
Remember me
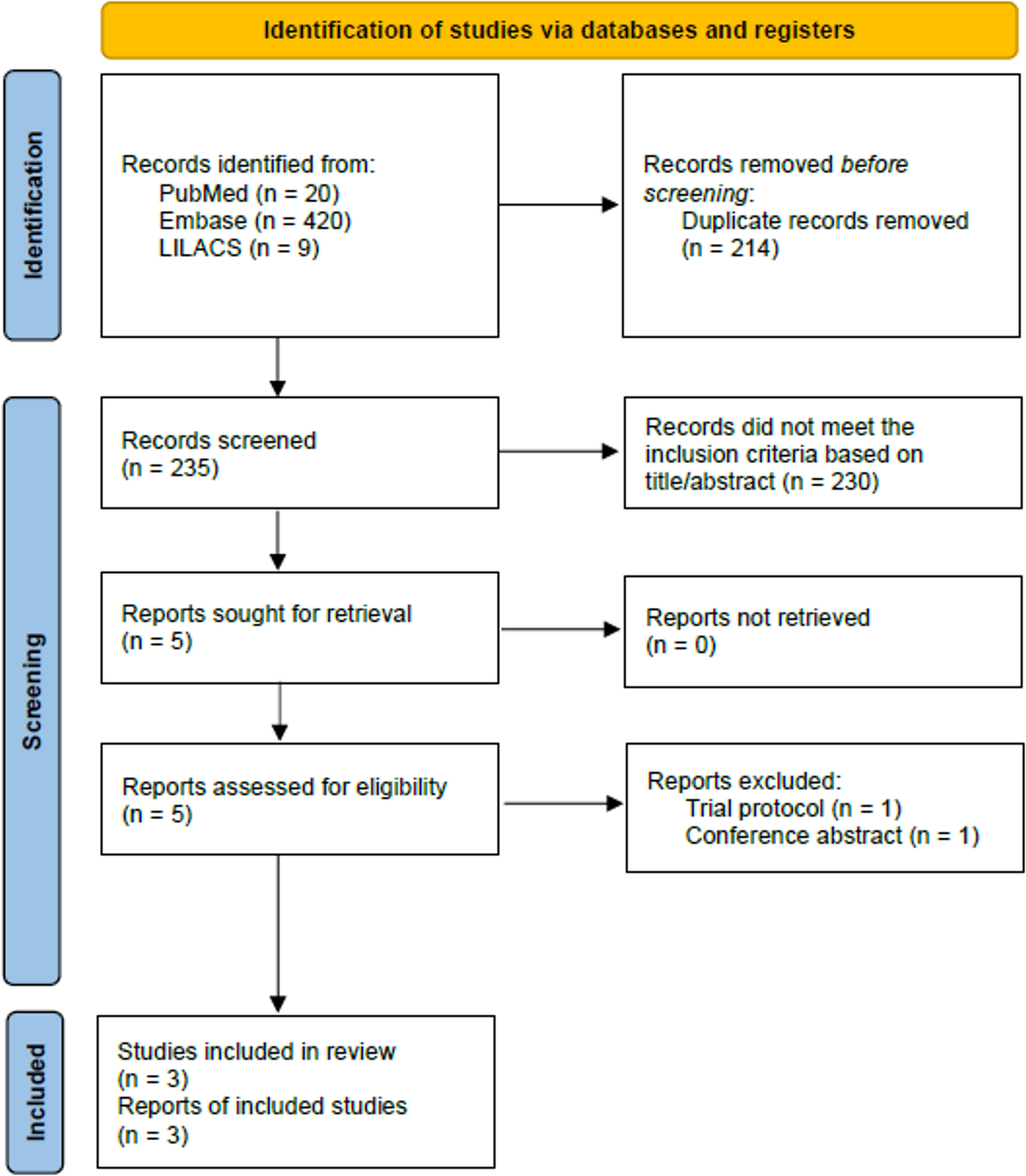
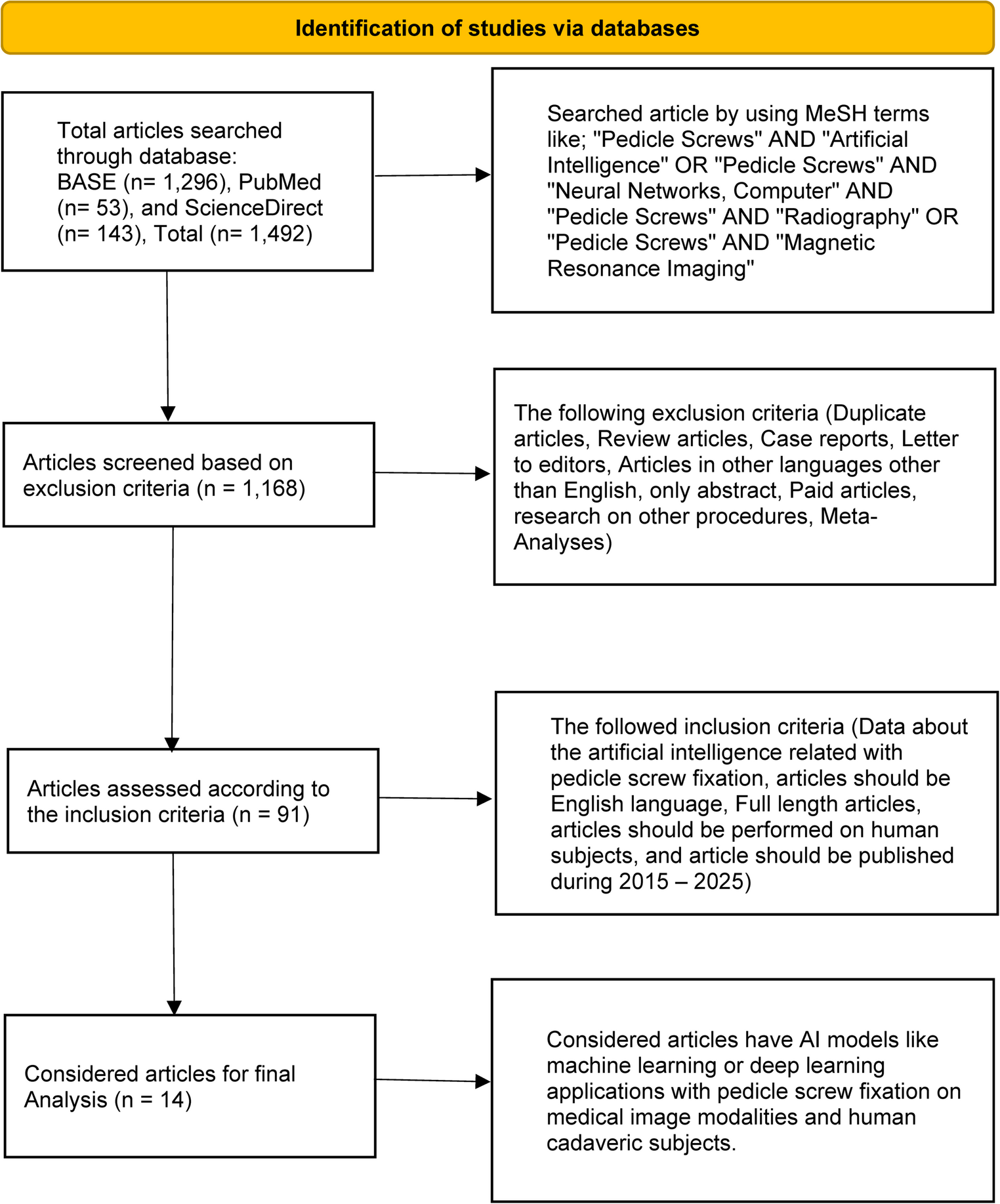
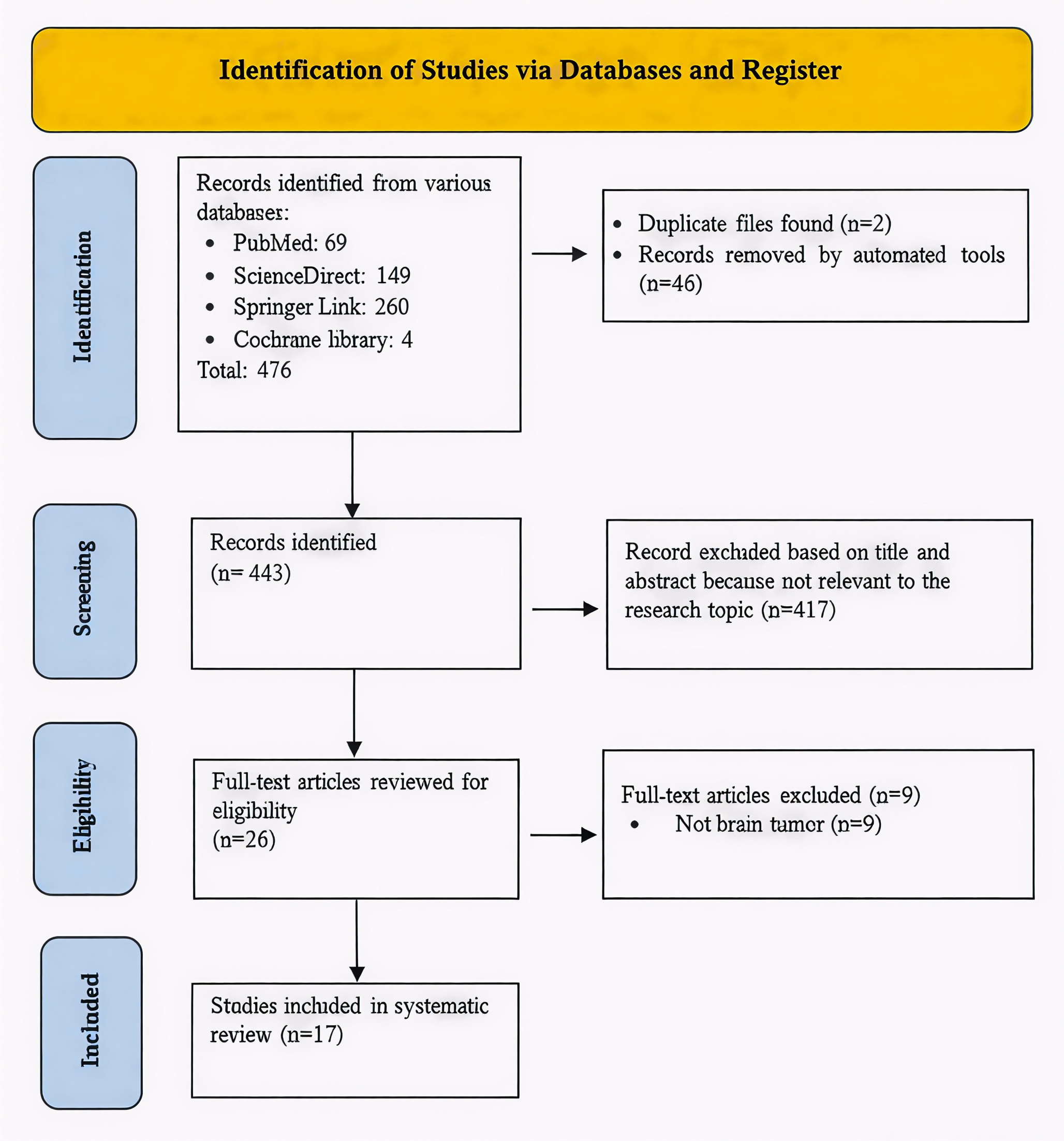
The MeSH terminology was used to identify 1,492 articles in total that were searched from various online sources, including BASE (1,296), PubMed (53), and ScienceDirect (143), respectively. 1,168 articles remained after implementing the exclusion criteria, and 91 articles after using the inclusion criteria. From 91 articles, we selected only 14 for organization and analysis using the PICO format. We applied the systematic reviews and meta-analyses (PRISMA) for the study selection process, as shown in the flow diagram in Fig. 1.
