
Remember me
Five different Scenarios were designed to reflect reasonable randomness for uncontrolled features of a Phase 1 study that could affect the precision and bias of a concentration-QTc analysis (Table 1). Each scenario refers to a different study design assuming perfect adherence to what is stated in the protocol, but with different levels of prespecified controlled features. Scenario A comprises an optimal design with all important features for a concentration-QTc analysis controlled in the design and was used as reference in this analysis. Scenarios B, C, D, and E had sub-optimal designs lacking control over mealtime, dosing time and/or sampling time. Some scenarios represented a random, but systematic, variability between subjects in the placebo group and the active treatment group. The results generated were compared to the reference (Scenario A) in order to conclude on the suitability of the unadjusted PLM and to assess the added value of an adjustment on PLM when applied to the sub-optimal designs. The simulation settings used for each Scenario are described in Table 1.
For each Scenario, the analysis was performed in a stepwise manner. First, pharmacokinetic (PK) data in healthy subjects receiving active treatment were simulated. Secondly, QTcF data were simulated assuming three different PK-QTcF relationship cases (i.e., no, mild and moderate drug effect) (Online resource 1). Then, the unadjusted PLM according to Garnett et al. [2] was applied to all Scenarios. In addition, the adjusted PLM was applied to the sub-optimal designs. Finally, the models were used to predict the QTcF signal and to evaluate that prediction with the threshold of regulatory concern (upper bound of the two-sided 90% confidence interval around the mean effect exceeding 10 ms [1]) to determine if either the unadjusted or adjusted PLM was adequate.
For each Scenario, parallel groups with 10 subjects receiving placebo or a single drug dose of 10, 25, 50, 75, 100, 150 or 250 mg were simulated.
Table 1 Simulation settings used for five scenariosPK simulations settingA one-compartment PK model with first-order absorption and elimination was used to simulate PK data. For Scenarios A, B, C and D, the mean absorption time was set to 1 h and the central volume of distribution to 5 L with a half-life of 12 h. For Scenario E, the half-life was set to the same value, however the unit was changed to days in order to simulate concentrations for a long half-life drug. Variability was accounted for by including a coefficient of variation (CV) of 25% on all primary PK parameters and a residual proportional error of 7.5%. According to Garnett et al. [2], the QTcF signal should be evaluated at the highest clinically relevant exposure (HCRE) that was defined as being twice the maximal concentration (Cmax) predicted for a dose of 100 mg (2x Cmax = 35 mg/L).
QTcF simulation settingQTcF data were simulated using a model describing the placebo and the drug effect. The placebo model was implemented as described in equation (eq) 1 (each component was defined separately):
Placebo model:
$$\beginQ_=Baseline+Circ_+Circ_+\\Circ6_+FoodEffect+\:_with\:^2=8.6\end\:$$
(1)
Where i and j represent the ith individual at the jth time, \(\:Circ24\), \(\:Circ12\:and\:Circ6\) are the circadian rhythm at 24, 12, and 6 h relative to midnight, \(\:FoodEffect\:\) is the effect of food intake and \(\:_\) is the residual error of variance\(\:\:^\).
Based on the placebo model developed by Minocha et al. [7], the baseline was defined as shown in Eq. 2 assuming non-black male subjects and a circadian rhythm was included in the placebo model as described in Eqs. 3, 4 and 5.
$$\:Baselin_=400\:*\:\frac\:*0.031+_\:with\:^=13.9$$
(2)
$$\:Circ_=\text*\frac_-2.2\right)\right)}$$
(3)
$$\:Circ_=\text0*\frac_-3.6\right)\right)}$$
(4)
$$\:Circ_=\text*\frac_-1.7\right)\right)}$$
(5)
Where i and j represent the ith individual at the jth time, \(\:Circ24\), \(\:Circ12\:and\:Circ6\) are the circadian rhythm at 24, 12, and 6 h relative to midnight, \(\:ClockTime\) is the clock time. The \(\:_\) is sampled for each individual from a normal distribution with mean 0 and variance \(\:^\).
