
Remember me
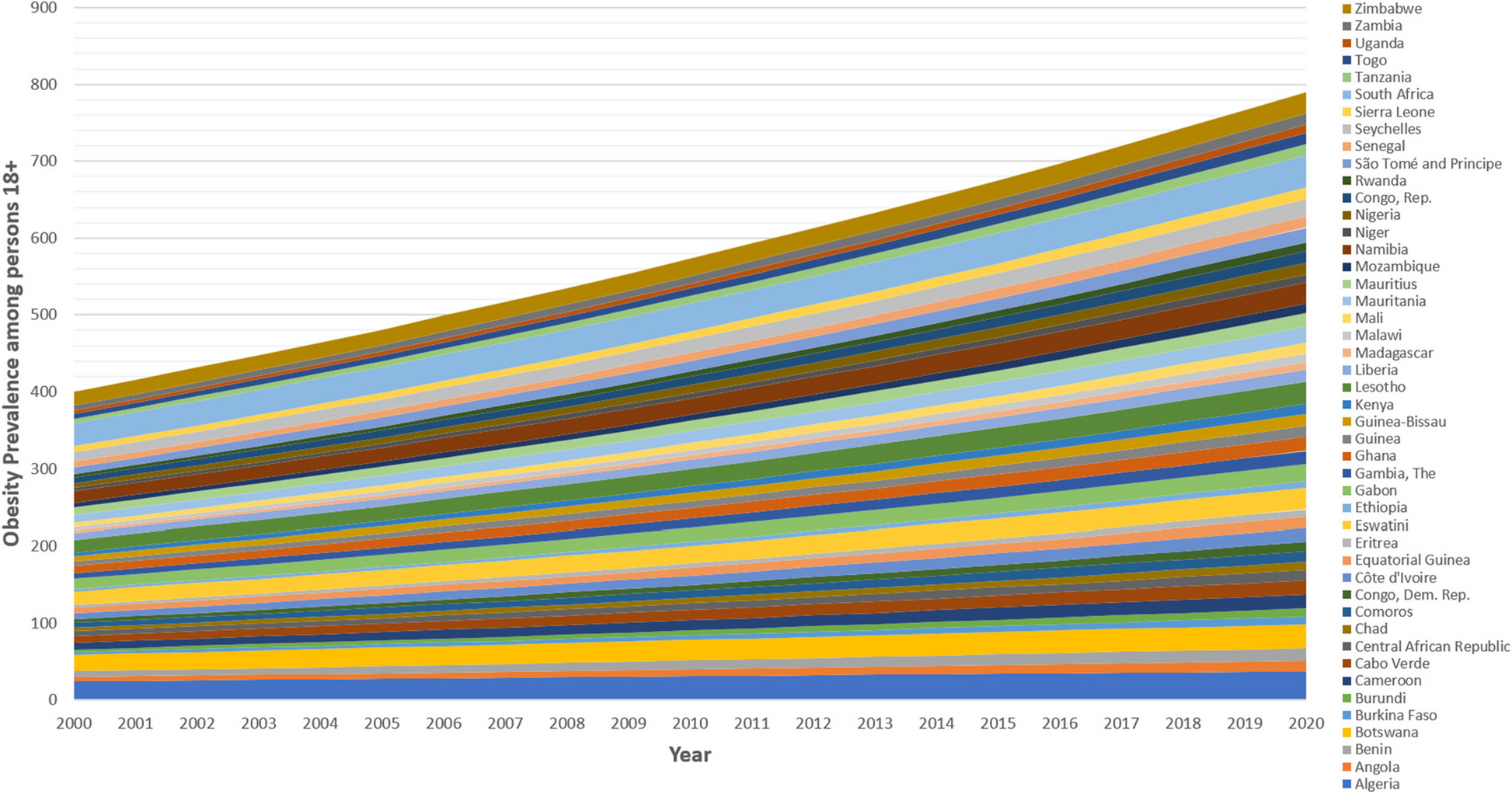





The rising prevalence of obesity has emerged as a significant public health concern globally particularly in developing nations such as those in Africa. Understanding the factors contributing to this phenomenon is crucial for developing effective interventions. To achieve the study’s objective, a quantitative research design specifically panel data design, which is ideal for analyzing multiple countries over time is employed. This approach allows the examination of how obesity rate evolves in relation to economic growth and other factors over an extended period. The panel data design ensures that the analysis can capture both cross-sectional (across different countries) and temporal (over time) variations in obesity rates and the factors influencing them. The study’s design spans 20 years (from 2000 to 2020), which is significant for capturing long-term trends and understanding the temporal dynamics between economic development and obesity. The time period was chosen because it captures a period of rapid change in many African countries. Economic growth, trade liberalization and urbanization accelerated during this time, creating a shift in dietary patterns and lifestyle choices, both which are major contributors to rise in obesity rates. A key feature of the design is the regional panel structure, where data is divided into four distinct regional groupings: Eastern, Western, Central and Southern Africa.Footnote 1 This regional breakdown is crucial because each part of Africa has different socio-economic, cultural and environmental contexts that may influence obesity prevalence in different ways. The study specifically tests the OKC hypothesis, which posits an inverted U-shaped relationship between economic growth and obesity prevalence. This hypothesis suggests that, as countries become wealthier, obesity rates initially rise due to an increase in food availability and lifestyle changes, but eventually decrease once a certain threshold of economic development is reached, where people adopt healthier diets and lifestyles. This framework is applied across the four regions to examine whether this pattern holds true in Africa. To analyze the data the study uses recent panel econometric techniques which are particularly well-suited to the study because they account for cross-sectional dependence and heterogeneity in the panel data—two issues that are common when working with data from multiple countries that may be influenced by similar global or regional factors. Additionally, the study incorporates gender-specific