Fig. 1
PRISMA flow diagram of systematic review
All the selected articles were retrospective studies at 64.29% and prospective studies at 35.7%. Of the studies, 12 (85.7%) focused only on the lumbar or lumbosacral segment, whereas 2 (14.3%) included the whole spine but provided data relevant to the lumbar region. The perioperative period was observed, and it was found that the intraoperative phase was at 50.0%, followed by the preoperative phase at 28.6%, the postoperative phase at 14.3%, and both the pre- and intraoperative phases at 7.1%, respectively. The most common image modalities for AI applications in pedicle screw fixation were CT and CBCT scans at 35.7%, followed by radiography at 21.4%, the combination of at least two modalities at 21.4%, and MRI at 7.1%, respectively. In addition, 14.3% came from RGB or RGBD video sources and stereo camera images. The relevant characteristics of the included studies, including study designs, population, sample size, perioperative phase, image modalities, AI models, applications, and key findings, are presented in Table 1. Furthermore, what is the basic principle of each AI model, and why does it fit this task? was shown in Table 2.
Table 1 Technical Performance and Clinical Analysis of AI Models in Spinal SurgeryTable 2 Technical principles of AI models in spinal surgeryMoreover, we found that 78.6% of the AI models included in the strategy were identifiable, whereas 21.43% were unidentified models, which referred to deep learning (DL) or machine learning (ML). The researchers selected architecture, which was a subset of DL, at a rate of 92.9%. U-Net-based architecture was the most prevalent DL model, representing 28.6%. Approximately 71.4% of articles effectively implemented their strategy with a singular model without integration with others. Furthermore, half of the overall research articles utilized AI models for image segmentation in comparison to other applications. We divided the successful application of AI models related to PS into four different categories, as illustrated in Fig. 2.
Fig. 2
The application of AI models related to PS has been divided into four main categories: segmentation, object detection, registration, and others
Various AI models were applied to automate surgical tasks. These are divided into four groups: Segmentation (outlining bones), Detection (localizing landmarks or implants), Registration (aligning preoperative plans with intraoperative anatomy), and Others (such as image enhancement and modality synthesis), as shown in Table 1; Fig. 2. The results are described below.
SegmentationVarious model types were identified, including FCN, nnU-Net, and 2D-U-Net, alongside unspecified ML and DL architectures. In terms of pure accuracy, results varied by data source. As an example, Burström et al. [5] found an automated segmentation accuracy of 86.1%, which increased up to 95.4% when patients with severe spinal deformities were not evaluated. Similarly, the FCN model by Esfandiari et al. [9] achieved 93.0% accuracy on synthetic X-rays, though this dropped to 83.0% on clinically realistic images.
Pose Estimation and Geometric Accuracy beyond simple segmentation, the spatial accuracy of these models was critical. Esfandiari et al. found a 3D angular discrepancy of 1.93° ± 0.64° between the estimated screw axis and the measured tunnel axis, with a Euclidean distance error of 1.92 ± 0.55 mm. Using nnU-Net, Scherer et al. [13] found a bit higher mean absolute differences (MADs): 4.61 ± 2.27 mm for the point of the screw head and 5.51 ± 3.64° for the direction of the screw. Even though there were some differences, the clinical safety was high. Using the Gertzbein-Robbins system, 3.8% of the screws were Grade B (not completely within boundaries) and 96.2% were Grade A (completely within boundaries), as shown in Fig. 3A [23].
Fig. 3
Classification systems for assessing pedicle screw placement accuracy. (A) The Gertzbein-Robbins classification system categorizes screw placement based on the degree of cortical breach. Grades A and B are generally considered clinically acceptable. (B) The Zdichavsky classification provides a more detailed assessment of perforation direction and severity. Both systems are widely used in clinical practice and research to evaluate pedicle screw placement safety. Pedicle screw placement accuracy classification systems. Panel A: Gertzbein-Robbins Classification; Grade A: The screw is fully within the pedicle (without breach), Grade B: ≤ 2 mm perforation, Grade C: 2< x ≤ 4 mm perforation, Grade D: 4< x ≤ 6 mm perforation, and Grade E: > 6 mm perforation. Panel B: Zdichavsky Classification; Grade IA: ≥ 50.0% of screw within the pedicle AND ≥ 50.0% of pedicle screw within the vertebral body, Grade IB: > 50.0% of pedicle screw lateral outside the pedicle AND > 50.0% of pedicle screw within the vertebral body, Grade IIA:≥ 50.0% of pedicle screw within the pedicle AND > 50.0% of pedicle screw lateral outside the vertebral body, Grade IIB: ≥ 50.0% of pedicle screw within the pedicle and tip of pedicle screw crossing the midline of the vertebral body, Grade IIIA: >50.0% of pedicle screw lateral outside the pedicle AND >50.0% of pedicle screw lateral outside the vertebral body, and Grade IIIB: >50.0% of pedicle screw medial outside the pedicle and tip of pedicle screw crossing midline of the vertebral body
Generalization and Validation: newer models tested robustness across different datasets. Da Mutten et al. [21] showed that a 2D-U-Net could generalize well, achieving a Dice score that actually increased from internal validation (0.76 ± 0.12) to external validation (0.79 ± 0.17).
