In this section, we first describe the original model, followed by the derivation of the approximate model. We then present the network models used in this paper and our benchmarking setup.
2.1 Description of the original model
The original model (Brunel & Wang, 2001) is a conductance-based leaky integrate-and-fire neuron with a synaptic NMDA current given by
$$\begin \begin I_\textrm(t) = \\ \frac \times \left( V(t) - V_E \right) }} \right] \textrm \left( -0.062 V(t) \right) / 3.57} \\ \times \sum _^ w_j S_}(t) \end\end$$
(1)
$$\begin \begin \frac}(t)} = \\ -\frac}(t)}}+ \alpha x_j(t) \left( 1 - S_}(t) \right) \end\end$$
(2)
$$\begin \frac = - \frac} + \sum _k \delta \left( t - t_j^k \right) \end$$
(3)
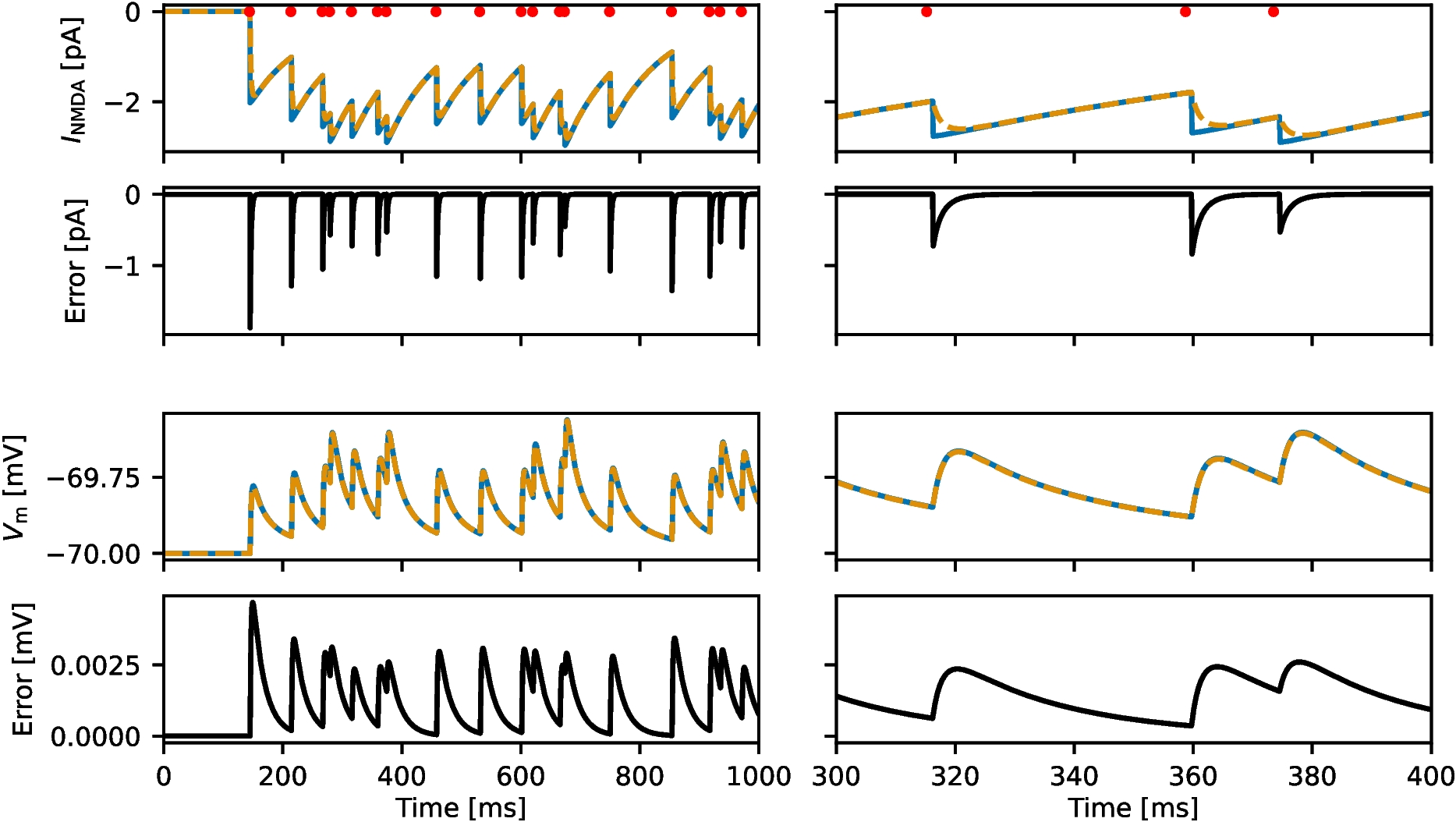
where \(\tau _\textrm\), \(\tau _\textrm\) and \(\alpha\) are model parameters, and \(t_j^k\) are the spike times of neuron j. See Table 1 for the complete model equations and Table 2 for parameter values.