analysis, separating the data on obesity prevalence for both sexes jointly together with males and females separately. These distinctions are vital because obesity patterns often vary between men and women due to factors such as differing socio-cultural pressures, lifestyle habits, and biological differences in weight gain and fat distribution. This approach thus ensures a nuanced understanding of how economic growth and other factors affect obesity prevalence differently for men and women across Africa.
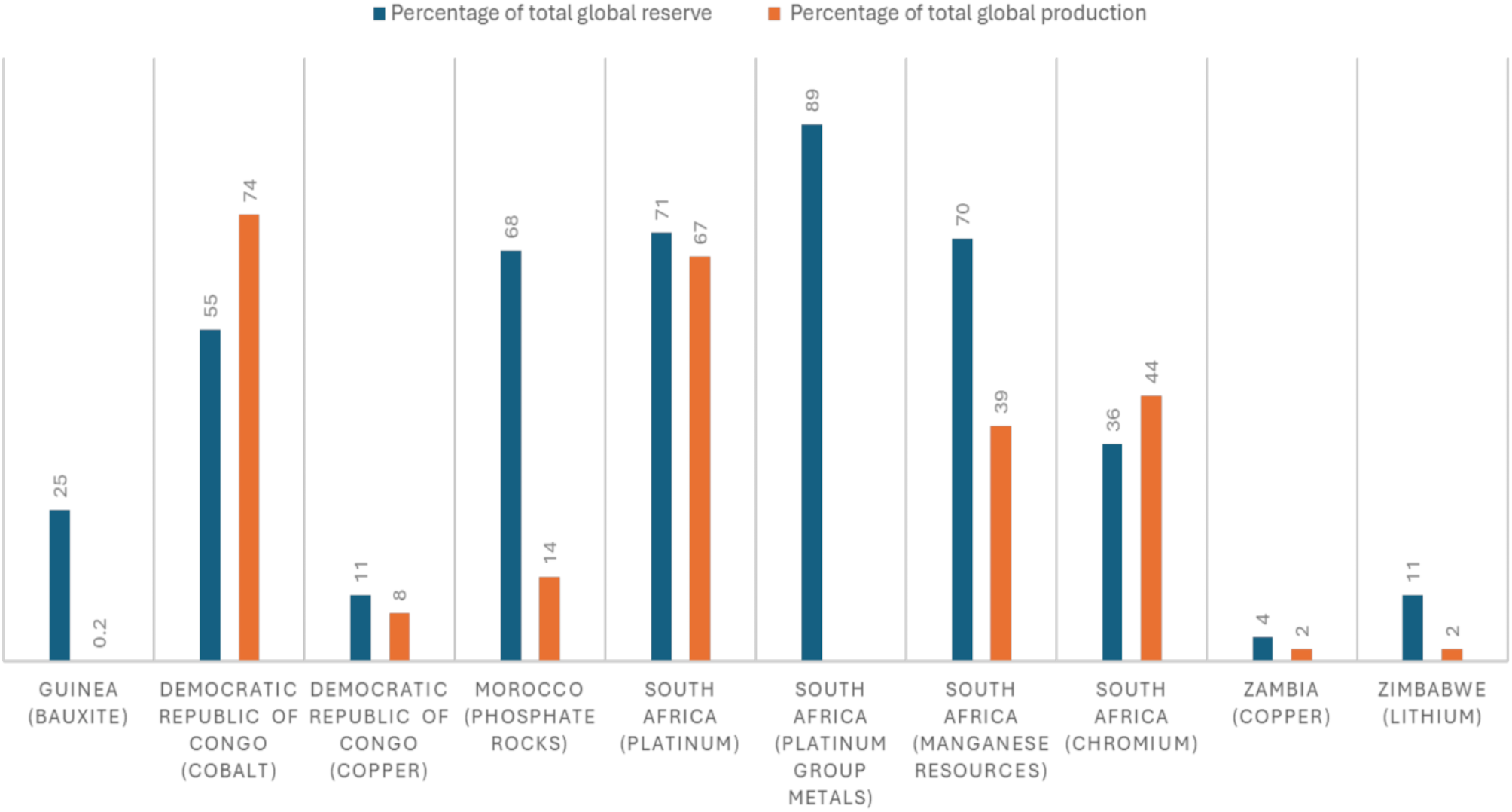
Moreover, the setting of the study focused on African nations. This focus on Africa is significant given the rapid economic transitions and urbanization occurring in many African countries, which are contributing to increasing rates of obesity. The African continent provided a unique setting for this study, as it is home to a growing middle class, an expanding urban population, and changing food systems, all of which may influence the rising prevalence of obesity. By focusing on Africa, the study addresses the unique socio-economic and public health challenges faced by the region. African countries are in varying stages of economic development, and while some experiencing rapid growth and urbanization, others are still grappling with poverty and undernutrition. As such, the study aims to shed light on how these divergent trajectories affect the prevalence of obesity, particularly in the context of the double burden of malnutrition—where undernutrition and obesity coexist. Notably, the study units consist of African countries analysed within the framework of regional groupings and differentiated by gender for obesity prevalence. Specifically, the study uses data from 46 African nations that meet the criteria for inclusion based on data availability, particularly regarding obesity prevalence and other socio-economic indicators which includes economic growth, trade openness, urbanization, and food production. As already indicated, the sample of African countries utilized are grouped into four regional panels within the Western Africa panel consisting of 16 countries, Eastern panel containing 10 countries whereas the Central and Southern regional panels consist of 8 and 12 countries correspondingly.Footnote 2 This classification ensures that the study captures regional variations in obesity trends which are influenced by different levels of economic development, urbanization, trade patterns and food systems. Overall, the study does not focus on individual-level data (such as personal health surveys or household-level surveys) but