In the proposed semi-supervised framework, (1) we generate longitudinal subtypes of a driving outcome (glycemic control) based on clustering, where we leave out co-developing outcomes that will later serve as validators. In a separate step, (2a) we then validate candidate subtype solutions in a supervised manner based on their association with a primary outcome of practical importance (FSIQ). In the DirecNet example, (2b) we extend validation (“validate validation”) by leveraging multidimensional outcomes. In this extra step, various secondary outcomes (Performance and verbal IQ, brain measures) are used to further support and better understand the subtype solutions already validated based on the primary outcome (FSIQ). The selected final subtype labels can then be deployed as common variables in subsequent analyses for prediction and inference with an assurance that they are well-tethered to clinically meaningful validators.
3.1 Generating latent subtypes
To generate empirical subtypes that effectively summarize repeated outcome measures, various clustering methods can be applied. In our application, we use a model-based clustering approach known as growth mixture modeling (GMM), or latent trajectory class modeling. In this context, we use the terms latent class and cluster interchangeably. In GMM, we jointly handle the modeling of trajectory shapes (as in linear mixed-effects modeling) and the clustering of individuals (as in Gaussian mixture modeling) (Muthén and Shedden 1999). Although increasingly applied across research fields, this method remains less familiar in the machine learning context. Within the targeted validation framework, our previous studies (Jo et al. 2017, 2018, 2023) showed that different clustering methods (k-means, model-based clustering using mclust, GMM) yield highly stable subtype results, owing to model validation and selection based on common external validators. Our slight preference for GMM stems from its interpretable parameters (where the outcome starts and how it changes), which align well with how clinical experts conceptualize longitudinal changes in clinical outcomes.
Focusing on a single driving outcome, the basic structure of GMM is shown below. The outcome U (e.g., glycemic control) for patient i (\(i=1, 2,..., N\)) at measurement time point t (\(t=1, 2,..., T\)) conditioned on latent trajectory class \(C_i=j\) can be expressed as
$$\begin U_|(C_i=j)= & \sum _^\eta _\,S_^g\,+ \varepsilon _, \end$$
(1)
$$\begin \eta _= & \eta _ + \varvec'_\,\varvec_ +\, \zeta _, \end$$
(2)
where there are J possible trajectory classes (\(j=1,2,..,J\)). The polynomial growth factors \(\varvec_=(\eta _,\eta _,..,\eta _)\), where \(g=1,2,..,G\), capture the change over time. For example, \(\eta _\) for the linear, \(\eta _\) quadratic, \(\eta _\) cubic growth, and so forth. We use a time scale of interest for the time score \(S_^g\), where polynomial growth can be imposed. For example, we have 16 repeated measures of glycemic control (TIR) over 6 years in DirecNet, where the time scale of interest is the time from the baseline. Then, the corresponding time scores would be \(S_^1\) (\(S_^1=0, 3, 6,..., 72\) months) for the linear growth and \(S_^2\) (\(S_^2=0^2, 3^2, 6^2,..., 72^2\)) for the quadratic growth factor. We assume multivariate normal distribution for the measurement errors and random effects. That is, \(\varepsilon _ \sim MN(0,\varvec_}\)) and \(}\sim MN(0,\varvec_})\). The association between the growth factors and covariates \(\varvec\) is captured by \(\varvec_\), where \(\varvec_j=(\varvec_,\varvec_,..,\varvec_)\).
The probability of subject i belonging to a certain trajectory class (\(\pi _=Pr(C_i=j)\)) may depend on the influence of covariates. The multinomial logit model of \(\pi _\) conditioned on baseline covariates \(\varvec_i\) can be expressed as
$$\begin logit(\pi _\,|\,\varvec_)\,=\,\beta _ + \varvec'_\,\varvec_ \end$$
(3)
for \(j=1,2,...,(J-1)\). The association between the class probability and covariates \(\varvec\) is captured by \(\varvec_\). In models without covariates, all terms related to \(\varvec_i\) disappear in Eqs. (2) and (3).
