This study provides initial evidence of the feasibility and value of measuring staff perceptions of ED crowding in real time, and of assessing the degree of agreement between these perceptions and two indicators of crowding: the widely used NEDOCS and the recently proposed Fenice crowding score.
Unfortunately, no gold standard measure of ED crowding currently exists. We decided to rely on the staff perception of crowding to evaluate the NEDOCS and Fenice scores because, despite its subjective nature, it remains the only indicator that directly targets the measurement of ED crowding. This is the rationale that drove the development of multiple crowding indicators, including the NEDOCS itself, which were grounded on staff perception measures. Albeit the Fenice score was devised using an objective consequence of crowding, i.e., the increase in waiting time for patients triaged with deferrable urgency, we relied on the staff perception for its assessment. In this context, we involved multiple operators from a wide range of professional roles, to mitigate concerns about subjectivity and ensure a collective perspective. Formally, we investigated what is referred to as construct validity, which refers to how well a tool actually measures the theoretical scheme, or construct, it was designed to measure [17]. This can be done by comparing the indicator of interest against another indicator measuring the same, or similar, aspects of the construct [18].
Overall, we found both scores to be strongly associated with staff perceptions of crowding, with the Fenice score showing slightly higher levels of agreement, even though the difference between scores was marginally non-significant, and a greater ability to explain variability in these perceptions, particularly when stratified by professional role. These findings are notable given that the Fenice crowding score is simple and fully automatable, relying solely on the total number of patients in the ED at any given time.
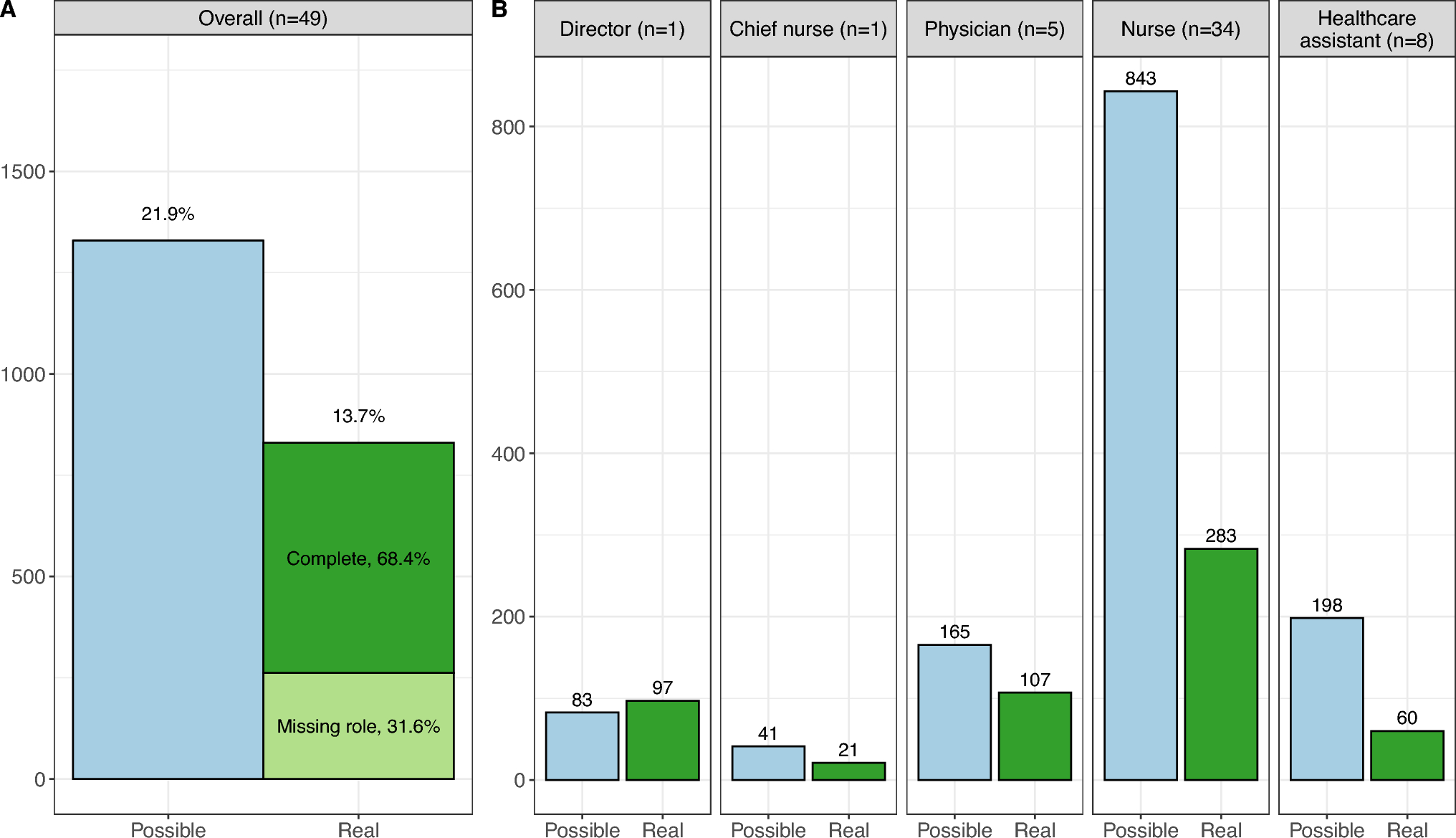
This study demonstrated the feasibility of collecting real-time staff perception of crowding via SMS-based questionnaires. While the overall response rate of 13.7% may seem modest, it should be noted that the probability of the text message reaching staff during their shift in the ED was only 21.9%. Consequently, the 13.7% response rate reflects a participation rate of 62.6% among potential respondents, which is higher than the average response rate (52.7%) for studies that utilized data collected from individuals [19], and is in line with what is considered acceptable (> 60%) for survey research [20]. It is also noteworthy that responses were provided consistently over a 2-month period, with most replies received within an hour of message delivery. The heterogeneity in response rates across roles suggests that engagement varied by position: the chief nurse and ED director responded most frequently, while other roles had lower participation rates. This discrepancy may reflect differences in workload, accessibility to mobile devices during shifts, or the perceived relevance of the survey. Future studies could explore strategies to improve participation.