instead analyses an annual national-level data aggregated by region. This approach allows the study to identify macro-level trends and patterns that are influenced by national policies, economic shifts, and public health interventions. By aggregating the data at the regional level, the study is able to highlight structural and policy-driven factors that contribute to obesity such as trade policies, food production systems and urbanization patterns, which affect large populations across these regions.
Table 1 Variables description and data sourcesDataThis study utilized a panel time series data of African countries which spans from 2000 to 2020. The study utilised strongly balance panel data with no missing values sourced from updated international sources. The main data sources are the World Health Organization (WHO), Global Health Observatory Database and the World Bank Development Indicators (WDI). These sources ensure the reliability and consistency of the data across countries and over time, providing a robust foundation for the analysis. Specifically, the data extracted from the mentioned sources are with respect to the variables which includes, obesity prevalence, economic growth, trade openness, food production and urbanization. To ensure data quality, the data underwent a thorough review by the authors, who cross-checked the variables used to ensure consistency across different time periods and countries. Internal consistency checks were also conducted to confirm that the variables were logically related and that there were no contradictions in data across the countries selected. In terms of tools used for data verification and quality control, statistical software which include STAT 17.0 was employed. This tool enabled us to perform data consistency checks and ensure that the data met the necessary assumptions for dynamic panel data analysis. Furthermore, given the panel nature of the data, additional checks to ensure that the data was suitable for econometric modelling was conducted. These included that testing for stationarity, and cointegration of variables as well conducting cross-sectional dependence test to ensure that the data met the assumptions required for dynamic panel data models. By following these steps for the data verification and employing the appropriate tools, the study ensured that the data used in the analysis was both reliable and robust. This process not only strengthens the credibility of the results but also provides confidence that the findings are based on accurate, well-verified data that is appropriately transformed for the analysis.