For maximum likelihood estimation of GMM in our application, we used Mplus (Muthén and Muthén 1998–2017), although other options are also available (e.g., OpenMx in R, Proc Traj in SAS). For automated implementation of clustering, we used the R package vclust (https://github.com/LV-learning/vclust), which has been developed to facilitate the joint use of unsupervised clustering and supervised validation of generated clusters. In particular, we used the genclust module in vclust for generating subtypes, which automatically increases the number of classes based on user-specified rules (e.g., at least ten units in each trajectory class) or until it encounters convergence problems. We used ample starting values to avoid potential convergence at local maxima.
In principle, any type of hard or soft clustering methods can be used to empirically generate subtypes (vclust can currently handle mclust and kmeans in R in addition to Mplus). When hard clustering is used (e.g., K-means), the generated subtypes are ready to be validated. When soft clustering is used as in GMM, each unit (patient) is assigned to multiple classes with varying probabilities that add up to one. In this case, a common strategy is to assign each unit to only one class with the highest probability, which we will also follow in this study. The possibility of accounting for the uncertainty surrounding the trajectory class membership has been previously demonstrated (e.g., Jo et al. 2017) in the semi-supervised learning context, although further research is needed to support its general use.
In the maximum likelihood estimation using the expectation maximization (EM) algorithm, latent trajectory class \(C_i\) is handled as missing data. Based on the model described in (2) and (3), the posterior class probability \(p_\) of subject i belonging to class j conditioned on observed data \((\varvec_i, \varvec_i)\) and the current estimates of model parameters \((\varvec^*,\) \( \varvec^*_,\varvec^*_,\varvec^*_},\varvec^*_})\) from the iterative EM procedure can be expressed as
$$\begin p_\big ( \varvec^*, \varvec^*,\varvec^*,\varvec^*_,\varvec^*_\big )=\frac(\varvec^*) f\big (\varvec_i \mid C_i=j,\, \varvec_i, \varvec^*_,\varvec_^*,\varvec^*_},\varvec^*_}\big )}^ \pi _(\varvec^*_) f\big (\varvec_i \mid C_i=j', \, \varvec_i, \varvec^*_,\varvec_^*,\varvec^*_},\varvec^*_}\big )}\end$$
(4)
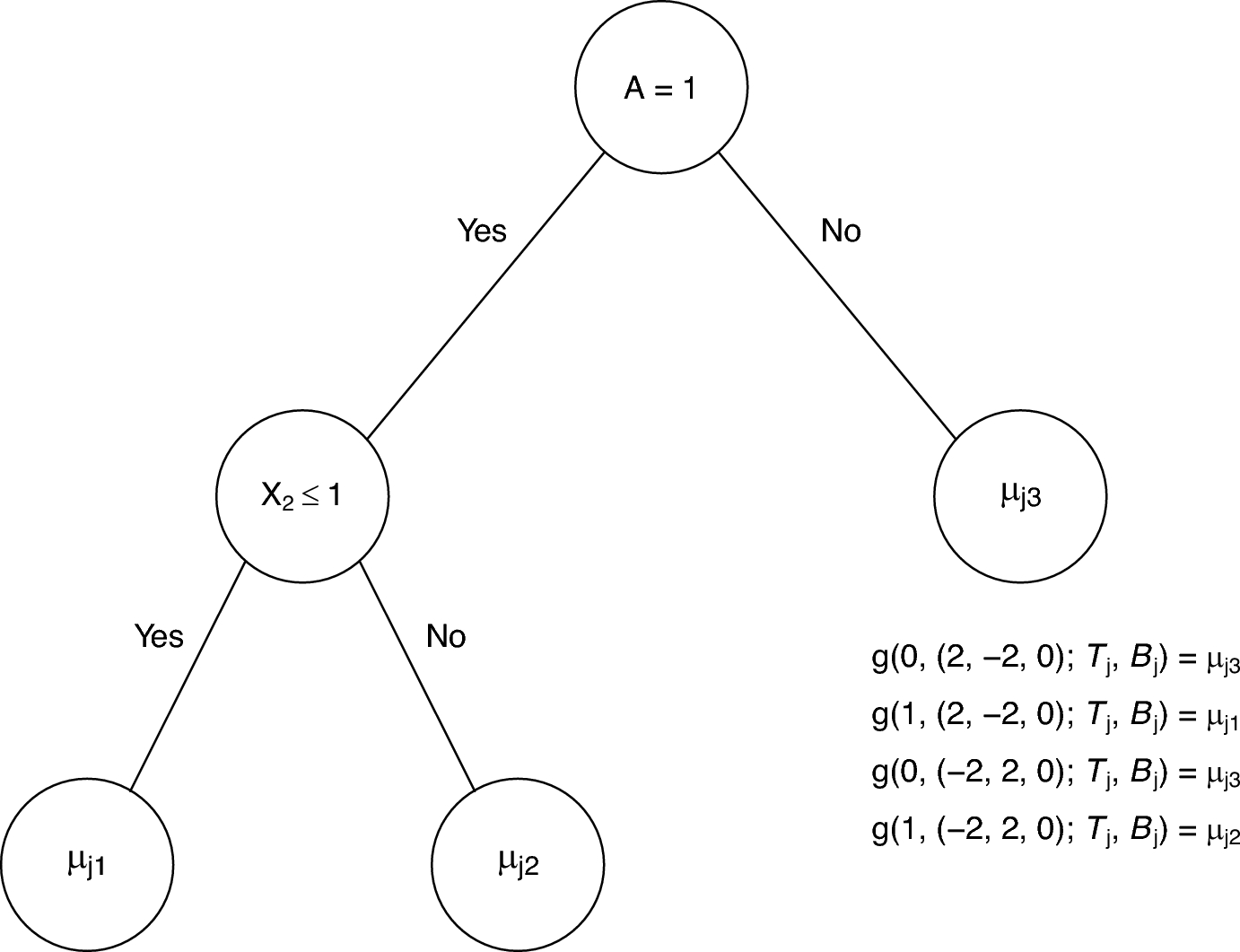
which is the main product of GMM we will use for our subtyping. Once each subject is assigned to his or her most likely trajectory class based on the posterior class probability, subtypes can be formulated using the class membership as it is, or after regrouping classes depending on clinical interests. As in any subgroup analysis, better targeted contrasts, instead of contrasting every possible pair of subtypes, will improve