
Remember me
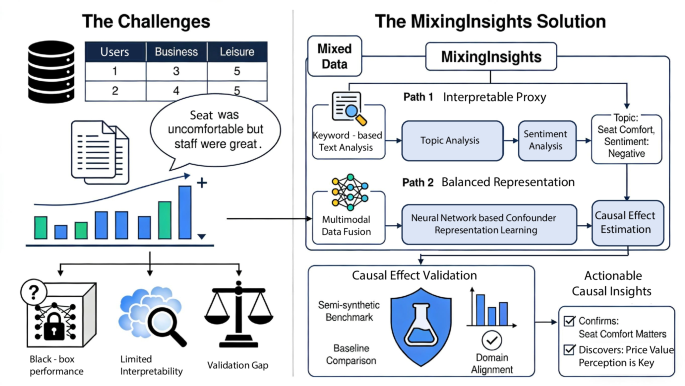
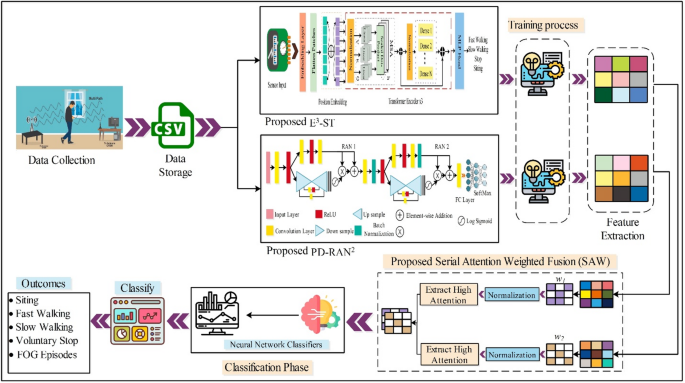

The proposed framework for classifying PD using WiFi Signals has been presented in this Section. Figure 1 presents the methodology of the proposed PD classification framework. In the initial step, the dataset is acquired and prepared in the CSI file (as discussed in the dataset section). After that, the proposed E3-ST and PD-RAN2 models are designed. The prepared datasets are fed to the developed model for training. After training, the models are used for feature extraction during testing, and the resulting information is later fused using a new serial attention-weighted method. After fusion, classification is performed using several methods, each applied in turn. A detailed description of each step is given in the subsections below.
Fig. 1 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Proposed framework based on deep learning for the classification of PD using WiFi signals
Dataset CollectionThis research used a dataset from an experimental protocol to examine variations in CSI resulting from multiple human activities, including freezing of gait (FOG) episodes [50]. Fifteen participants were recruited, with ten completing four activities considered normal, including slow walking, fast walking, voluntary stopping, and sit-to-stand transitions. The five remaining participants had clinically identifiable FOG episodes. Activities were completed in a randomized order among participants to ensure randomness and minimize potential bias. Data collected from the five participants who had FOG episodes were used to develop the ground truth, which was later used to train, validate, and benchmark models. The experimental protocol was designed to elicit perturbations in the wireless medium reflecting the intentional disturbances to the airways caused by various activities. These perturbations permitted the CSI signal to register minute variations in response to the activity being performed. These variations were further examined for potential capabilities to differentiate FOG episodes from activities that represent normal routines. The data collection section aimed to develop representative CSI signals that could reliably identify and classify FOG episodes in individuals living with Parkinson’s disease.
The wireless sensing system used a line-of-sight configuration comprising a WiFi transmitter (\(\:Tx\)) and a WiFi receiver (\(\:Rx\)). The \(\:Tx\) module transmitted a signal at 4.8 GHz, within the C-band, which includes frequencies typically used in 5G and even IoT-based applications. The \(\:Rx\) used an omnidirectional antenna connected to the Intel 5300 wireless network interface in a standard laptop running Ubuntu 14.10 OS, with 8 GB RAM. The CSI data obtained at the receiver was sent to a desktop workstation for post-processing and feature extraction. Because both \(\:Tx\) and \(\:Rx\) operate in the same frequency spectrum, this provided some channel consistency and improved signal fidelity. Mathematically, the acquired CSI dataset can be represented as:
\(\:X\:=\:\left\_,\:_,\:\dots\:,\:_\right\},\:\:\:__\in\:\:}^\), where \(\:X\) is the set of CSI samples, ? is the total number of collected observations, and ? represents the number of features per sample. To reduce channel noise and ensure comparability across subjects, each CSI vector \(\:_\) is normalized as:
$$\begin \stackrel\text=\frac-\mu\right)},\\mu=\left(\frac\right)\sum_^x\text,\\\sigma=\sqrt\right)\sum_^-\mu\right)}^} \end$$
(1)
Where µ and σ are the mean and standard deviation of the dataset, respectively, this preprocessing ensures that the input signals are standardized, highlighting activity-induced perturbations in CSI values while suppressing irrelevant fluctuations. Each CSI sample was labeled according to its corresponding activity, yielding five distinct labels. The scheme for labeled encoding and distribution of the sample rate is shown in Table 1.
