
Remember me

This section presents a detailed analysis of the benchmark datasets and describes the approaches used in the proposed CEREBRAL framework (Table 1).
Datasets and Experimental ProtocolThe experimental evaluation employs seven standard benchmark datasets for multimodal emotion recognition, providing comprehensive assessment across diverse recording conditions, emotion taxonomies, and demographic populations. These datasets collectively offer high-quality multimodal recordings (audio, visual, text) for robust emotion classification and affective computing research.
Dataset Overview IEMOCAP (Interactive Emotional Dyadic Motion Capture Database)The IEMOCAP dataset [10] contains 10,039 utterances from 10 actors (5 male, 5 female) engaged in scripted and improvised dyadic conversations. Emotions include happiness, sadness, anger, frustration, neutral, excitement, fear, surprise, and disgust, with multimodal annotations across audio, visual, and text modalities. Recording sessions utilized motion capture, video, and high-quality audio at 16 kHz sampling rate, providing rich multimodal data for emotion analysis.
CMU-MOSEI (Multimodal Opinion Sentiment and Emotion Intensity)A large-scale dataset [27] comprising 23,453 video clips from 1,000 speakers discussing various topics. Annotations include six emotions (happiness, sadness, anger, fear, disgust, surprise) plus sentiment intensity on a 7-point scale. The dataset provides diverse speakers, accents, and recording conditions from online video sources, making it ideal for evaluating generalization across speakers and contexts.
MELD (Multimodal EmotionLines Dataset)The MELD dataset [8] consists of 13,708 utterances from multiple speakers in conversational contexts extracted from the Friends TV series. Annotations cover seven emotions (anger, disgust, sadness, joy, neutral, surprise, fear) with multimodal features including audio (16 kHz), visual (25 fps), and transcribed text with contextual dialogue history, enabling evaluation of conversational emotion recognition.
RAVDESS (Ryerson Audio-Visual Database of Emotional Speech and Song)This dataset [28] contains 7,356 recordings from 24 professional actors (12 male, 12 female) expressing eight emotions (neutral, calm, happy, sad, angry, fearful, disgust, surprised) at two intensity levels. Stimuli include both speech and song with high-quality audio-visual recordings in controlled studio conditions, providing clean data for emotion recognition evaluation.
CMU-MOSI (Multimodal Opinion-level Sentiment Intensity)Comprises 2,199 opinion video clips from 89 speakers with sentiment annotations on a continuous scale from strongly negative to strongly positive. The dataset includes synchronized audio, visual, and text modalities extracted from online product review videos.
CREMA-D (Crowd-sourced Emotional Multimodal Actors Dataset)Contains 7,442 video clips [29] from 91 actors (48 male, 43 female) with diverse ethnic backgrounds expressing six emotions (anger, disgust, fear, happy, neutral, sad) at four intensity levels. Annotations derived from crowd-sourced perceptual evaluations ensure ecological validity.
SAVEE (Surrey Audio-Visual Expressed Emotion)Includes 480 utterances from 4 male actors expressing seven emotions (anger, disgust, fear, happiness, sadness, surprise, neutral). Despite smaller size, the dataset provides high-quality audio-visual recordings with controlled linguistic content across emotion categories.
Multimodal Feature ConfigurationThe datasets provide complementary modalities for comprehensive emotion analysis:
Audio Features: Acoustic features including prosodic patterns (pitch, energy, duration), spectral characteristics (MFCCs, spectrograms), and voice quality measures. CMU-MOSEI provides 74-dimensional audio features extracted using COVAREP [38], while other datasets use comparable acoustic representations capturing vocal emotion cues.
Visual Features: Facial expressions captured through facial action units, facial landmarks, and appearance features. CMU-MOSEI provides 713-dimensional visual features including facial geometry and appearance descriptors extracted from video frames using Facet [39], enabling fine-grained facial expression analysis.
Text Features: Linguistic content encoded through word embeddings, contextual representations, and semantic features. Text modality uses 300-dimensional GloVe [40] or BERT-based embeddings [41] capturing semantic and affective content from speech transcripts.
A complete per-dataset feature configuration table including modality dimensionality, extraction tool, sampling rate, and normalisation applied is provided in the Supplementary Material (Table S1). For CMU-MOSEI and CMU-MOSI, all features follow the standard CMU-SDK pipeline; comparable COVAREP/Facet settings are applied to the remaining datasets for consistency.