2.2 Simplified NMDA gating dynamics
We will focus solely on the NMDA gating variables \(S_j(t)\) and \(x_j(t)\). For simplicity, we use the shorthand notation \(\tau _\textrm\) and \(\tau _\textrm\) to represent \(\tau _\textrm\) and \(\tau _\textrm\), respectively. Assuming that neuron j last spiked at time zero and does not spike again until time t, the solution to Eq. (3) is given by
$$\begin x_j(t) = x_j^0 \textrm\left( -\frac} \right) \textrm \end$$
(4)
where \(x_j^0\) is the value immediately after the spike. By substituting the solution for \(x_j\) into Eq. (2), we obtain the following expression for the time evolution of \(S_j\) until t:
$$\begin \frac} + \left( \frac} + \alpha x_j^0 \textrm\left[ -\frac}\right] \right) S_&= \alpha x_j^0 \textrm\left[ -\frac}\right] \end$$
(5)
We obtain the formal solution by applying an integrating factor as follows:
$$\begin \begin S_(t) = \textrm\left[ -\frac} - \alpha x_j^ \tau _\textrm \left( 1 -\textrm\left[ -\frac} \right] \right) \right] \\ \times \left( S_^0+ \alpha x_j^0 J(t) \right) \end\end$$
(6)
where \(x_j^0\) and \(S_j^0\) are the initial conditions. J(t) is the integral
$$\begin J(t) = \int _0^ \textrm\left[ \frac} + \alpha x_j^0 \tau _\textrm \left( 1 - \textrm\left[ -\frac} \right] \right) \right] dt' \end$$
where \(\tilde = (1/\tau _\textrm - 1 / \tau _\textrm)^\). This integral does not have a closed-form solution.
We seek an approximation of the form
$$\begin \hat (t) = S_\textrm \textrm\left( -\frac\right) \end$$
(7)
where \(S_\textrm\) is the—as yet unknown—initial value of the function immediately after spiking. We further assume that \(x_j\) has decayed to 0 before neuron j fires its next spike, so that \(x_j\) jumps to \(x_j^0 = 1\) as the next spike is fired. We determine \(S_\textrm\) as a function of the value of \(\hat (t)\) immediately before spiking, by requiring that the approximation is asymptotically equal to the true solution, i.e.,
$$\begin \lim _\frac (t)} = 1 \end$$
(8)
By substituting Eqs. (6) and (7) into Eq. (8), we find that
$$\begin \begin S_\textrm = \lim _ \textrm\left[ - \alpha \tau _\textrm \left( 1-\textrm\left[ -\frac} \right] \right) \right] \\ \times \left( S_^0 + \alpha \tilde(t) \right) \end\end$$
(9)
where
$$\begin \tilde(t) = \int _0^ \textrm\left[ \frac} + \alpha \tau _\textrm \left( 1 - \textrm\left[ -\frac} \right] \right) \right] dt' \end$$
(10)
Substituting \(u = \alpha \tau _r e^}\), the integral \(\tilde(t)\) can be expressed in the limit as
$$\begin \lim _ \tilde(t)&= \frace^(\alpha \tau _r)^} \int _0^ u^} e^du \\&= \frace^(\alpha \tau _r)^} \gamma \big [1 - \frac, \alpha \tau _r \big ] \textrm \end$$
where \(\gamma\) is the lower incomplete gamma function (DLMF, 2024, Eq. 8.2.1). Thus, Eq. (9) can be evaluated as
$$\begin S_\textrm = e^} S_j^0 + (\alpha \tau _r)^} \gamma \big [1 - \frac, \alpha \tau _r \big ] \end$$
(11)
We define two constants
$$\begin k_0&= \left( \alpha \tau _r \right) ^} \gamma \left[ 1 - \frac, \alpha \tau _r \right] \end$$
(12)
$$\begin k'_1&= e^} \;, \end$$
(13)
which depend solely on the synaptic parameters. For a presynaptic neuron j, let \(\hat\) be the time of the previous spike and \(t^-\) the time immediately before the next spike. Then, according to the definition of our approximation, we have
$$\begin S_j \left( t^- \right) = S_j \left( \hat \right) e^}} \;. \end$$
The value of \(S_j\) at \(t^+\), immediately after the spike, is then given by
$$\begin S_j \left( t^+ \right) = S_\textrm = k_0 + k'_1 S_j \left( t^- \right) \;. \end$$
In a postsynaptic neuron, the sum over all presynaptic \(S_j\) is aggregated in a single variable. Therefore, the change in \(S_j\) upon the spike, rather than its value immediately after the spike, must be transmitted to the postsynaptic neuron to update the aggregated variable. The change in \(S_j\) upon the spike at time t is
$$\begin \Delta S_j&= S_j \left( t^+ \right) - S_j \left( t^- \right) \\&= k_0 + k'_1 S_j \left( t^- \right) - S_j \left( t^- \right) \\&= k_0 + k_1 S_j \left( t^- \right) \textrm \end$$
with \(k_1 = k'_1 - 1\). The change \(\Delta S_j\) can then be transmitted to all postsynaptic neurons and added to their aggregated S input variable. The aggregated NMDA gating variable in a postsynaptic neuron can be simulated using the following differential equation
$$\begin \frac = -\frac} + \sum _ \Delta S_j(t) \delta \left( t - t_j^k \right) \;. \end$$
(14)
Reference implementations of both the approximate model and the original model can be found in the NEST simulator under the model names iaf_bw_2001 and iaf_bw_2001_exact, respectively.