Table 1 Dataset classes and label encoding descriptionProposed E3-STSensor Transformers are specialized transformer models designed to analyze and process sensor data. Sensor data is treated as a sequence, and each data point and feature vector is considered a “token”. These bindings are passed through the transformer encoder, which uses self-attention mechanisms to capture local and global dependencies over the sequence. The model can adapt to a range of tasks, including classification, regression, and forecasting. This approach is practical for PD classification, activity detection, and health monitoring applications. Sensor transformers focus on extracting meaningful patterns from sequential data and offer flexible, robust alternatives to traditional models, such as CNNs and RNNs, for analyzing sensor data. The motivation for the E3-ST model is that it uses an encoding process comprising three progressive phases. The attention heads and dropout rates vary across phases to capture both local and global relationships within the CSI sequence. This gives the model the ability to create an environment to generalize from the data. Furthermore, the E3-ST model uses convolutional operations throughout all encoder phases, which distinguishes it from standard transformer models. In addition, the E3-ST provides stability for learning in the presence of signal noise via residual connections.
In this work, we designed a new E3-ST transformer based on a three-stage encoding scheme for Parkinson’s disease classification. The proposed network starts with a feature input layer of 200 features. First, the raw feature vector x is mapped into an embedding space and enriched with positional encoding: \(\:_\:=E\left(x\right)+P\left(x\right)\) where E(⋅) denotes the embedding function and P(⋅) represents positional encoding that preserves sequential information. After the mapping, the embedding layer converts the input into tokens. The first encoder starts with the position embedding layer; consider \(\:_\in\:}^\). The embedding layer is defined as\(\:_=\left(_\right)\), and the position embedding layer is formulated as\(\:_=_+\kappa\:\left(_\right)\), where \(\:\kappa\:\left(_\right)\) encodes the positional information. A dropout activation is employed with a dropout factor of 0.2, where\(\:_=_\left(_,0.2\right)\). Afterward, batch normalization is added to improve the convergence, which is defined as \(\:_=}_\left(_\right)\). A multi-head self-attention layer is employed to concurrently attend to multiple data chunks and to enable learning long-range dependencies and correlations. The operation of multi-head self-attention is \(\:_\left(Q,K,V\right)=\tau\:\left(\frac^}_}}\right)V\), and concatenates the outcomes from heads, which are \(\:3\), and applies a linear transformation presented with\(\:\:_\left(Q,K,V\right)=\bigcup\:\left(_,_,\dots\:,_\right)\psi\:^\circ\:.\).
After that, a dropout layer with a dropout factor of 0.2 is connected to the output of the multi-head self-attention layer. Later, a residual connection is employed using the given equation \(\:_\text=_+_\). In the next step, the convolutional and GELU activation operations use\(\:__\left(\left(_\right)\right)\). A dropout activation with a rate of 0.2 is applied to the GELU output. Furthermore, a convolutional operation is applied using \(\:_=\left(_\right)\) and a connected addition layer to create the second residual connection. The second residual block is created by adding a skip connection from the first residual block to the last convolutional layer. This operation is presented as \(\:_=\:_\oplus\:_\).
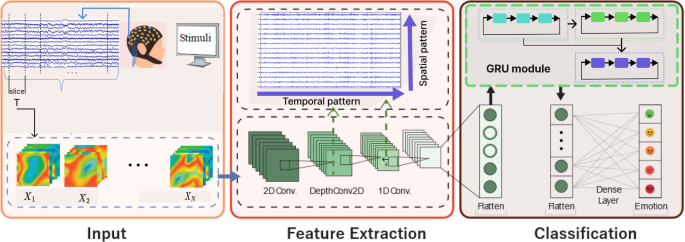
The second and third encoder stages are constructed using the same mechanism, but with varying attention heads \(\:(h=\text)\:\)and dropout factors \(\:\left(\text\right)\) to balance feature diversity and robustness. Finally, the output from the third encoder stage is passed through a multi-layer perceptron (MLP) head for classification. The final class probabilities are computed using the softmax function:\(\:\:\widehat=softmax\left(_\:_^+_\right)\) where \(\:\widehat\) represents the predicted probability distribution across Parkinson’s disease activity classes (slow walking, fast walking, sitting, standing, and FOG episodes). The model is trained by minimizing the categorical cross-entropy loss: \(\:L=\:-\:\sum\:_^\sum\:_^_\text}_\), where \(\:_\) is the ground-truth one-hot encoded label and \(\:}_\) is the predicted probability for class c. In total, the proposed E3-T has 42 layers, three multi-head self-attention modules, and 1.6 M total trainable parameters. The proposed network is trained using a training data chunk on the selected dataset. The features are extracted from the trained model using the test data, and the extracted features have dimension \(\:N\times\:192\). The entire architecture is presented in Fig. 2. This figure shows that the sensor’s input data is passed to the proposed network, which is trained with an MLP head and returns output classes for fast walking, slow walking, stop, and sitting.