Experimental ProtocolThe experimental evaluation follows rigorous validation protocols to ensure reproducibility and fair comparison:
Data Split: Standard train/validation/test splits following established protocols for each dataset, with 70%/15%/15% ratios where official splits are unavailable. Stratified sampling ensures balanced emotion distribution across splits.
Speaker Independence: For IEMOCAP and CMU-MOSEI, speaker-independent partitioning is strictly enforced: no speaker identity appears in both the training and test partitions. For RAVDESS, CREMA-D, and SAVEE, the published actor-disjoint splits are used directly. For MELD and CMU-MOSI, the official predefined splits are followed exactly. These measures prevent identity leakage and ensure that reported performance estimates reflect genuine generalisation.
Cross-validation: 5-fold stratified cross-validation with bootstrap resampling (\(n=1000\)) for confidence interval estimation and statistical significance testing, ensuring robust performance evaluation.
Preprocessing: Standardized preprocessing including feature normalization (z-score standardization), temporal alignment across modalities using force-aligned transcripts, and artifact removal while preserving emotional content.
Evaluation Metrics: Comprehensive metrics including accuracy, unweighted average recall (UAR), weighted average recall (WAR), F1-score, Matthews Correlation Coefficient (MCC), AUC-ROC, and Cohen’s Kappa, providing multi-faceted performance assessment.
The diverse dataset collection ensures robust evaluation across varying recording conditions, emotion taxonomies (4–8 categories), dataset sizes (480–23,453 samples), and demographic populations, enabling comprehensive assessment of CEREBRAL’s generalization capabilities and clinical applicability for real-world emotion recognition systems.
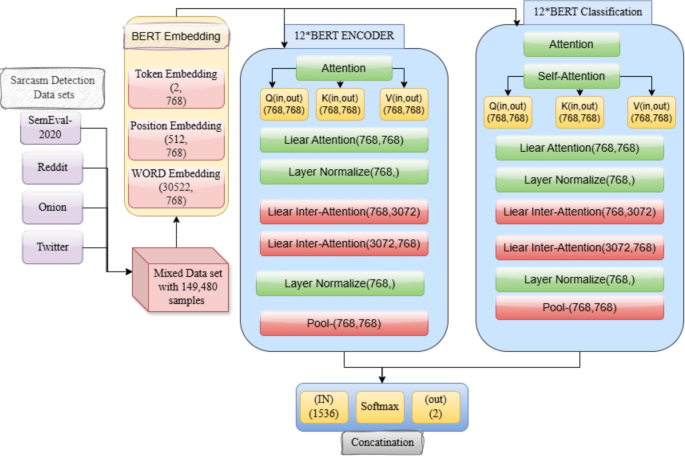
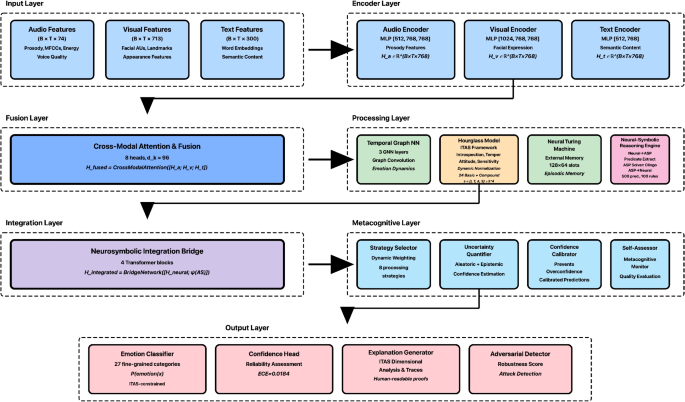
CEREBRAL: Cognitive Emotional Reasoning Engine with Bidirectional Recursive Adaptive LearningCEREBRAL addresses the fundamental challenge of achieving both high accuracy and interpretability in multimodal emotion recognition. Traditional neural approaches excel at pattern recognition but lack psychological grounding and explainability, while symbolic systems provide interpretability but struggle with noisy, real-world data. Our framework bridges this gap through principled integration of neural learning with symbolic reasoning guided by established psychological theories.
Given synchronized multimodal inputs—audio features \(\textbf \in \mathbb ^\), visual features \(\textbf \in \mathbb ^\), and text features \(\textbf \in \mathbb ^\)—where B is batch size and T is sequence length, CEREBRAL processes these through four integrated components: (1) multimodal encoding with cross-modal attention, (2) psychological constraint integration using the Hourglass of Emotions model, (3) bidirectional neural-symbolic reasoning with Answer Set Programming, and (4) temporal modeling with episodic memory mechanisms.