2.3 Network models
Here we describe the network model used to validate the approximation and for exploring decision-making in sparsely connected networks respectively, as well as our benchmarking setup.
2.3.1 Decision-making network
Table 1 Description of decision-making network following the guidelines of Nordlie et al. (2009)Table 2 Parameters for decision-making network from Wang (2002)To validate the approximation in a practical use case, we replicate the decision-making network model originally studied by Wang (2002). This network consists of three excitatory populations and one inhibitory population, all of which are recurrently connected. An external population, modeled as a Poisson process, projects equally onto all recurrent neurons. The selective populations \(E_\textrm\) and \(E_\textrm\) each comprise a fraction f of the total number of excitatory neurons, while the nonselective population \(E_\textrm\) comprises the remaining fraction \(1 - 2f\) of excitatory neurons. The selective populations receive a transient stimulus in the form of spikes onto AMPA synapses from an additional Poisson process. The relative strength of the transient stimulus received by the selective populations is determined by the input coherence \(c'\) of the signal. The rate of the transient stimulus is given by \(\mu _\textrm = \mu _0 + \rho _\textrm c'\), \(\mu _\textrm = \mu _0 - \rho _\textrm c'\). In this study, we consider the case where \(\mu _0 = 40\) sp/s, and \(\rho _\textrm = \rho _\textrm = \frac\).
A concise description of the model is provided in Table 1, and the parameter values used are listed in Table 2.
2.3.2 Sparse decision-making network
To investigate the dynamics of a sparsely connected decision-making network, we change the connectivity rule to random fixed in-degree \(\epsilon _\textrm N_\textrm\) without multapses (Senk et al., 2022). Here, \(\epsilon _\textrm\) denotes the connection probability from presynaptic population X onto postsynaptic population Y, and \(N_X\) denotes the size of presynaptic population X. When \(\epsilon _\textrm = 1\) for all \(\textrm\) and \(\textrm\), the fully connected network is recovered.
For the first two seconds of the simulations, all outgoing NMDA connections from the selective populations are replaced by a constant “\(S_\textrm\)-current” with value \(N_\textrm \epsilon _\textrmw_\textrmg_\textrm / \tau _\textrm\), which is added to the right-hand side of Eq. 14 for all populations. Here, \(\epsilon _\textrm\) is the connection probability from presynaptic selective population A onto postsynaptic population X, and \(w_\textrm\) is the corresponding synaptic weight. This drives the aggregated \(S_\textrm\)-value in the postsynaptic neurons towards the value it would take if all \(S_}\)-values in selective population A were 1, and the corresponding values for selective population B were 0, effectively clamping them. After 2 seconds, the NMDA connections are restored and the “\(S_\textrm\)-current” is removed. If the given connectivity admits an asymmetric state, i.e., a state where one of the selective populations has higher activity than the other, the network will relax into it.
By varying the values of the connection probabilities within the network, we can determine the values that support decision-making dynamics. Simulations were run with \(\epsilon _\textrm = 0.2\) for all pairs of populations except \(\epsilon _\textrm = \epsilon _\textrm\) (internal connectivity within each selective population) and \(\epsilon _\textrm = \epsilon _\textrm\) (inhibitory-selective connectivity). These two connectivity values were systematically varied across 33 evenly spaced points in the interval [0.2, 1.0] for each pair.
2.3.3 Benchmarking setup
We use the fully-connected decision-making network to measure simulation times, but with \(f=0\). This results in a network with one excitatory and one inhibitory population and steady-state activity. We scale the network size from 1.28 times to 10.24 times the size of the original network in powers of 2. These network sizes, comprising from 2560 to 20480 neurons, were chosen to be evenly divisible across up to 128 parallel threads. Due to the all-to-all connectivity and the pairing of AMPA and NMDA synapses, this results in a network of about 755 million synapses for the largest network size. Synaptic conductances for all recurrent connections were scaled inversely with network size to approximately maintain network dynamics.
We benchmark four different implementations of this model: Using NEST and our approximation (iaf_bw_2001), using NEST and the original model (iaf_bw_2001_exact) as well as two implementations in Brian2 as external references. The first of these is a restricted implementation that only supports fully connected networks with equal delays (Wimmer & Stimberg, 2023), while the other allows arbitrary connectivity; it is inspired by Moreni et al. (2025). Neuron models in NEST used an adaptive Runge-Kutta-Fehlberg-45 numerical solver, which has a slightly higher computational cost than the Runge-Kutta-4 numerical solver used in the Brian2 simulations.
Benchmark results reported here were obtained with NEST 3.8 (Graber et al., 2024) on the JURECA supercomputer at the Jülich Supercomputing Center equipped with AMD EPYC 7742 CPUs providing 128 compute cores. Simulations were performed using 8 and 128 threads. Eight threads are the minimum required to simulate the largest network size with NEST.

Comments (0)