An effect of food intake was also included in the placebo model based on time since last meal (TSLM) in hours as follows:
$$\:\beginTSLM<0\:\vert\:TSLM>6:\:+0\:ms;\:\\\:TSLM\:\left[\text\right]:\:Linear\:interpolation\:from\\\:x=0\:to\:x=3\:and\:y=0\:to\:y=-7\:ms;\:\\\:TSLM\:\left[\text\right]:-7\:ms\\\:TSLM\:\left[5,\:6\right]:\:Linear\:interpolation\:from\:\\x=6\:to\:x=5\:and\:y=-7\:to\:y=0\:ms.\end$$
The drug effect was implemented as shown in Eq. 6. Three different cases were assumed: no, mild and moderate drug effect. The slope population parameter (\(\:Slop_\)) was set to 0.2 for the mild effect and 0.5 for the moderate effect.
$$\:_\:=Con_\:*\:(Slop_+_\:)\:with\:^=\text$$
(6)
To simulate the QTcF data, the drug effect \(\:DrugEffectij\:\)was combined with the placebo model \(\:Q_\) in an additive manner as shown in Eq. 7.
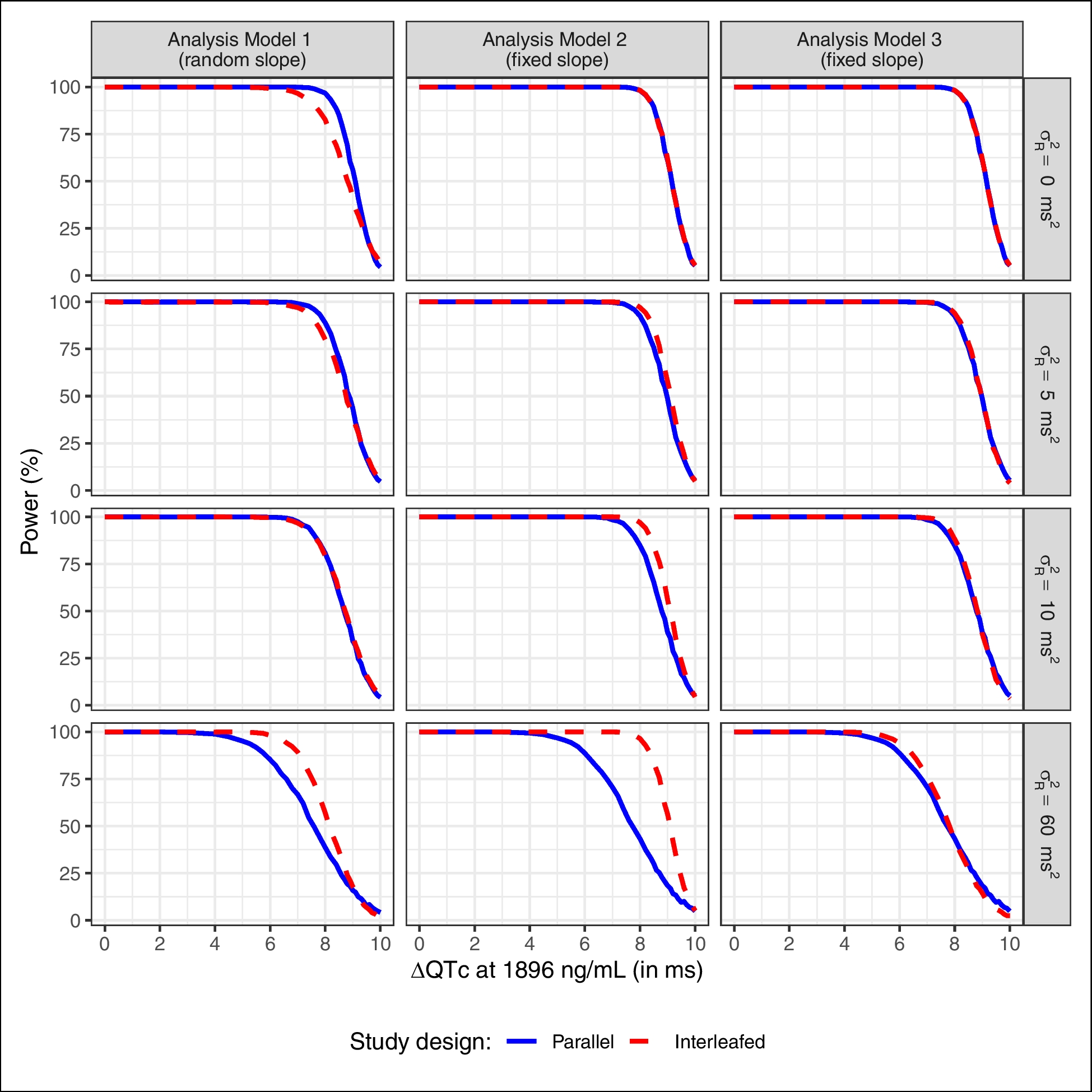
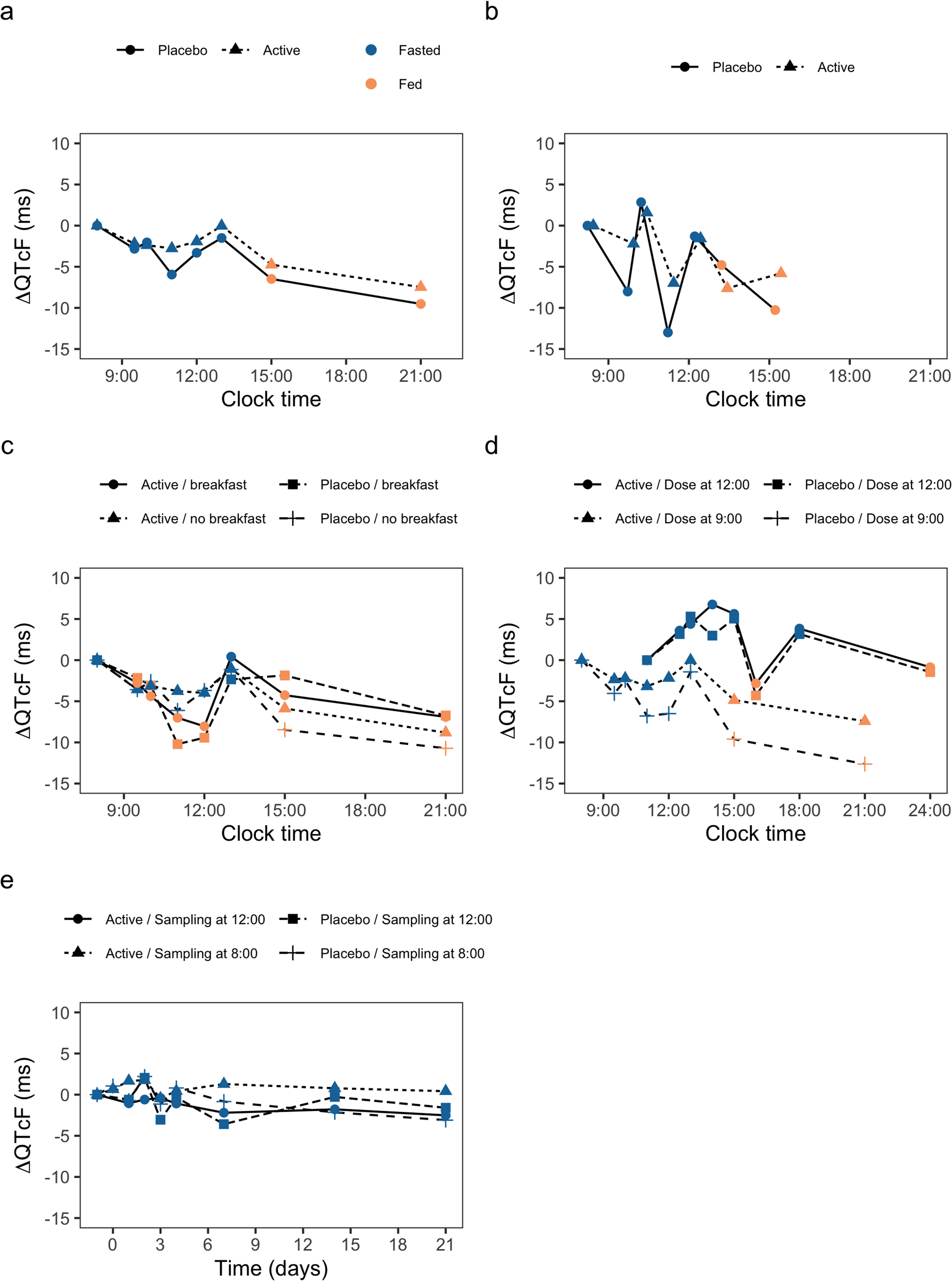
Change from baseline QTcF (ΔQTcF) and placebo adjusted change from baseline QTcF (ΔΔQTcF) were computed using the simulation results for each Scenario. Figure 1 shows the ΔQTcF profiles for each simulated case in each Scenario to illustrate the different designs simulated in this analysis.