Fig. 2 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Architecture of the proposed E3-T transformer for the classification of Parkinson’s disease
Proposed PD-RAN2The motivation behind the PD-RAN2 architecture is its residual attention, which employs both an adaptive method and a skip connection to identify the most salient regions within a signal while preserving the signal’s raw feature representation. This method differs from conventional techniques for creating attention networks because multiple branches of attention are synthesized through progressive up- and down-sampling, affording it substantial advantages for identifying feature characteristics and recognizing patterns from CSI data. The residual attention mechanism combines the strength of residual connections and the attention mechanism to focus on the most relevant chunks of data while preserving original information. Unlike traditional networks that process data uniformly, residual Attention uses attention mechanisms, such as channel-wise attention, to dynamically identify and enhance critical features. By selectively improving key patterns while preserving the overall structure of signals, residual attention networks improve task performance, such as classification.
In this work, we designed two residual Attention block-based networks, PD-RAN2, to classify Parkinson’s disease. The PD-RAN2 accepts the input size of dimension \(\:200\times\:1\) from the input feature layer. After that, a convolutional layer with three filter size \(\:s,\:two\:\)strides, and \(\:16\:\)depths is added, followed by a ReLU activation to introduce non-linearity in the network. After that, the first residual attention module starts with the other two branches; the first branch has two convolutions with a filter size\(\:\:of\:\text\), a stride of \(\:\text\), a depth of\(\:\:\text\) , and one ReLU activation. The other branch contains the convolutional configurations with three filter sizes, \(\:two\:\) strides, and \(\:32\:\) depths to downsample the feature map and transpose the convolutional configuration for the upsampled feature map. A sigmoid function is employed, and element-wise multiplication is performed with the first branch. The first branch is added with the outcome of the multiplication layer. The mathematical formulation of the residual attention module is defined as follows:
Consider an input feature map of \(\:f\in\:}^\) that was obtained from the previous layers.
$$_\left(f\right)}_=}__*f+_)$$
(2)
$$_\left(_\left(f\right)}_\right)}_=_*_\left(f\right)}_+_$$
(3)
$$_\left(f\right)}_=_*f+_$$
(4)
$$_\left(}_}_\right)}_=_^*_\left(f\right)}_+_$$
(5)
$$}_}_=\sigma\:\left(_.ReLU\left(w._\left(f\right)}_+b\right)+_\right)$$
(6)
$$_=_\left(_\left(f\right)}_\right)}_\odot\:}_}_$$
(7)
$$_=_⨁_\left(_\left(f\right)}_\right)}_$$
(8)
Where \(\:f\) is the feature map, \(\:_,_,_\) are the convolutional weights, \(\:_,_,\:and\:_\) are the convolutional biases, \(\:_^\) is the weights of the upsampling convolutional operation, \(\:_\) is the attention weights matrix, \(\:\odot\:\) represents the element-wise multiplication, and\(\:\:⨁\) is the addition operation, respectively. After the first module, a convolutional layer, batch normalization, and ReLU activation are used, followed by a second residual attention module, which is updated with one more batch normalization layer. Moreover, an additional convolutional layer is added. In the end, a fully connected layer and a softmax layer are used for classification. The mathematical definitions of these layers are:
$$_=Softmax\left(_._\left(_\right)+_\right)$$
(9)
$$_=\frac^_,c\right)}}^^_,z\right)}},\:z=\text,3,\dots\:,C$$
(10)
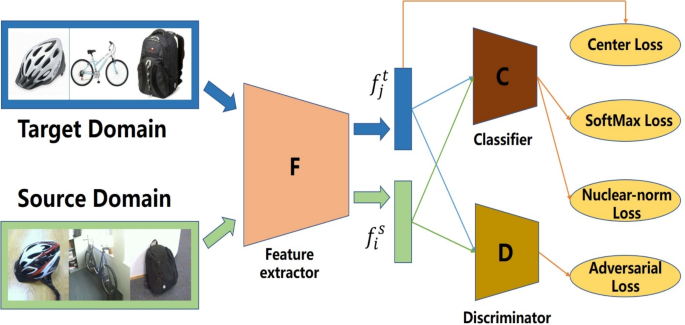
Where the \(\:_\in\:}^\) represents the class probabilities for \(\:C\) classes, the proposed PD-RAN2 has 32 layers with 1.2 M parameters. The designed model is trained on the training data and validated during training using the validation data. The features are extracted from the deep convolutional layer using the test data, and the extracted features have size \(\:N\times\:1024.\:\)A systematic architecture is presented in Fig. 3. This figure shows that the input layer feeds into the designed network, which ends with a softmax layer for final classification.