Multimodal Encoding and Cross-Modal AttentionRather than processing modalities independently, CEREBRAL employs unified cross-modal attention to capture the complex dependencies between audio prosody, facial expressions, and linguistic content that collectively express emotions. Modality-specific encoders first project inputs into a shared \(d_=768\) dimensional space, followed by joint attention across all modalities:
$$\begin \begin \textbf_}&= \text \big ([\textbf_a;\ \textbf_v;\ \textbf_t]\big ) \\&\in \mathbb ^}} \end \end$$
(2)
This unified representation captures not just individual modal features but their interactions—for instance, how a smiling face (visual) amplifies positive vocal tone (audio) while reinforcing upbeat linguistic content (text). The attention mechanism with 8 heads enables the model to focus on different types of cross-modal relationships simultaneously [25].
Fig. 4 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.The Hourglass Model of Emotion: Four-dimensional affective space with ITAS dimensions (Introspection, Temper, Attitude, Sensitivity) organized in six sentic levels from positive (top) to negative (bottom), showing 24 basic emotions and their relationships.
Psychological Constraint Integration: Hourglass ModelThe core innovation of CEREBRAL lies in making psychological theories explicit computational constraints rather than implicit learning biases. We implement the Hourglass of Emotions model [23, 24] as differentiable four-dimensional affective constraints that represent the full range of human emotional experiences (Fig. 4).
Hourglass Four-Dimensional Affective SpaceThe Hourglass model organizes emotions along four independent but concomitant affective dimensions: Introspection (joy-sadness axis), Temper (calmness-anger axis), Attitude (pleasantness-disgust axis), and Sensitivity (eagerness-fear axis). Each dimension contains six sentic levels representing intensity gradations, yielding 24 basic emotions. We map fused multimodal representations to this four-dimensional affective space:
$$\begin \textbf&= \text (\textbf_) \in \mathbb ^ \end$$
(3)
where \(\textbf = [s_}, s_}, s_}, s_}]\) represents the sentic vector with each dimension \(s_i \in [-3, +3]\) corresponding to the six sentic levels per dimension.
Sentic Vector Computation with Gaussian TransitionsFollowing the Hourglass model’s biological inspiration, emotional transitions between sentic levels are regulated by Gaussian functions that model how stronger emotions induce higher emotional sensitivity:
$$\begin G(x, \sigma ) = e^}, \quad \sigma = 0.5 \end$$
(4)
The sentic levels for each dimension are defined through Gaussian-weighted intervals:
$$\begin \begin \mathcal _}&= \sum _} \text (s_d, \sigma ) \\&\quad + \lambda _} \mathcal _} \end \end$$
(5)
$$ \mathcal = \big \,\ \text , \text ,\ \text \big \} $$
and \(\mathcal _}\) enforces dimensional independence while allowing concomitant activation (Fig. 5).
Fig. 5 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Comprehensive mapping of emotions across the four ITAS dimensions with six sentic levels each. Each dimension contains six sentic levels ranging from highest intensity (leftmost) to lowest intensity (rightmost): Introspection (ecstasy to grief), Temper (bliss to rage), Attitude (delight to loathing), and Sensitivity (enthusiasm to terror)
Table 2 Neural-Symbolic mapping examples with Hourglass dimensions Polarity Computation with Dynamic NormalizationThe Hourglass model defines polarity through the four affective dimensions with dynamic normalization based on active dimensions [24]:
This formula employs dynamic normalization where the denominator counts the number of active dimensions, ensuring that single-dimensional emotions (e.g., grief with only negative Introspection) maintain full polarity intensity, while multi-dimensional compound emotions receive appropriate normalization based on their dimensional complexity (Table 2).
Compound Emotion DetectionThe Hourglass model naturally supports compound emotions through multi-dimensional activation patterns. Bidimensional emotions arise from pairwise dimension combinations:
$$\begin \text &\Leftarrow s_}> 0 \wedge s_}> 0 \nonumber \\ \text &\Leftarrow s_}> 0 \wedge s_}> 0 \nonumber \\ \text &\Leftarrow s_} < 0 \wedge s_} > 0 \end$$
(6)
Tridimensional and tetra-dimensional compound emotions like pride (Introspection + Attitude + Temper), shame (negative Introspection + Attitude + Sensitivity), and jealousy (all four dimensions active) emerge from higher-order dimensional combinations, enabling nuanced emotional representations.