Variables description and MeasurementThe primary variable of interest is obesity prevalence, which is measured as the percentage of the population aged 18 years and older classified as obese, based on a body mass index (BMI) of 30 or higher. The obesity data is specifically sourced from the WHO Global Health Observatory Database. From the mentioned database from WHO, obesity prevalence is segregated in to three categories: both sexes jointly, then males and females separately. This segmentation allows the study to explore the gender-specific trends, recognizing that men and women may experience different influences due to socio-economic, biological and cultural factors. Economic growth, which is the main exposure variable is measured by gross domestic product (GDP) per capita, adjusted to constant 2015 US dollars to account for inflation. The WDI provides the data for GDP, which is an essential economic indicator for assessing the overall economic development of a country. GDP per capita is GDP divided by the midyear population. It is calculated without making deductions for depreciation of fabricated assets or for depletion of natural resources. GDP per capita reflects the average income of the population and is used in the study to understand the link between income growth and obesity based on the OKC hypothesis. The study further conditioned for additional covariates which includes urbanization, trade openness and food production. Particularly, urbanization is measured in terms of urban population total as provided by the WDI. This measurement reflects the total number of people living in urban areas within a country. Urban areas are typically defined based on national criteria, which can include factors such as population density, infrastructure and administrative boundaries. Urbanization is a key factor in obesity trends because urban areas often feature more sedentary lifestyles, greater access to processed foods and fewer opportunities to physical activity, all of which contribute to higher obesity rates. Further trade openness is measured as the sum of exports and imports of merchandise as a percentage of GDP. The proposition is that, greater trade openness increases the availability of imported, often unhealthy processed foods, which can contribute to rising obesity rates. This variable is particularly relevant in understanding how changes in food systems and global trade agreements can affect the dietary habits of populations. Finally, the study includes food production, measured by the food production index which reflects the total food produced domestically in a country relative to the base period 2014–2016 (with a value of 100). This variable is as well important because, food production influences the availability of food and can affect dietary patterns. An increase in food production, particularly if it leads to the production of calorie-dense foods, could contribute to higher obesity rates, especially in urbanized or economically growing countries.
Summarily, the description of variables together with their respect measurement and data source are outlined in Table 1.
Rationale for variables selectionThe selection of variables in this study was guided by multiple theoretical frameworks that provide a comprehensive understanding of the relationship between obesity prevalence and economic growth, as well as the role of urbanization, trade, and food production in shaping the relationship. These frameworks include the OKC hypothesis, urbanization and lifestyle theory, theory of globalization and trade, together with food systems and nutritional transition theory. Each of these frameworks offers insight into how various economic and environmental factors interact with economic growth to influence obesity prevalence. The primary theoretical framework driving the study is the OKC hypothesis, which posits a non-linear (inverted U-shaped) relationship between economic growth and obesity prevalence. According to this hypothesis, as country’s economy grows and incomes increases, obesity rates initially rise due to greater access to calorie-dense foods, more sedentary lifestyles and lifestyles changes that often accompany urbanization. However, after a certain level of economic development is reached, obesity rate begins to decline as people adopt healthier lifestyles, diets and behaviors, often driven by better access to healthcare, public health interventions and more opportunities for physical activity. In the context of this study, economic growth was selected to test the central tenet of the OKC hypothesis and explore how increases in economic development correlated with changes in obesity prevalence across the African regional panels employed. By examining this relationship, the study aims to assess whether Africa countries follow the expected pattern of rising obesity rates with increasing income, followed by potential decline as wealthier nations adopt healthier habits.
