The results of this study demonstrate the potential of novel deep learning architectures in postoperative pancreas auto-segmentation on CT images, which has not been studied previously. Our quantitative evaluation reveals the capability of the presented MKNet-family architectures to accurately segment the pancreatic remnant in the postoperative setting over previous approaches, reflected by better HDs and HD95s. Qualitative evaluation demonstrates potential for clinical applicability, making the model valuable for medical education, accelerating postoperative pancreas segmentation, and supporting future research requiring such segmentation, including studies on postoperative complications and detection of local disease recurrence.
Based on quantitative metrics, it was shown that all auto-segmentation models performed substantially worse in the postoperative setting, as compared to the preoperative setting. This became evident after establishing our reference standard, a zero-shot application of TotalSegmentator [9, 29]. Despite its good results in the preoperative setting, its failure to generalize these results in the postoperative setting highlights the magnitude of the domain shift after pancreatic surgery. For the other models, postoperative results remained substantially worse compared with the preoperative results, even after training and fine-tuning on postoperative data. This emphasizes the need to establish dedicated postoperative datasets such as the IMPACT dataset and tailored architectures such as the MKNet-family models. Notably, these results were to be expected considering the smaller pancreas and even wider variation in size, shape and location of the pancreas and surrounding structures after pancreatectomy, demanding substantial model flexibility. For example, mean pancreas size in the postoperative IMPACT dataset was 23,290 mm3, while this was 73,510 mm3 in the preoperative NIH dataset. Nevertheless, qualitative evaluation by expert abdominal radiologists showed that almost 80% of segmentations by the MSKNet architecture required no to little adjustments. Another interesting finding in this context was that qualitative analysis of the model segmentations seemed to indicate that the model generally performed better after pancreatoduodenectomy than after distal pancreatectomy. Quantitative metrics, however, showed better scores for DSC, HD and HD95 on scans after distal resections, whilst only the NSD was better after head resections. As a higher NSD indicates less under- and overestimation at the border of the pancreatic tissue, e.g., a greater part of the surface voxels is equal to the ground truth, this resonates with the expert analysis. Hence, despite that the quantitative scores can be higher, clinical performance can be lower. This might indicate that achieving a high score on any quantitative metric is not necessarily a truly well-performing model. Considering that our algorithm was capable of segmenting most cases accurately according to expert evaluation, this may provide a better reflection of its true usefulness in clinical practice. Future studies could therefore focus on additional human review when feasible. Furthermore, good qualitative performance of the model seemed related to a sufficiently good DSC and NSD in combination with a very good HD and HD95. This would advocate to focus on optimizing the HD rather than the DSC in future studies, as well as on a combination of quantitative metrics and qualitative metrics, instead of only focusing on the DSC which is often done in medical literature.
DSC scores of MU-Net [16] and PanKNet [17] on preoperative data reported by the original authors could not be reproduced, and a decrease in performance ranging from 7 to 12% was found. For MU-Net [16], this deviation could be caused by a difference in implementation, as a self-implemented version of this model was used. Also, discrepancies could result from a different computation of the DSC. This is particularly relevant in the case of 2D networks, such as in Ma et al. [16] Four-fold division of the data and combining DSCs of the individual slices into the final performance score might substantially alter the findings [41] As identified by Maier-Hein et al. [41], averaging over all slices can result in a substantially higher score than averaging over the slices of one CT scan, with subsequent averaging over all scans. In addition, the DSC can be computed by either using both the foreground and background prediction channels, or using foreground channels only, resulting in different scores. It is generally not mentioned how DSCs are exactly computed, impeding proper comparison between papers. The differences in protocols in the original studies and those used in our study may limit the comparability of reported and achieved performance. However, directly comparing these differences was beyond the scope of the current study.