efficiency. Henceforth, we will use the term “subtype label” to refer to a variable with categories of trajectory classes that will be contrasted. In this study, we will focus on a simple comparison strategy using a series of two-category contrasts, where one category (comparison) is compared to the other category (reference) in each contrast. This strategy works well in our DirecNet application given our interest in examining the deviation of each trajectory class from the control group (i.e., individuals without diabetes). Under this scenario, we simply define subtype label L for individual i based on model m and contrast method s as
$$\begin ^_= \left\ 1 \,\,\, \text \\ 0 \,\,\, \text, \end \right. \end$$
(5)
where each category may contain one trajectory class or a group of trajectory classes. As in any subgroup comparisons, not all individuals in the sample will be included in a particular contrast. For example, in our DirecNet application, a 3-class model leads to 3 contrasts (class 1 vs. control, class 2 vs. control, class 3 vs. control). Note that the control group is without diabetes (i.e., no monitoring of glycemic control), and therefore could not be included in GMM of glycemic control measures. However, it can still serve as a good reference group in terms of other outcomes such as cognition and brain. In the current version of vclust, the default is to split the classes in each model into two categories in all possible ways. It is also possible to use the customized setting, where the default is to contrast each class to one common reference category (e.g., control group in DirecNet). The users are also allowed to choose a particular contrast of interest.
3.2 Targeted validation of latent subtypes
Given the unsupervised nature of latent subtypes, systematic validation is critical to support clinical validity and meaningful interpretation of generated subtypes. We will follow the semi-supervised approach outlined in Jo et al. (2023), where the quality of latent subtypes is directly evaluated based on their targeted purpose or utility. In this context, subtype labels can be actively validated in a supervised fashion based on their association with clinically meaningful validators. Validation using well-defined clinical validators has two main advantages. First, validation is conducted in a streamlined supervised learning framework (vs. relying on fit measures and incorporating experts’ knowledge in ad hoc ways). This is an important shift that makes the validation process for latent subtypes more efficient and systematic (a large pool of candidate subtype labels can be systematically validated). Second, the use of clinical validators makes selected subtypes well-aligned with intended clinical goals, a valuable property for generated latent subtypes to be accessible and deployable in practice.