Efficiency Gains: A consistent finding across studies [5, 12, 19, 20] was the reduction in processing time. Most notably, Scherer et al. demonstrated a 10-fold increase in speed, reducing the planning time from 6.41 min (manual) to just 41.8 s (automated) per case. Burström et al. similarly reported a mean time of 11± 4 s for 5 vertebrae.
Clinical Workflow: Accurate segmentation is merely the prerequisite for 3D reconstruction and trajectory planning [20, 29]. As these studies highlight, while automated segmentation significantly accelerates the preoperative workflow by replacing manual plotting, clinical validation (post-validation) remains essential to ensure these time gains do not come at the cost of geometric precision.
Landmark and object detectionHigh-Precision Landmark Detection: A safe plan for the trajectory depends on correctly identifying the anatomical landmarks. In controlled studies, AI models demonstrated exceptional reliability. At a 3 mm distance threshold, Zhang et al. [14] utilized a modified U-Net and ResNet34 architecture that could automatically find the landmark on the lumbar vertebrae. It had a PCK of more than 93%. Additionally, the intraclass correlation coefficients (ICC) for seven parameters, including pedicle axial angle, screw path length, pedicle width, and interpedicular distance, were 0.82–0.98, supporting the clinician’s assessment.
Screw and Implant Detection: AI can detect each pedicle screw implant, and its application is effective for spinal implant identification. Yang et al. reported a comparison of three AI models. They found the ResNet34 model, with ImageNet pre-trained weights and transfer learning, achieved 97.0% accuracy and a 96.7% recall for anteroposterior (AP) radiography, as well as a 98.7% accuracy and a 98.2% recall for lateral (Lat) radiography. Google AutoML demonstrated 91.4% precision and 87.4% recall for AP radiography, whereas Lat radiography showed 97.9% precision and 98.4% recall. In Apple Create ML, AP radiography demonstrated 76.0% precision and 73.0% recall, while Lat radiography revealed 89.0% precision and 87.0% recall [16].
Safety and Grading Validation: Several studies moved beyond simple detection to clinical safety verification. Siemionow et al. [12] used a CNN to grade screw placement, reporting that 100.0% of 208 samples were classified as Zdichavsky Grade [24] IA (no perforation), as shown in Fig. 3B. Similarly, under the Gertzbein-Robbins system, as shown in Fig. 3A, 99.0% (206/208) were Grade A.
The Generalization Challenge: Despite these successes, robustness remains a critical issue when models face external data. Da Mutten et al. used the YOLOv8m model for object detection, achieving the average of the mean average precision calculated at varying IoU thresholds, ranging from 0.50 to 0.95 (mAP50-95) values of 0.64, 0.63, and 0.09 for training, internal validation, and external validation, respectively. Then they utilized another model for automatic segmentation. This drastic drop suggests that while AI can “memorize” specific hospital datasets, it may struggle to detect spinal objects in images from different machines or protocols without further training [21].
Emerging Technologies: Stereo Vision: To eliminate X-ray dependence, von Atzigen et al. [17] used a Stereo Neural Network (SNN) to autonomously locate pedicle screws with an average inaccuracy of 5.43 mm. In addition, SNN can reconstruct the rod’s shape in real time for an accurate 3D shape estimate and rod shape evaluation.
RegistrationRegistration and Real-Time Navigation: Computer-assisted surgery's most significant difficulty is the "registration bridge"—fitting preoperative planning to intraoperative anatomy. Liebmann et al. [15] addressed this using a U-Net architecture to assist navigation. The median registration success rate was 100.0%, with a median Target Registration Error (TRE) of 2.7 mm, Trajectory Error (TrEr) of 1.6°, Entry Point Error (EpEr) of 2.3 mm, and Average Distance Difference (ADD) of 2.6 mm.