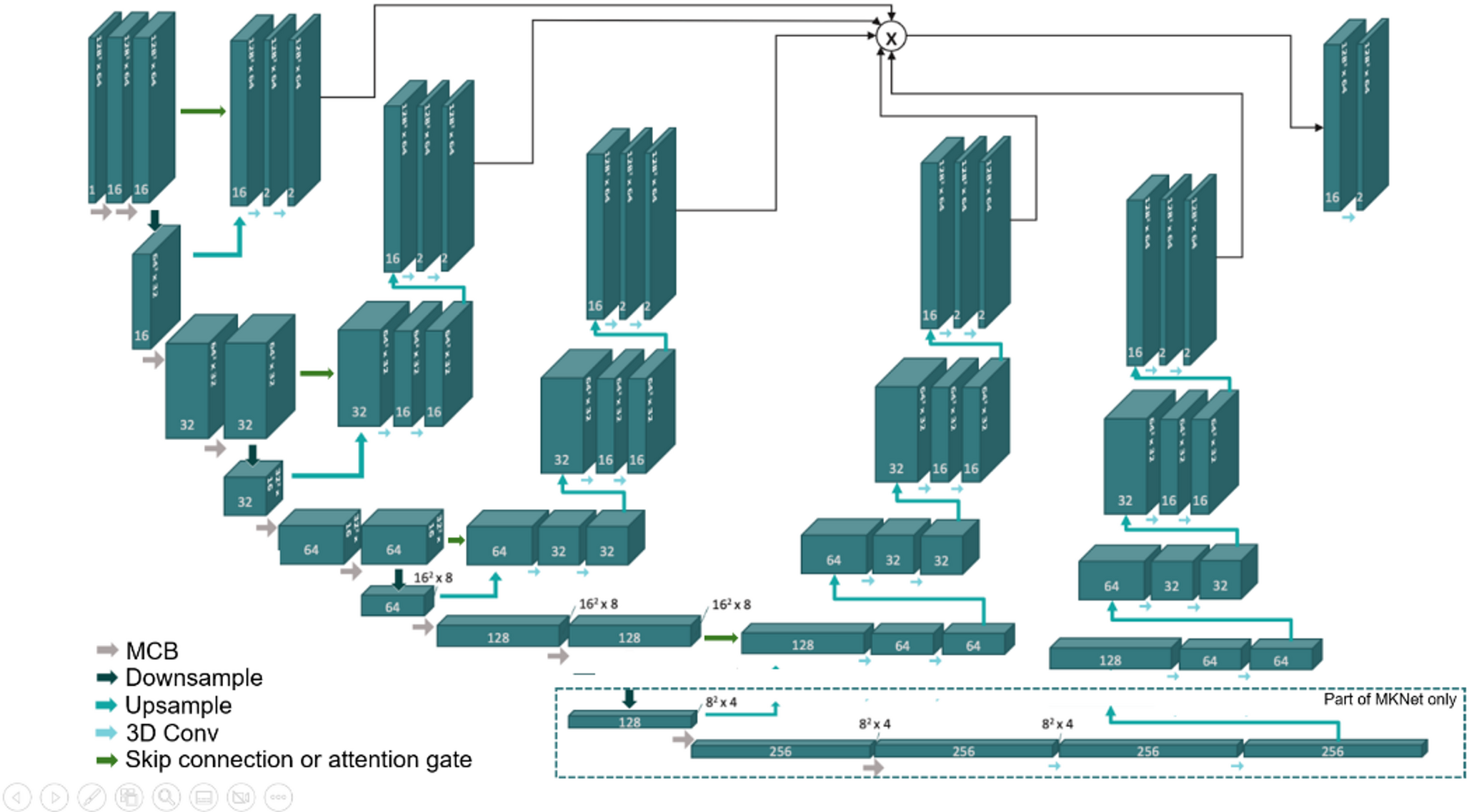
Visual analysis of the segmentations revealed that the ground truth not always continuously flowed through the slices. This means that the circumference could be equal for several consecutive slices, after which it switched to a rather differently shaped annotation. This is a consequence of the resolution of CT scans as well as the applied preprocessing steps. Slice thickness can be up to four millimeters for some scans, whereas preprocessing using trilinear interpolation enforces the slices to be converted to one millimeter. As mentioned, the masks were reshaped using nearest neighbors to acquire discrete values for ground truth voxels, as suggested by Salanitri et al. [17] In combination with a large slice thickness, however, the nearest neighbor method causes the ground truth to deviate in the intermediate slices. This results in less accurate training and lower measured performance on those slices. As exemplified by Fig. 2, additional tissue in the lower right corner was marked as pancreatic tissue. In the slice below, the ground truth also covered this area. Therefore, it seems that either the ground truth had not been annotated with high enough resolution, implying that the segmentations were more accurate than the ground truth in this particular case, or that rescaling during preprocessing caused the mask to deviate. Although we interpolated the ground truth to a uniform voxel size (1 mm) to facilitate more consistent inter-patient comparisons, we opted not to interpolate the segmentation results back to the original resolution due to concerns about potential artifacts like blurring and aliasing. In this example, addition of attention modules increased accuracy, with the MAKNet and Attention U-Net providing similar segmentations. Nevertheless, MAKNet seemed to follow the ground truth more accurately at the border of the tissue than Attention U-Net. [22] This would indicate better performance of the MAKNet, with more accurate borders likely resulting in a higher NSD. Performance discrepancy may be explained by architectural differences. MAKNet’s multi-scale attention structure promotes better global shape understanding, which may reduce outlier errors and improve HD and HD95 [22]. In contrast, Attention U-Net uses gated skip connections that enhance local detail refinement may improve voxel-level overlap and surface agreement (i.e., DSC and NSD) [16]. These findings may reflect trade-offs and different models may be more applicable for different clinical applications. HD may for example be prioritized when boundary awareness is essential such as in radiotherapy or surgical planning, while DSC or NSD may be preferred for tasks like volumetric analysis. Notably, we hypothesized that skip connections would be redundant for the layer-specific decoders of our MKNet-architectures. However, the MSKNet-architecture performed better than the MKNet-architecture. This suggests that skip connections contribute additional contextual information that aids in better segmentation, especially in the complex postoperative setting.
The model showed systematic errors, such as under-segmentation of atrophic pancreatic tissue and misclassification of peripancreatic tissues like the duodenum or splenic vessels. These errors may impact volumetric accuracy, compromise detection of subtle lesions, or complicate assessment of postoperative complications and radiotherapy planning. Such errors likely arise from low contrast differences between tissues, anatomical variability after surgery, and potentially limited representation of certain patterns in the training data. Although these issues are relevant, the aim of this study was to assess the feasibility and clinical utility of a deep-learning network as a pre-annotation tool to accelerate the initial annotation process and reduce manual workload, and not to replace expert segmentation. Continued architectural refinement to support segmentation workflows in clinical practice is warranted.