In the supervised framework, latent subtypes can be validated in many different ways specifically targeting what matters the most in particular contexts. In previous studies (Jo et al. 2017, 2018, 2023), the goal was to find latent subtype labels that better represent longitudinal progression of manic symptoms than conventional labels using fixed cutpoints (e.g., low risk if the symptom score \(< 12\), elevated risk otherwise). Given the exploratory nature of latent subtypes, the cutpoint-based labels were used as key validators of latent labels, although the ultimate intention was to generate latent labels that improve upon cutpoint-based labels. The current study focuses on a scenario, where the usefulness of latent subtypes of one longitudinal outcome (e.g., glycemic control in DirecNet) lies in their relevance to the heterogeneity in other outcomes (e.g., cognitive development). Clear separation of the validators and the validated latent subtypes opens up various possibilities for practical applications and validation strategies, although little research has been accumulated so far in terms of how to handle and benefit from this situation.
Our validation approach targets the association between a latent subtype label \(L^\) from (5) and a validator V, which can be expressed in a simple form as
$$\begin logit(\pi _})})\,=\,\alpha _ + _\,V_, \end$$
(6)
where \(\pi _})}=Pr(}=1|V_)\) is the probability of person i belonging to the first category of \(}\) as a function of \(V_\).
It is also possible to reverse the direction and use \(}\) as a predictor of \(V_\). For example, in the DirecNet context, it would be more natural to handle the validator (FSIQ) as an outcome predicted by \(L^\) (glycemic control subtype). Assuming a continuous validator, the association between a latent subtype label \(L^\) and a validator V can be expressed in a simple linear model as
$$\begin V_i\,=\,\gamma _ + }_\,L_i^ +e_i, \end$$
(7)
where we assume normal distribution, \(e_ \sim N(0,)\). In this setting, the regression coefficient \(\gamma _L\) is basically a mean shift between the contrasted categories.
We will discuss both directions of validation based on (6) and (7) in the DirecNet application example. The association strength can be assessed using various prediction performance measures. In the DirecNet application, we will use area under the curve (AUC) and Cohen’s d (1988) as measures of association considering both the prediction and inference perspectives. Using Cohen’s d is not common in supervised learning, although useful in inference regarding mean shifts (effect sizes) as in (7). To further enhance our validation, we take into account the uncertainty (generalization error) with K-fold cross-validation (CV). The cross-validated measure of association, \(CV_\), can be obtained for each candidate label as
$$\begin CV_=\sum _^ A_k / K\, \end$$
(8)
where \(k=1,2,..,K\), and \(A_k\) is the association measure for the kth fold. Its standard error can be simply calculated by the squared root of the variance across K folds as
$$\begin SE_= & \sqrt\,/}. \end$$
(9)
In the supervised framework, assessing the association between a subtype label and a validator, as described in (6)–(9), is straightforward. This step has been automated in the validclust module in vclust, which can be used separately or jointly with the genclust module for subtype generation.