Neural-Symbolic Reasoning IntegrationPure neural networks lack interpretability and logical consistency. CEREBRAL addresses this through bidirectional neural-symbolic integration using Answer Set Programming (ASP) [20], enabling explicit logical reasoning within a hybrid training scheme. The neural components (multimodal encoders, cross-modal attention, predicate extractor, bridge network, and classifier) are trained end-to-end via backpropagation using the objective in (10). The ASP solver (Clingo) is non-differentiable; a stop-gradient operation is applied at the neural-to-symbolic conversion boundary (7), so no gradient flows through the solver. Fixed rules \(\mathcal _\) encode the Hourglass model structure and remain unchanged throughout training. Dynamic rules \(\mathcal _\) are updated offline every \(K=50\) training steps via a supervised symbolic consistency objective. The symbolic-to-neural bridge (9) is fully differentiable, enabling downstream gradient flow through the symbolic integration module. This design follows established neurosymbolic training practice [51, 52].
Neural-to-Symbolic ConversionContinuous neural representations are converted to discrete logical predicates through learned extraction with confidence thresholding:
$$\begin \mathcal &= \_i \mid \sigma (\textbf_i^T \textbf_) > \theta _\} \end$$
(7)
where \(\theta _=0.7\) filters uncertain activations, ensuring only high-confidence patterns contribute to logical reasoning. This produces facts like feeling_introspection_joy, high_temper_anger, compound_love that form the foundation for symbolic inference based on Hourglass dimensions.
Answer Set Programming for Logical InferenceThe ASP solver combines extracted facts with Hourglass-based psychological constraint rules to derive consistent emotion interpretations:
$$\begin \mathcal\mathcal&= \text (\mathcal , \mathcal _ \cup \mathcal _) \end$$
(8)
where \(\mathcal _\) encodes fixed Hourglass model rules (dimensional independence, sentic level relationships, compound emotion patterns, polarity constraints) and \(\mathcal _\) contains learned rules adapted to specific inputs. The solver generates stable models representing logically consistent emotion interpretations with explicit proof traces.
Symbolic-to-Neural IntegrationAnswer sets are converted back to neural representations and integrated with the original neural pathway through deep fusion:
$$\begin \textbf_&= \text ([\textbf_; \psi (\mathcal\mathcal)]) \end$$
(9)
where \(\psi (\cdot )\) maps symbolic answer sets to dense vectors. This bidirectional integration enables neural patterns to inform symbolic reasoning (bottom-up) while symbolic constraints guide neural processing (top-down), ensuring both accuracy and interpretability.
Temporal Dynamics and Memory MechanismsEmotions evolve temporally with context-dependent transitions. CEREBRAL models these dynamics through graph neural networks that capture emotion evolution patterns in the four-dimensional Hourglass space, combined with Neural Turing Machine [12] memory for maintaining emotional context across extended sequences. The temporal component enforces smoothness while allowing genuine emotion transitions supported by multimodal evidence and Gaussian-regulated intensity changes [50].
Training Objective and IntegrationThe complete training objective balances emotion classification accuracy with Hourglass model consistency:
$$\begin \begin \mathcal _}&= \mathcal _} + \lambda _1 \mathcal _} \\&\quad + \lambda _2 \mathcal _} + \lambda _3 \mathcal _} + \lambda _4 \mathcal _} \end \end$$
(10)
where \(\mathcal _\) is cross-entropy loss over 27 fine-grained emotion categories, \(\mathcal _\) enforces correct polarity computation via (1), \(\mathcal _\) ensures valid compound emotion detection, and constraint weights \(\lambda _1=0.1\), \(\lambda _2=0.1\), \(\lambda _3=0.05\), \(\lambda _4=0.05\) enforce psychological consistency without overwhelming the primary objective.