Fig. 1
Change from baseline (ΔQTcF) versus clock time (Scenarios A, B, C, D) or time since first dose (Scenario E) when assuming a mild drug effect stratified by Scenario and colored by food effect. The line types represent the different cases simulated in each Scenario for a single showcase simulation. The panels a, b, c, d and e correspond to their Scenarios A, B, C, D, and E, respectively. The lines represent the mean, except for Scenario B where the lines show only data of one patient as example since the ECG sampling was simulated at different clock time for each subject. Active corresponds to the subjects receiving the drug. The x-axis for panel e represents the time since first dose in days to illustrate the ΔQTcF profile when a long half-life drug is administered
Unadjusted PLMThe unadjusted PLM as described by Garnett et al. [2] was applied to the simulated data. The structural model consists of a linear relationship between simulated drug concentration and ΔQTcF with a separate intercept for active treatment and placebo. Several covariates were included a priori in the structural model as described in Eq. 8. Nominal time after dose (N-TAD) was included as a categorical covariate to adjust for diurnal variation of QTcF, as for most Phase I studies N-TAD can be reasonably assumed to reflect the time of day or clock time. Finally, the baseline QTcF (QTcF0) was included as continuous covariate.
Equation 8 was used in the unadjusted PLM to estimate ΔQTcF for subject i at N- TADj:
$$\:\begin\Delta\:_=_0+_+_1\ast_i+\left(_2+_\right)\ast\\C_+_+_4\ast\left(_-_\right)+\:\epsilon\end\:\:$$
(8)
where θ’s were estimated to be the same for the entire population with similar associated covariate values. In this equation, θ0 is the intercept when all covariate effects are null, θ1 is the intercept estimated for active treatment, θ2 is the concentration-QTcF slope, θ3N–TAD =j is the mean ΔQTcF at N-TAD j, θ4 is the estimated effect of QTcF0, QTcF0,median is the median of QTcF0 for the analysis data set, TRTi is the treatment arm for subject i. The η’s are sampled for each individual from a normal distribution with mean 0 and variance ω2 and ε is sampled for each observation from a normal distribution with a mean of 0 and variance \(\:^\).
In the PLM, IIV was added to both the intercept and slope from the linear PK-QTcF model. It was assumed that the random effects were normally distributed with means [0, 0]. To prevent problems with model convergence, the covariance matrix was altered to a more constraint format: no covariance between IIVs was assumed. The residual unexplained variability was implemented as an additive error model as follows:
$$y_=_+\varepsilon_$$
(9)
where, for a continuous endpoint, yij is the jth observation from the ith individual, \(\:\widehat\)ij is the corresponding model predictions, often referred to as individual prediction, and εadd, ij is a normally distributed random variable, with mean 0 and standard deviation \(\:\sigma\:\)add.