The findings of this study need to be interpreted in the light of several limitations. First, the kappa coefficient of 0.23 implies only a fair interobserver agreement. This likely results from the lack of prespecified definitions to classify the outcomes in one of four rather subjective categories. Of note, annotations were made with 3D view, while for clinical evaluation 2D slices were used. Despite the variability, 79% of segmentations were considered to require no or only minor adjustments, and the majority of radiologists were willing to use the model for future pre-annotations. This suggests that although the agreement on specific grading may vary, there is still a shared clinical perception of the model’s usefulness. Second, the output of the visual analysis might question the accuracy of the ground truth used for training of the model. Nevertheless, the majority of the model segmentations were considered clinically useful by expert abdominal radiologists, indicating adequate training and clinical applicability. Furthermore, the observation that the segmentations seemed to outperform the manual annotations for certain cases emphasizes the value of developing computer models to perform complex tasks such as postoperative pancreas segmentation. A follow-up study with expert review of the discrepancies between automated and manual segmentations in such cases could further explore this finding. These feedback loops may furthermore increase the models’ performance. This was, however, beyond the scope of the current study. Third, although all models were fine-tuned on postoperative data using an identical training pipeline, performance in the postoperative setting was generally lower than in the preoperative setting. This emphasizes that preoperative segmentation algorithms are not directly transferable to the postoperative setting, hypothesizing that different aspects may become relevant and guide model performance in this context, thereby emphasizing the relevance of the current study. Last, a well-known issue with regard to the application of deep learning in medical imaging analysis is the limited amount of data available. To increase robustness and accuracy of segmentation models in this context, often a pretraining step is applied, training the model under different conditions, i.e., unsupervised versus supervised, or using different datasets. Learned weights are subsequently transferred to the actual segmentation model to gain prior knowledge about the domain. For this study, we performed pretraining on annotated abdominal CT scans of healthy subjects without pancreatic abnormalities, to increase the performance of the segmentation pipeline. External validation on large, multi-center datasets is essential to confirm the generalizability and robustness of the proposed model.
In conclusion, quantitative and qualitative evaluation of the MKNet-family architecture showed potential to accurately segment the residual pancreas on CT scans after pancreatic resection. This not only advances the state-of-the-art in pancreas segmentation but may also be beneficial for medical application and education, acceleration of data annotation, and be a good ground for future research.

Comments (0)