Moreover, urbanization plays a crucial role in shaping obesity trends and the theory of urban lifestyle transitions are central to understanding how urban environments impact health outcomes. As populations move from rural to urban areas, they undergo a transition from traditional, often more physically active lifestyles to more sedentary behaviors [20]. This shift is accompanied by increased access to processed, energy-dense foods, less physical activity, and lifestyle changes that favour convenience over nutritional value [10],Bixby, 2022). Urbanization is also linked to changes in food availability, with urban areas offering greater access to fast food, processed foods and sugary beverages, all of which contribute to rising obesity rates [27]. The variable urbanization, was thus selected to capture the impact of this lifestyle transition. By analysing how urbanization influences obesity rates, the study seeks to understand the degree to which urban living contributes to the rise of obesity in African nations. Given the rapid urbanization occurring across much of the continent, this variable is critical to understanding how changing living conditions influence health behaviors and outcomes such as obesity.
Further, globalization through trade openness, has transformed food systems globally. Trade openness is related to obesity on the theory of globalization and nutrition transition, which links increased international trade to changes in dietary patterns and lifestyles[28, 58]. As countries open their markets, there is greater availability and accessibility of imported processed food and calorie-dense foods, often at lower costs than locally-produced, nutrient-rich alternatives [25]. Increased trade openness also facilitates the expansion of global food industries, including fast food and sugary beverage companies, which further accelerates dietary changes that contribute to obesity. In African economies, trade openness has significantly transformed food systems, making obesogenic foods more widely available [21]. The study thus aims to understand how these changes relate with economic growth, and other factors like urbanization and food production in driving obesity trends. By incorporating trade openness, the study provides insight into how international trade contribute to obesity beyond local economic growth, emphasizing the need for polices that regulate unhealthy food imports and promote healthier dietary options. Finally, food systems and nutritional transition theory is central to understanding how changes in food production impact obesity trends. The theory suggests that, as countries industrialize and urbanize, they shift from traditional diets that are low in fat and high in fibre to more Westernize diets that are calorie-dense and nutrient-poor. This transition is often accompanied by an increase in consumption of processed foods, sugary beverages, and fats, all of which are linked to rising obesity rates (An et al., 2020). The variable food production was selected to provide insights into the availability of food and the shift in dietary habits. An increase in food production, particularly energy-dense foods, is expected to influence dietary choices and contribute to the rising prevalence of obesity, especially in urban and economically growing regions. By including food production, the study aims to examine the role of national food systems in shaping dietary behaviours and their link to obesity.
Summarily, the combination of the afore-discussed theoretical foundations guided the essence of selecting the study variables (economic, urbanization, trade openness, and food production) to examine how they are related to obesity prevalence in African regions. These theories ensure that the study captures the complexity of obesity trends, considering the role of economic growth, urbanization, trade openness and food production. By using these diverse theoretical perspectives, the study offers a comprehensive analysis of the factors that contribute to the obesity epidemic in African countries, providing valuable insights for policy makers and public health officials seeking to address the rising prevalence of obesity.
Model specificationThis study aligns with existing empirical literature by examining the non-linear relationship between obesity and economic growth through the lens of OKC hypothesis proposed by Grecu and Rotthoff (42). Nonetheless, the study extends the traditional framework by modeling the inverted U-shaped relationship between economic growth and obesity while incorporating trade openness, urbanization, and food production into a multivariate context, reducing potential biases from omitted variables. As noted earlier, this study analyzes obesity prevalence based on three distinct groups: obesity prevalence among males, obesity prevalence among females, and the combined prevalence in both sexes. This specific classification enables the study to examine how the relationship between obesity and factors such as economic growth, urbanization, trade openness and food production may differ between the mentioned groupings. Based on this, our suggested augmented OKC multivariate panel models are structured in Eqs. (1a-1c). Specifically, in order to mitigate heterogeneity and heteroskedasticity concerns, the data related to the research variables must be converted into natural logarithms [19, 43, 45, 49, 88].