Speed and Efficiency: Beyond accuracy, Liebmann et al. [15] highlighted the efficiency of AI-driven registration. The median duration for the registration step is 1475 ms, while the pose update step takes 20 ms.
Robotic Safety and Path Planning: Ao et al. [22] demonstrated the preoperative planning system called “SafeRPlan” for robotic spine surgery, which used preoperative and intraoperative registration, combining real-time observation for continuous path planning for PS. They found that it improved safety by 5.0% compared to existing methods for placing pedicle screws, with 99.0% safety rates based on an evaluation of the real ultrasound (US) reconstruction dataset.
Clinical Significance: This study [15, 22] shows that AI can aid virtual planning and physical implementation of the “handshake”. Preoperative planning specifies the course, but perfect registration keeps the instrument on it. For robotic and guided spine surgery, AI is improving at hard, real-time spatial alterations. Very low error rates (TRE < 3 mm) and high safety margins (99.0%) show this.
OthersImage Enhancement and Modality Synthesis: Beyond segmentation and navigation, AI models are increasingly used to overcome the inherent limitations of medical imaging hardware. Thies et al. [11] improved intraoperative imaging by removing metal artifacts with a modified VGG architecture. CT scans often show a “starburst” visible from screws and rods in revision operations. These hid the bone next to them. The model improves body part visibility during challenging revisions. By selecting these things, the user can adjust the C-arm’s path online.
Cross-Modality Synthesis (MRI to CT): A more severe approach is to take diagnostic images without radiation. From MRI data, Roberts et al. [18] created “virtual” CT scans using a Supervised 3D CycleGAN. This allows clinicians to use MRI’s enhanced soft-tissue contrast and bone detail for surgery planning without radiation from a CT scan.
Accuracy vs. Safety Trade-offs: While the concept of synthetic CTs is promising, current reliability varies significantly by plane. Roberts et al. found that while sagittal plane measurements were accurate (errors < 10.0%), axial plane measurements suffered errors of up to 34.0%. Since pedicle screw width and trajectory are primarily determined in the axial plane, this high error rate presents a significant safety barrier. This discrepancy was reflected in the Intraclass Correlation Coefficients (ICC), where synthetic CTs (ICC 0.60–0.92) failed to match the reliability of real CTs (ICC 0.80–0.96), with Intervertebral Disc Height (IVDH) showing the lowest reliability.
Risk of Bias AssessmentThe quality assessment of the included studies revealed significant sources of bias, particularly concerning study design, as shown in Fig. 4. High-risk patient selection was found in 11 (78.6%) of 14 studies. Because the data were retrospective and the researchers used convenience sampling, which may limit the generalizability of the findings. For the Index Test, 7 research studies (50.0%) were high risk because they didn’t have criteria for evaluating models, which could mean that the performance metrics were too optimistic. In contrast, the Reference Standard domain exhibited the least bias because proven clinical grading systems (e.g., Gertzbein-Robbins) were consistently utilized to confirm surgical outcomes, ranking 12 research studies (85.7%) as low risk. Finally, because the duration between the first test and the reference standard confirmation and patient loss was not clearly documented, the risk of bias related to flow and timing was generally unknown in 9 studies (64.3%).
Fig. 4
Risk of bias assessment using the Robvis risk of bias tool. (A) The risk of bias summary displays the review author’s judgment regarding each risk of bias item for every included study. (B) Risk of bias graph showing the review author’s judgment about each risk of bias item presented as percentages across all included studies
Performance metrics reportedMost of the studies (10 out of 14, or 71.4%) used technical numerical scores, but four studies (28.6%) used only clinical grading. For segmentation tasks, half of the studies reported results, but only three clearly said they used the Dice coefficient. Precision and Recall were also rare; they only showed up in two papers. Most of the people who answered (57.1%) focused on spatial accuracy instead of these usual AI measures. They talked about errors in millimeters or degrees. No study showed AUC/ROC graphs, as shown in Table S3.
Comments (0)