3.2.1 Using observed measures as validators
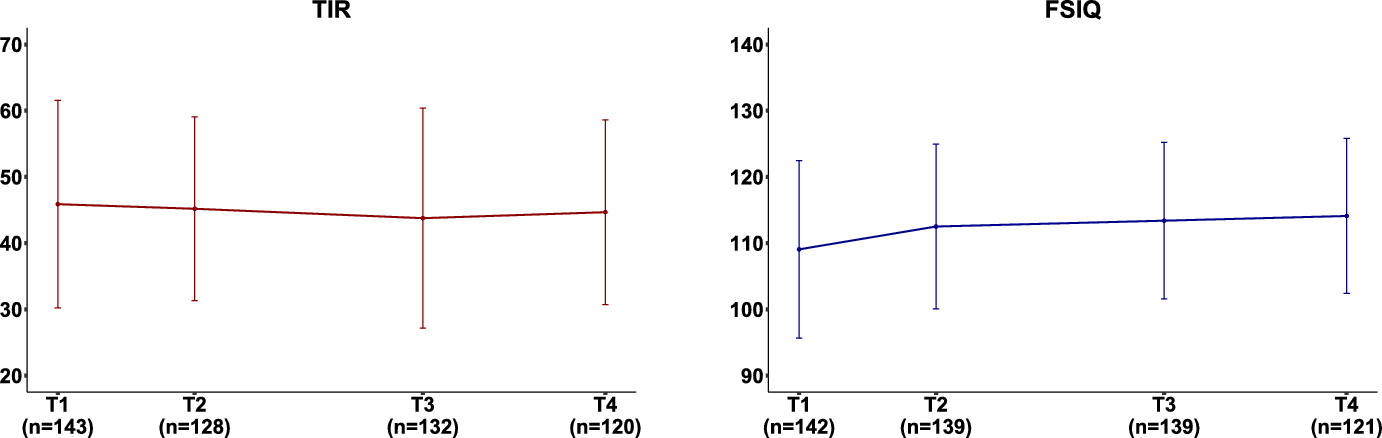
When the validator is longitudinally measured, formulating a validator variable (V) may have several options. One simple way of constructing a validator that represents repeated outcome measures would be to use available observed data. In the DirecNet example, various interpretable summary measures of cognitive development (e.g., baseline, change, scores at certain ages or assessment points) can serve as critical validators of subtype labels of glycemic control. In DirecNet, we are particularly interested in using full scale IQ observed at the last assessment point as a validator given the primary interest in later cognitive outcomes after many years of exposure to different glycemic control patterns.
Although simple, this method comes with common problems involving longitudinal studies. This method utilizes only the cases with complete data, meaning that many cases will be excluded in the validation depending on the definition of a validator (e.g., start, end, change). This method is based on the assumption that the data are missing completely at random (MCAR, Little and Rubin 2002). If the assumption does not hold, the validation results will be subject to bias. This method is also limited in terms of how we can define a validator in the developmental context. For example, in DirecNet, constructing a validator focusing on a particular age (e.g., age 12) will greatly limit the available data (only 14 children aged between 11.5 and 12.5). Despite these limitations, given the unsupervised nature of latent subtypes generated by clustering methods, using a validator that is directly observed is an appealing option. Observed validators are also easy to use in the supervised framework as they do not rely on longitudinal modeling. For these practical reasons, we will focus on observed validators in this study.
3.2.2 Using estimated measures as validators
An alternative way of constructing a validator would be to use estimated quantities, for example, using standard linear mixed effects (LME) modeling with maximum likelihood (ML) estimation. In this method, based on all available data, the ML estimates of the validating outcome (Y) at desired time points can be obtained for all individuals with any observed outcome data. This is possible under the assumption that the data are missing at random (MAR, Little and Rubin 2002). The MAR assumption is weaker than MCAR, although still can be violated. Further, the outcome estimates may be sensitive to other model assumptions and specifications. For example, in modeling Y (e.g., full scale IQ), one debatable choice is whether to use the latent subtype information (e.g., glycemic control type) from the previous step. Ignoring it may bias the association between the subtype label (based on U) and the validator (based on Y). Including it means that U will be involved in generating both the validator and subtype labels to be validated, which is not an ideal situation from the validation point of view. This also means that a series of LME modeling is necessary for Y involving a potentially large pool of candidate subtype labels, which considerably complicates the validation process. Further research is needed on this topic to establish practical guidelines.
3.3 Using latent subtypes in subsequent analyses
The generated and validated latent subtype labels from previous steps are basically ready to be used in subsequent analyses just like any observed categorical variables. However, for more appropriate uses of these subtype labels, one needs to note that the selected labels have been validated based on their targeted purpose or utility. In the DirecNet example shown below, validation is conducted with the goal of identifying glycemic control subtypes that significantly deviate from the healthy control group in terms of cognitive development (represented by full scale IQ). Having the healthy control as a reference group shows our primary interest in inference regarding the heterogeneous impact of having T1D explained by glycemic control subtypes. Improved understanding of the T1D effect in relation to healthy control may have significant implications for both theoretical development and clinical practice. A secondary interest, which is more practically oriented, would be about how well one can predict glycemic control subtypes early on. We will demonstrate and further discuss the proposed approach focusing on the DirecNet example, where the rich longitudinal data collected across various cognitive, brain, and behavioral domains opens up various possibilities of investigation using latent subtype labels.

Comments (0)