
are the prediction score vectors (logits) from the DL and FL branches, respectively. This late-stage integration ensures that both independent classification confidence (from DL) and joint feature representation (from FL) contribute to the final output.
By combining DL and FL pathways, the concatenated model is designed to be resilient to variability inherent in biosignals. Changes in limb position can alter signal characteristics across sensing modalities, and the dual-path structure enables complementary information from sEMG and pFMG to be jointly exploited to support stable classification. Rather than relying on a single modality, the model benefits from the cooperative contribution of electrical and mechanical signals, which helps reduce sensitivity to modality-specific variations. As biosignal quality can vary in real-world wearable scenarios, the ability to integrate information from multiple modalities enhances the stability and robustness of the system. These properties make the concatenation-based model well-suited for practical wearable HMI applications, where reliable performance and computational efficiency are essential.
4.2. Attention-based DFF-TCNTo investigate the role of modality-interactive learning in multi-modal gesture recognition, we extend the baseline DFF-TCN by incorporating cross-attention mechanisms into either its DL or the FL fusion paths. Unlike the original framework, which processes sEMG and pFMG signals independently until the final stage of fusion, the attention-based variant explicitly models the interdependencies between the two modalities. This design allows one signal to guide or refine the representation of the other. The central aim of this architecture is to determine whether introducing cross-modal interactions improves the integration of complementary information, particularly under conditions of signal variability caused by limb position changes.
From an experimental perspective, these architectural adjustments were purposefully developed to provide a direct and controlled comparison with the DFF-TCN with concatenation. By embedding attention only at specific fusion stage, either in the DL or FL fusion path, we are able to evaluate its influence on both classification accuracy and computational load. The attention mechanisms are known to increase model complexity and resource demand, which may challenge real-time deployment on embedded hardware. The comparative study therefore balances two objectives: improving HGR performance while carefully monitoring their computational cost.
In our architecture, the query and K–V pairs are derived from either sEMG or pFMG features depending on the fusion path. The attention operation [34] can be expressed mathematically from the perspective of the sEMG stream as:
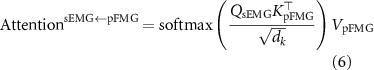
and symmetrically for pFMG:
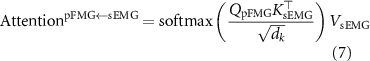
where Q, K, and V represent the query, key, and value matrices, respectively, and dk is the dimensionality of the keys. In practical terms, this formulation enables one modality to dynamically adjust its feature space by referencing information carried in the other modality, thereby enhancing the network’s ability to focus on gesture-relevant temporal cues.
These cross-attention modules are integrated as modular blocks, embedded independently into either the DL or FL fusion paths while leaving the rest of the architecture unchanged. Such modular integration ensures a fair and transparent comparison against the baseline DFF-TCN, since the only difference lies in the presence or absence of cross-attention layers. This setup also makes it easier to clearly study how attention affects the model, helping us see whether letting the two signals interact actually improves accuracy and generalization, and whether the extra computing cost is worth it.
The following subsections detail how the attention modules are applied within the DL and FL fusion paths, respectively, and explain how these modifications enhance the network’s ability to capture and exploit modality-aware interactions.
4.2.1. Attention-based DFF-TCN (DL fusion path)To further investigate the potential benefits of enhancing modality-specific interactions, we integrated a cross-attention mechanism into the DL fusion path of the DFF-TCN framework (figure 3). The inclusion of attention layers provides a structured way for the model to dynamically exchange information between sEMG and pFMG featured data, rather than processing them in isolation.
Figure 3. Attention-based DFF-TCN (DL fusion path). Decision-level cross-attention is applied between modality-specific representations, where one modality is projected as the query (Q) and the other provides the corresponding key–value (K)–(V) embeddings, each with dimensionality dk.
Download figure:
Standard image High-resolution imageIn this design, one modality’s featured data is treated as the query, while the other provides the K–V pairs. This formulation allows the network to selectively highlight features from the complementary modality that are most relevant for classification. For instance, sEMG-derived representations can be refined by referencing contextual patterns from pFMG, which may capture consistent mechanical cues during muscle contractions. Conversely, pFMG features can be enriched by the neural activation signals from sEMG, enabling a finer temporal alignment between electrical and mechanical activity. This bidirectional exchange gives the model greater flexibility in capturing gesture-relevant cues that may otherwise remain latent. The use of multi-head attention further extends this capability by allowing the model to examine multiple perspectives of inter-modality relationships in parallel. Each attention head can focus on different aspects of the interaction, such as aligning fine-scale temporal details or emphasizing broader gesture-level correlations. This parallelized mechanism enhances the richness of cross-modal feature integration and provides a more comprehensive representation of the underlying neuromuscular dynamics. Another advantage of embedding attention in the DL pathway is that it augments the probability outputs of each modality with contextual information before they are combined. This means that each branch not only contributes its own independent confidence but also incorporates guidance from the paired modality, potentially leading to more balanced and reliable decision-making.
The core DFF-TCN structure remains intact, with the attention modules introduced as an extension rather than a replacement. This ensures that the comparison with the baseline model is controlled and fair, as all other components of the pipeline are preserved. In this way, the impact of DL cross-attention can be directly assessed in terms of classification accuracy and computational requirements. Furthermore, embedding attention at the DL stage provides a unique balance: while each modality still maintains an independent decision-making pathway, it can also borrow contextual information from the complementary modality, thereby combining the advantages of independence and interaction.
4.2.2. Attention-based DFF-TCN (FL fusion path)To further strengthen the integration of complementary information between modalities, we extended the DFF-TCN architecture by embedding a cross-attention mechanism in the FL fusion path (figure 4). In the baseline design, sEMG and pFMG signals are first processed independently through convolutional branches that extract modality-specific temporal features. These feature embeddings are then concatenated and passed into a multilayer perceptron to produce classification outputs. While concatenation provides a straightforward way to combine representations, it does not explicitly capture the underlying interactions or dependencies between the two modalities. As a result, potentially valuable correlations between electrical and mechanical activity may remain underutilized. Therefore, we replaced the simple concatenation with a cross-attention module that enables each modality to selectively focus on informative data from the other. Specifically, sEMG signals serve as the query while pFMG signals act as keys and values in one attention block, and vice versa in another. This bidirectional design allows each modality not only to contribute its own unique characteristics but also to actively draw context from the other modality. The attention mechanism facilitates cross-modal interaction, allowing the network to focus on complementary patterns and enhance the temporal coherence of the fused features. After attention, the outputs from both streams are pooled and merged before being passed into a FC classifier.
Figure 4. Attention-based DFF-TCN (FL fusion path). Raw sEMG and pFMG signals are first processed independently by modality-specific temporal convolutional networks (TCNs) to extract feature embeddings. FL cross-attention is then introduced to replace simple feature concatenation, enabling explicit modeling of inter-modality interactions. sEMG features are projected as the query (Q) while pFMG features provide the corresponding key–value (K)–(V) embeddings, each with dimensionality dk and vice versa in a paralle
Comments (0)