Our study confirms substantial heterogeneity in perceptions of crowding among different professional roles. Healthcare assistants and boarding nurses perceived the ED as more crowded than their colleagues did, while process management nurses tended to perceive it as less crowded. This may be due to differences in daily tasks, exposure to specific workflow bottlenecks, or responsibility for managing patient flow.
Importantly, although perceived crowding and workload pressure were correlated, they were not interchangeable concepts. In this regard, it is possible that the similarity of the scales on which the two concepts were collected generated a carryover bias, whereby a respondent’s answer to a question is influenced by the response given to a previous question. In future, to avoid spurious correlation and to estimate the threshold of ED crowding levels triggering a marked increase in the pressure of the different professional roles in the ED, similar studies should collect data on workload pressure using a dichotomous answer. Nonetheless, despite the similarity of the overall scores for these two questions, we observed statistically significant differences across roles, suggesting that workload and task-specific stressors influence perceptions of crowding and feeling of being rushed in different ways. This distinction highlights the importance of treating these two aspects as complementary indicators of ED pressure.
The strong correlation observed between the Fenice crowding score and staff perceptions (ρ = 0.709) highlights its potential as a valid real-time crowding proxy, even considering that this correlation was found to be almost significantly better than the more complex NEDOCS (ρ = 0.689; p = 0.06). The slightly higher explanatory power of the Fenice crowding score in regression models (R2 = 0.65 vs. 0.59) suggests a better alignment with staff experience. This result is particularly relevant because the two scores were constructed on very different premises. The NEDOCS was specifically developed to predict how operators perceive crowding and, therefore, should be considered as a subjective crowding score. In contrast, the Fenice indicator was developed to measure a quantifiable consequence of overcrowding, i.e., longer waiting times for patients with minor or deferrable urgency. It is therefore an objective crowding score. Interestingly, the objective crowding score performed equally well, if not better, than the subjective one, even when the two are evaluated using the same parameter that was used to develop the subjective score.