Fig. 3 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Systematic architecture of proposed PD-RAN2 for Parkinson’s disease classification
Models Training and Features ExtractionAfter designing both models, training was performed on the selected database. A few hyperparameters are also initialized to train this model, such as initial learning rate, momentum, batch size, and dropout factor. Usually, these parameters are selected manually (brute-force); however, this is not a good idea because these hyperparameter values control the network training. Therefore, it is essential to initialize the hyperparameter using an optimization algorithm. The purpose of hyperparameter optimization is to minimize prediction error and maximize training accuracy. In this work, we utilized Bayesian Optimization [51] to select hyperparameter values. The hyperparameter range is given in Table 2. After selecting the best value, the model is trained and later used for feature engineering. In the feature engineering process, features are extracted, and the obtained vectors for these models are \(\:N\times\:192\) and \(\:N\times\:1024\), respectively. These features are fused using a serial attention-weighted fusion (SAW) technique, as described in Sect. 3.4.
Table 2 Hyperparameter selection using Bayesian OptimizationFigures 4 and 5 provide the information on the training and validation performance of the proposed E3-ST and PD-RAN2. For E3-ST, there is a clear and consistent increase in both training & validation accuracy from approximately 35% to almost 99% over time, with almost no difference (very little gap) between the two different curves throughout this experiment. This close relationship provides strong evidence of excellent generalization during training. The loss curves for both training & validation were also very smooth, with a continual decline toward very low values, demonstrating stability during optimization and successful learning. For PD-RAN2, training accuracy increased rapidly during the initial epochs, reaching almost 99%; however, there was noticeable overfitting. Validation accuracy is lower than training accuracy at the midpoint of the experiment. In addition to a continuous decline in both training & validation loss, the numerical gaps between them are much larger than in E3-ST throughout most of the first and mid-training periods. They will lower toward the end of the experiment.
Fig. 4 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Training validation curves of the proposed E3-ST
Fig. 5 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Training validation curves of proposed PD-RAN2
Proposed Serial Attention Weighted Fusion (SAW)Combining features from different sources into a single source is called feature fusion [52]. In this study, we proposed a new fusion technique, Serial attention-weighted fusion (SAW), combining the most prominent features. The purpose of this fusion technique is to select the most important features and combine the most prominent ones for further classification. Mathematically, the formulation of this process is defined as follows:
Consider two feature vectors obtained from the proposed E3-T and PD-RAN2 with dimensions of \(\:_\in\:}^_}\:and\) \(\:_\in\:}^_}\), where\(\:\:\alpha\:\) is the number of samples and \(\:_\) and \(\:_\) are extracted features—the values of \(\:_=192\) \(\:and\:_=1204\). The initial step calculates the attention value for each feature using Eq. (11).
$$_\left(k\right)=\left|\omega\:\left(k\right)\right|\:\:,\:\:\:\:\:\:\:\:k=\text,3,\dots\:,\:\beta\:$$
(11)
After that, standard normalization is used to scale the attention values to the range \(\:\left[\right]\)0,1, and a threshold is applied to the normalized Attention to select the top features. This operation is performed by using Eqs. (12–14).
$$}_\left(k\right)=\frac_\left(k\right)}\left(_\right)}$$
(12)
$$__}=\left\}_\right(k)>\theta\:\right\}$$
(13)
$$__}=\left\}_\right(k)>\varphi\:\right\}$$
(14)
Where \(\:\omega\:\) is the Attention weights matrix for \(\:_\) and\(\:_,\) \(\:}_\left(k\right)\) is the standard normalization outcome for \(\:_\) and\(\:_\), and \(\:__}\)and \(\:__}\) indicate the high attention values indices. After that, the feature values are computed from the close attention indices of the original vectors using Eqs. (14–15)—the dimensions of the gained features from \(\:_\)=114 and \(\:_=976\), respectively. In the last step, the obtained high-attention features from both original vectors are combined using the serial method, as defined in Eq. (17).
$$_=_\left(:,__}\right)$$
(15)
$$_=_\left(:,__}\right)$$
(16)
$$_}_=_\\\:_\end\right]}_$$
(17)
Where \(\:_\) and \(\:_\) are obtained, great attention feature vectors, and \(\:_}_\) is the outcome of the serial method. The final output of this method is\(\:\:\alpha\:\times\:1090\). After the fusion, the resulting feature vector is passed to multiple neural network classifiers for final-phase classification.
Comments (0)