Label Harmonisation Across DatasetsCEREBRAL’s internal classifier operates over 27 fine-grained emotion categories: the 24 Hourglass basic emotions (six sentic levels across each of the four ITAS dimensions) plus three representative compound emotions—love, pride, and jealousy—selected to span bidimensional, tridimensional, and tetradimensional activation respectively. A dataset-specific linear projection head, trained jointly with all other network parameters, maps this internal distribution to each dataset’s target label taxonomy. The mapping is structurally determined by Hourglass dimensional affinity: positive-Introspection categories (ecstasy, joy, contentment) map to happy; negative-Introspection (grief, sadness, melancholy) to sad; negative-Temper (rage, anger, annoyance) to angry; negative-Sensitivity (terror, fear, anxiety) to fearful; negative-Attitude (loathing, disgust, dislike) to disgust; and near-zero activations across all dimensions to neutral or calm. For binary sentiment classification (CMU-MOSI), the dynamic polarity formula in (1) directly determines the output class. A single unified model with shared parameters and dataset-specific output heads is trained jointly; no separate per-dataset models are used. This hierarchical mapping preserves the rich internal Hourglass representation while enabling evaluation against each dataset’s native label taxonomy.
The framework learns to recognize emotions while respecting the Hourglass model’s principles of dimensional independence, sentic level organization, and compound emotion formation, producing both accurate predictions and interpretable reasoning traces.
Key Innovation SummaryCEREBRAL’s distinguishing features include (1) explicit Hourglass model constraints as computational components enabling four-dimensional affective representation with Introspection, Temper, Attitude, and Sensitivity dimensions, (2) bidirectional neural-symbolic integration enabling both pattern learning and logical reasoning with psychological grounding, (3) interpretable decision traces through ASP proof generation following Hourglass principles, and (4) unified handling of basic emotions, compound emotions, and polarity within the biologically-inspired Hourglass framework with dynamic normalization (Table 3).
Table 3 Core predicate categories in CEREBRAL knowledge base (Hourglass-Based) Hourglass Model Psychological Constraint RulesThe ASP program encodes the Hourglass model as logical constraints organized into four main categories:
 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI. The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI. The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI. The alternative text for this image may have been generated using AI.Algorithm 1
The alternative text for this image may have been generated using AI.Algorithm 1 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Neural-to-Symbolic Predicate Extraction with Hourglass Dimensions.
Algorithm 2 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Symbolic-to-Neural Feature Conversion.
Fig. 6 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Neurosymbolic reasoning pipeline for pride detection showing complete four-stage process with Hourglass dimensional analysis
Table 4 Neural-Symbolic mapping examples with Hourglass dimensions Implementation DetailsThe complete architecture contains 24.1M parameters with modality encoders using 3-layer MLPs (AudioEncoder: [512,768,768], VisualEncoder: [1024,768,768], TextEncoder: [512,768]), cross-modal attention with 8 heads and \(d_k=96\), Hourglass model module with 4-dimensional sentic vector computation (Introspection, Temper, Attitude, Sensitivity), dynamic polarity normalization, and compound emotion detection, and ASP integration using the Clingo solver [44] with average solving time 4.91ms. Training employs Adam optimization with learning rate \(1\times 10^\), batch size 32, and early stopping based on validation accuracy. The complete CEREBRAL implementation, including all ASP rule sets (\(\mathcal _\), \(\mathcal _\)), preprocessing pipelines, training configurations, and model checkpoints, will be released at a public repository upon acceptance to support full reproducibility (Fig. 6).
Evaluation Framework Performance MetricsClinical assessment employs comprehensive diagnostic metrics:
$$\begin \text &= \frac + \text } + \text + \text + \text } \end$$
(11)
$$\begin \text &= \frac} + \text }, \quad \text = \frac} + \text } \end$$
(12)
$$\begin \text &= \frac \cdot \text } + \text } \end$$
(13)
$$\begin \text &= \frac\sum _^C \frac_c}_c + \text _c} \end$$
(14)
$$\begin \text &= \frac \cdot \text - \text \cdot \text }+\text )(\text +\text )(\text +\text )(\text +\text )}} \end$$
(15)
where TP, TN, FP, FN represent true positives, true negatives, false positives, and false negatives respectively, and C is the number of classes (Table 4).
Validation StrategyFive-fold stratified cross-validation ensures robust evaluation with balanced emotion distribution across folds. Bootstrap resampling with \(n=1000\) iterations provides confidence interval estimation through sampling with replacement. Statistical significance is assessed through paired t-tests comparing CEREBRAL against baseline methods, with Bonferroni correction for multiple comparisons (corrected \(\alpha = 0.05/k\) where k is the number of comparisons). Cross-dataset generalization is evaluated by training on one dataset and testing on others, measuring performance degradation and transfer learning effectiveness across diverse recording conditions and emotion taxonomies.
Comments (0)