Adjusted PLMFor each of the sub-optimal design Scenarios, adjustments were applied to the PLM to either account for the food effect separately, or to account for both the food effect and the clock time variability. The adjustments used for each Scenario are listed in Table 1.
To adjust for the effect of food intake, food was included in the PLM as a time varying binary covariate based on the actual TSLM for each protocol using a variable that was set to 1 for each sample taken at TSLM between 2 h and 4 h and 0 for the other observations [3, 5, 8].
To adjust for diurnal variation associated with clock time, first a theoretical QTcF referred to as diurnal variation adjustment factor (DBCG) was computed based on reading the approximate variations identified by Minocha et al. rounded to 2.5 s [7]:
if clock time per protocol rounded to 0 decimals is between 0 and 1 then DBCG = 0.
if clock time per protocol rounded to 0 decimals is between 2 and 3 then DBCG = 5.
if clock time per protocol rounded to 0 decimals is between 4 and 8 then DBCG = 2.5.
if clock time per protocol rounded to 0 decimals is 9 then DBCG = 0.
if clock time per protocol rounded to 0 decimals is between 10 and 11 then DBCG = −2.5.
if clock time per protocol rounded to 0 decimals is between 12 and 24 then DBCG = 0.
Next, the change from baseline (∆DBCG) was computed for each DBCG value that results in a theoretical range of values from − 7.5 (baseline DBCG = 5, observation DBCG = −2.5) to 7.5 (baseline DBCG = −2.5, observation DBCG = 5) with other possible values being − 5, −2.5, 0, 2.5, and 5. Of note, not all unique values need to be present across the data set. These ∆DBCG values were included in the PLM as a categorical covariate.
Evaluation of signalThe PLM was used to conclude on the QTcF signal. A relevant QTcF signal was defined by Garnett et al. [2] as a predicted upper bound of the 90% confidence interval (CI) of the mean ΔΔQTcF above 10 ms.
The mean signal prediction was estimated using Eq. 10, and the 90% CI is subsequently calculated using Eq. 11 and Eq. 12. The signal was evaluated at the HCRE of 35 mg/L.
$$\beginMean\Delta\:\Delta\:QTcF=f_\\\:\left(TRT=1,TIME=t_,C=C_i,_0=0,FOOD=0\right)\\-\:f_\left(TRT=0,TIME=t_,C=0,_0=0,FOOD=0\right)\end\:$$
(10)
where \(\:_\)() is the PLM function with covariates set to mentioned values; Ci is the concentration of interest; tCi is the time after dose at which Ci is typically seen.
$$\:SE=\sqrt_\right)+^*var\left(_\right)+2C*cov(_,_)}$$
(11)
$$\:90\%CI=\:Mean\text\text\text\text\pm\:\text\left(0.95,\text\text\right)\text\text\text$$
(12)
where \(\:_\) is the estimated treatment-specific intercept; \(\:_\) is the estimated slope, \(\:var\left(_\right)\) is the variance of the treatment-specific intercept, C is the concentration of interest; \(\:var\left(_\right)\) is the variance of the slope; \(\:cov(_,_)\) is the covariance of the intercept and slope, t is the critical value determined from the t-distribution, DF is the degrees of freedom (number of estimated parameters-1), and SE is the standard error.
For each of the Scenarios, the simulations were performed 1000 times. The same dosing regimens, PK and QTcF model settings were used across the replicates of each Scenario. The dataset of each Scenario was simulated 1000 times. The adjusted and unadjusted PLM were applied to each of the simulated datasets. The QT effect was evaluated with the unadjusted and adjusted PLM for each of the 1000 replicates in each Scenario. The negative rate, i.e., the percentage of simulations for which the upper limit of the 90% CI was below the 10 ms threshold at the HCRE, was calculated. This negative rate should be as close as possible to the negative rate from the reference (Scenario A) assuming a positive drug effect.
The software R version 4.2.2 (2022-10−31) with the package lme4 (version 1.1.30) was used for data management and the fitting and predictions of the PLM. Simulations were conducted in R using the mrgsolve package (version 1.0.6).
Comments (0)