Both scores were moderately correlated with the feeling of being rushed. The values of the correlation coefficients below 0.60 highlight the limitations of crowding indices in capturing work-related stress and pace. These findings reinforce the idea that indicators of crowding should not be interpreted in isolation but, rather, in conjunction with other measures that capture the human impact of pressure in EDs.
Another notable contribution of this study is the exploration of role-specific responses to crowding indicators. Using GAM, we found that while most roles showed a linear relationship between the Fenice crowding score and perceived crowding, some roles, particularly those of emergency room nurses, displayed stepwise trends. This may reflect a threshold-based perception, whereby staff experience relatively manageable conditions until a tipping point is reached, after which perceived crowding escalates sharply. Such non-linearities could help categorize the indicator into meaningful classes for the operators, rather than arbitrary ones.
Interestingly, while the NEDOCS and the Fenice scores were strongly correlated in our single-center study (ρ = 0.848), this association was not observed in a broader group of EDs across Lombardy, where ρ values ranged from 0.238 to 0.992. As a result, assessments of ED crowding in Lombardy varied considerably depending on the indicator used, as reflected by differing rankings of crowding levels. This suggests that the two scores may diverge more substantially depending on the context, particularly where differences in hospital organization, patient flow, or ED size affect the calculation and interpretation of NEDOCS. The study site, being a large university hospital with established digital monitoring systems, may have inherently favored a closer correlation between the two scores. Alternatively, this result could reflect the specific approximations used by the study ED for the NEDOCS components that cannot be automatically calculated from electronic clinical records. Such alignment may not apply to settings with less structured or more variable data collection systems, which highlights one of the major limitations of the NEDOCS when applied outside of its original development context [10]. Conversely, the Fenice score only relies on the availability of the overall number of patients present in the ED. Since this information is unambiguous and can be easily retrieved from any ED software at any given time, the Fenice score can be easily used for real-time monitoring.
A major strength of this study is its real-time, repeated-measures design, leveraging modern, low-burden digital tools for data collection. This ensured frequent sampling, minimizing recall bias, and allowing for dynamic assessment of crowding perception. Additionally, the blinding of staff to crowding scores prevented response bias. Finally, the inclusion of all ED professional roles allowed for a nuanced interpretation of how differently staff members experience crowding.
The main limitation of the study consists in its monocentric nature and the relatively short observation period during winter, a time of year that is often associated with high ED activity. The generalizability of the results to other settings, seasons, or hospitals of different sizes and organizational structures remains to be verified. For example, the ED size may influence the agreement between staff perception and the crowding score, as healthcare professionals in larger departments with multiple areas or workstreams may have a partial view of overall crowding. Agreement may also vary with patient case mix, as the considered crowding scores do not account for the reason for ED arrival or clinical presentation; thus, the disproportionate impact of patients posing a substantial care burden may not be fully captured by the scores. Finally, our findings may not immediately extend to lower-demand periods since perceptions of crowding under average conditions may differ depending on whether they occur during times of unusually high or low pressure. Moreover, seasonal fluctuations in disease patterns, such as influenza or acute coronary syndromes, can alter the case mix of ED presentations and, in turn, affect the agreement between the Fenice score and staff perceptions of crowding. Future research should address these issues in broad multicenter studies.
Other limitations must be acknowledged. First, staff perceptions were collected at two fixed times of day, every day. The generalizability to other timing should be consequently assessed. Second, the voluntary nature of participation may have introduced a selection bias, with individuals more sensitive to ED crowding potentially being more likely to respond. Unfortunately, we did not track responses from the same individuals, thus we cannot evaluate whether the results differ across subjects with different response rates. Third, although we analyzed over 800 on-duty responses, the lack of role data in 31.6% of the responses limited our ability to perform fully stratified analyses. Finally, while the Fenice crowding score performed slightly better than the NEDOCS in some comparisons, this difference was not statistically significant, so the results should be interpreted with caution.
In conclusion, this study demonstrates that assessing ED staff perceptions of crowding in real time is feasible and informative. Both NEDOCS and the newly proposed Fenice crowding indicator correlate strongly with these perceptions. While the simplicity of the Fenice score and the possibility to fully automate its calculation make the score operationally appealing, further studies specifically designed to validate it across different settings are warranted.


Comments (0)