$$ln_}_=_+_ln_+_ln^}_+_ln_+_ln_+_ln_+_$$
(1a)
$$ln_}_=_+_ln_+_ln^}_+_ln_+_ln_+_ln_+_$$
(1b)
$$_}_=_+_ln_+_ln^}_+_ln_+_ln_+_ln_+_$$
(1c)
where \(ln_\), \(ln_\), \(ln_\) represents natural log-transforms of obesity prevalence (both sexes), obesity prevalence (males) and obesity prevalence (females); \(lnGDP\), \(lnURB\), \(lnTRD\), \(lnFP\) respectively stands for the natural logarithms of gross domestic product (economic growth), urbanization, trade openness and food production; \(_\), \(_\) and \(_\) represent the constant terms in the corresponding equations; \(_s\), \(_s\) and \(_s\) (\(i =1,\dots ,5\)), denotes the parameter estimates of the respective explanatory variables; \(_=_+_\) symbolizes the idiosyncratic error term assumed to follow the normal distribution with mean of zero and constant variance, \(_\sim N(0,^\)) with \(_\) and \(_\) representing individual-specific effects (time-invariant) and idiosyncratic shocks (time-varying).Footnote 3
Notably, transforming the mentioned study variables into natural logarithm help reduce the concerns of heterogeneity and heteroskedasticity by compressing the scale of data. This compression reduces the impact of large values, stabilizing variance across observations. In the case of heteroskedasticity, where the variance of the error term changes with the magnitude of the independent variables, logging makes the relationship more proportional leading to a more constant variance. For heterogeneity, logarithmic transformations improve comparability across units by normalizing skewed data, making relationships easier to mode. This approach is particularly effective in panel and times series data, where variability across units and time can be pronounced.
Econometric analysisTo analyse the non-linear relationship between obesity prevalence and income (economic growth), while accounting for the effect of urbanization, trade openness and food production in a panel setting, the empirical estimation process must involve standard econometric procedures. Specifically, the first step is to conduct a cross-sectional dependence (CD) test on the residuals to determine whether there are potential issues of strong or weak interdependence among the cross-sectional residuals with respect to the cross-sections (countries) within the regional panel employed. Practically, the CD test is essential to identify whether shared factors across countries within a panel influence the results, which is a common issue in panel data involving multiple nations. Thus, the Pesaran [73] PCD-test, the weighted CD (CDw) test by Juodis and Reese [47], and the power enhanced (CDW+) test by Fan et al. [32] are utilized. The mentioned CD-tests employed assess the null hypothesis of weak cross-sectional dependence. Weak cross-sectional dependence in this case means the correlation between the cross-section units at each point converges to zero as the number of cross-sections goes to infinity.
Second, it is important to test the unit root before operating for further scrutiny. The fundamental purpose of the unit root tests is to clarify the integration order of the incorporated variables. According to Sandusky (2013), unit root tests that assume cross-sectional residual independence can have low power if estimated on data that is characterized by residual cross-sectional dependencies. This study hence utilized the Pooled Modified Sarghan-Bhargava (PMSB) test by Bai and Ng [13], the cross-sectional Augmented Dickey-Fuller (CADF) test together with the Cross-sectional Im, Pesaran, and Shin (CIPS) by Pesaran [72]. The stationarity qualities of the variables are analyzed based on constant via trend in order to exploit potential hidden features such as selecting appropriate methods, understanding relationships, and assuring the stability of variances and covariances. Specifically, each panel unit root test, assumes the null hypothesis that variables are non-stationary against the alternative that the series are stationary across individual panels or units.
In the third phase of the econometric analysis, we examined the existence of cointegration relationships among the variables utilized in the study using the Westerlund and Edgerton (W-E) (2007) cointegration test and the Durbin-Hausman (D-H) test of cointegration by Westerlund [85]. The W-E test of cointegration deals with four separate panel-cointegration measures which focus on error correction. These measures include the group statistics \(\left(_ and _\right)\) which explores the alternate theory of cointegration for the whole group whereas the second type is the panel statistics \(\left(_ and _\right)\) which notes that, at least one cross-section of the panel is cointegrated. Comparatively, the D-H cointegration test ensures that independent variables vary in stability ranks. It takes into account two separate test statistics which includes panel statistics (\(_\)) and group statistic (\(_\)). Notably, both the W-E and D-H panel cointegration methods are based on the null hypothesis of no cointegration as against the alternative hypothesis of cointegration existence. The null hypothesis is thus rejected on the basis that, the group or panel statistics of the mentioned cointegration tests are statistically significant.
Also, slope coefficients, which quantify the elasticities of the explanatory variables, must be examined to determine whether they are homogeneous or heterogenous prior to estimating the existing long-run relationship (cointegration). Thus, at the fourth stage of the analysis, Pesaran and Yamagata (P-Y) (2008) homogeneity test is employed. The P-Y test also examines the null hypothesis of homogeneous slopes against an alternative hypothesis of slope heterogeneity using the test values of the delta_tilde \(\left(\widetilde\right)\) and adjusted delta_tilde \(\left(adj\widetilde\right)\) adj) statistics which are estimated based on the Swamy (1978) approach. The null hypothesis of slope homogeneity can only be rejected on the basis that the \(\widetilde\) and \(adj\widetilde\) are respectively significant.
Finally, a novel proposed estimator known as the Bias-Corrected Method of Moments (BCMM) by [17] is used to estimate the long-run equilibrium relationship among the study variables. Specifically, the BCCM estimator according to Breitung et al., [17] is used for estimating parameters within dynamic panel models with fixed or random effects. The BCCM technique is designed to enhance the accuracy and efficiency of estimates in dynamic panel data models, especially in the presence slope heterogeneity and residual cross-sectional dependence. Specifically, in panel data, units may exhibit different characteristics, leading to unobserved individual-specific effects. Thus, incorporating fixed or random effects to control for unobserved heterogeneity, ensures the estimators remain consistent and unbiased. Additionally, residual cross-sectional dependence arises when error terms across cross-sectional units (countries) are correlated. The BCMM approach accounts for this by using robust standard errors, enabling the model to provide consistent and efficient estimates even when cross-sectional dependence exists. By applying method of moments to estimate the parameters, the BCMM, ensures that, the estimates are both consistent and efficient, converging to the true value as the sample size increase exhibiting the smallest possible variance among unbiased estimators. Consequently, the BCMM improves the reliability of dynamic panel data models, by addressing bias from unobserved heterogeneity and inefficiencies due to residual cross-sectional dependence. Since the BCMM estimator relies on random and fixed effect dynamic panel models for parametric estimations, the study’s proposed models (specified in Eq. 1a-1c) are re-specified in the dynamic effect framework as,
$$ln_}_=\sum_^_ln_}_+_+_ln_+_ln^}_+_ln_+_ln_+_ln_+_+_$$
(2a)
$$ln_}_=\sum_^_ln_}_+_+_ln_+_ln^}_+_ln_+_ln_+_ln_+_+_$$
(2b)
$$ln_}_=\sum_^_ln_}_+_+_ln_+_ln^}_+_ln_+_ln_+_ln_+_+_$$
(2c)
where,\(_\)\(_\) and \(_\) are estimates of lagged obesity prevalence in both sexes (\(_}_\)), lagged obesity prevalence in males (\(_}_)\) and lagged obesity prevalence in females (\(_}_\)), \(_\) is the individual-specific effect (time-invariant) and \(_\) is the idiosyncratic shocks (time varying).
Specifically, the GDP coefficient estimate and its square are assumed to be positive and negative, respectively, in order for the OKC conjecture to be verified [6, 42], Mathieu‐Bolh, 2022; [21]. Accordingly, the positive and negative signs of \(_\) and \(_\), \(_\) and \(_\), \(_\) and \(_\) correspondingly will suggest that obesity prevalence increases throughout early development but finally drops once income reaches a certain crucial level. This suggests that before the conundrum concerning the predominance of obesity can be resolved, an economy must reach a certain economic level. In light of Ayidin's (2019) research, the point of economic saturation is therefore calculated through the following with respect to the parameter in each dynamic model:
$$^=exp\left(\frac_}_}\right)$$
(3a)
$$^=exp\left(\frac_}_}\right)$$
(3b)
$$^\ast=exp\left(\frac\right)$$
(3c)
More importantly, the models specified in Eqs. (2a-2c) can either be dynamic fixed or random-effect models depending on \(_\). In dynamic panel data models, where lagged dependent variables are included as regressors, the choice between fixed and random effects become more critical, as biases can arise due to the endogeneity of the lagged terms. Thus, to confirm which of the dynamic linear models (random or fixed) to rely on in this extant research, the Hausman test is utilized. The Hausman test in this case relies on the hull hypothesis that the dynamic random effect model (DRM) is appropriate, meaning there is no correlation between the individual effect (unobserved heterogeneity) and the explanatory variables against the alternative hypothesis of the dynamic fixed effect model (DFM) being appropriate, meaning there is correlation between the individual effects and the explanatory variables. Notably, the null hypothesis of the Huaman test can only be rejected based on a statistically significant Chi-square statistic between the estimates of the DRM. Summary of the methodology flow chart is illustrated in Fig. 2.
Fig. 2
Comments (0)