
Remember me


This retrospective study used knee MRI data acquired before the research began. The goal was to develop and validate a classification model distinguishing normal and AATA-present cases, using radiologist annotations as the reference. No direct comparison with other radiologists was performed; instead, we aimed to create a practical tool to support clinical workflows. By automating AATA detection, we seek to enhance knee surgery safety and prevent complications from undetected anomalies.
DataA retrospective dataset from the multicenter institution Diagnóstico da América (DASA) was acquired after IRB approval, encompassing 2400 knee MRI exams. Of these, 1200 were initially identified through a text-based search of radiology reports containing the term “aberrant anterior tibial artery,” while another 1200 were randomly chosen as controls without mention of this variant. All images were anonymized using the RSNA tool [10].
Five musculoskeletal radiologists (2–7 years of experience), supervised by a senior radiologist (25 years), labeled each MRI slice using the MD.AI Platform [11] (MD.ai, New York), marking the presence (1) or absence (0) of the AATA based solely on image findings. They received about 10 example annotations beforehand. At the end of the labeling process, the same supervising radiologist reviewed all annotations to identify and correct any inconsistencies. No bounding boxes or additional metadata were used.
This dataset was used for training, validation, and internal testing and was restricted to MRI exams performed in 2023. Quality control involved removing duplicate slices, addressing ambiguous cases, and reviewing images with multiple annotations for the same structure. Only T2-weighted and PD axial series were kept for imaging consistency. All MR sequences were performed without IV contrast. An external dataset from the public hospital from Universidade Federal de São Paulo (UNIFESP), a quaternary care hospital, was also obtained under IRB approval. Potential cases were identified by searching for “aberrant” in radiology reports, then labeled and anonymized using the same protocols. Unlike the internal dataset, it was not restricted by acquisition date but followed identical T2-weighted and PD axial filtering.
Image preprocessingAll DICOM files were converted to JPEG Lossless format to facilitate downstream processing. To mitigate the impact of image artifacts, each MRI series was processed in its entirety, and an intensity normalization step was performed by excluding pixel values below the 0.25th percentile (p0.25) and above the 99.75th percentile (p99.75) on a per-series basis. This approach helped to ensure a more uniform and robust representation of brightness, contrast, and saturation across the dataset, thereby improving the overall quality of the input images for subsequent training and analysis (Fig. 2). This preprocessing pipeline was implemented in both internal and external datasets.
Fig. 2
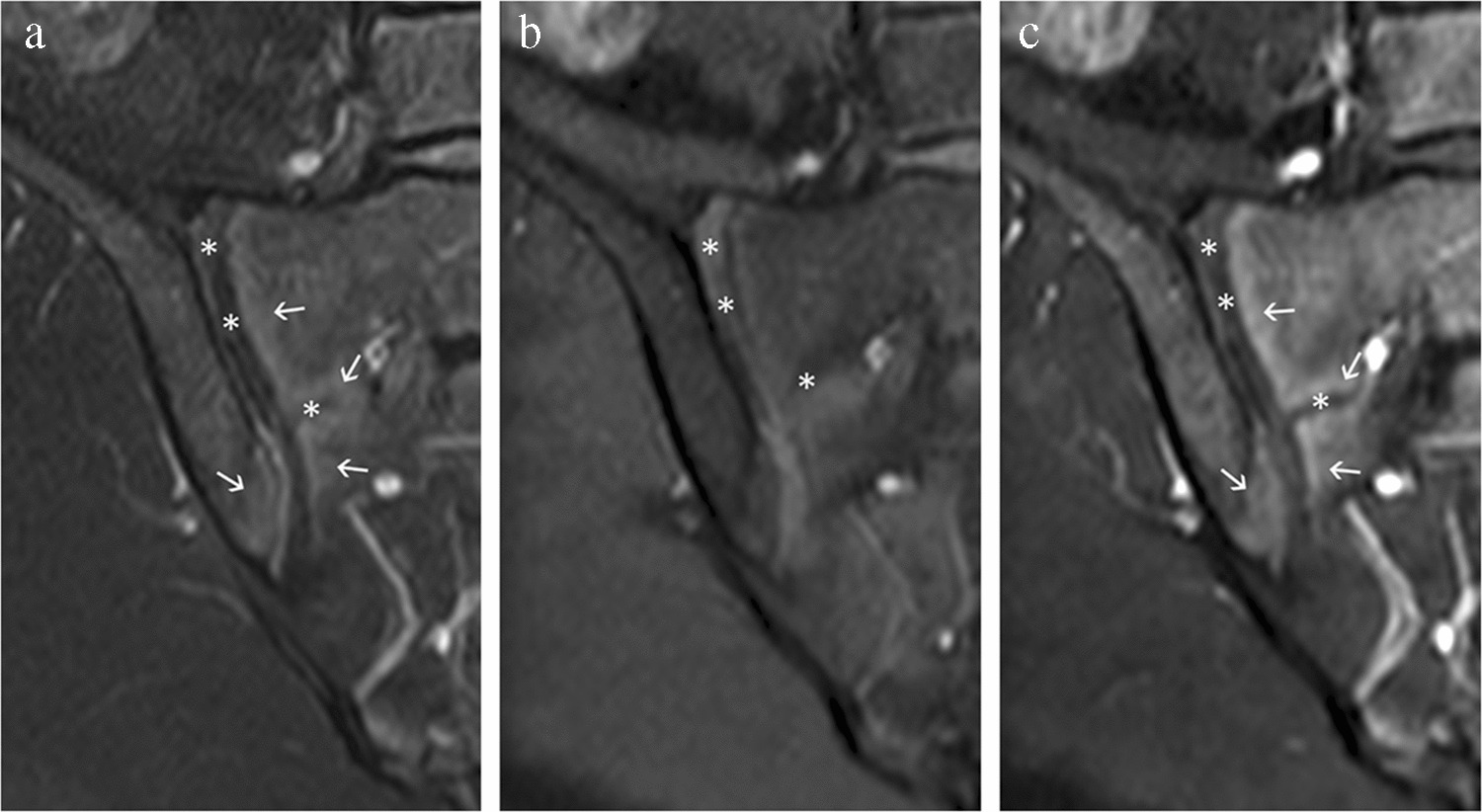
Axial MR images before and after (A/D, B/E, C/F) percentile-based intensity normalization, resulting in more consistent brightness, contrast, and saturation for downstream analysis. After image normalization, the popliteal artery (arrowhead) in figures A/D demonstrates increased conspicuity. Figures A and D demonstrate susceptibility artifacts (straight arrow) related to prior surgical hardware, while figures C and F show a Baker’s cyst (curved arrow). These cases were intentionally included to ensure dataset heterogeneity and to better reflect the variability encountered in knee MRI examinations from the general population
Model developmentThe internal dataset was split at the patient level into five folds using StratifiedGroupKFold, preventing data leakage and preserving balance between AATA-positive and negative studies. Approximately 60% of the data was allocated for training, 20% for validation, and 20% for internal testing. One fold was held out as the test set, while the remaining four were split into training and validation subsets, without rotating cross-validation.
To enhance robustness, data augmentation was applied to the training set. Small perturbations were introduced via ColorJitter (brightness, contrast = 0.2), RandomHorizontalFlip, and RandomRotation (± 30°), simulating variations in patient positioning. Images were resized to 224 × 224 pixels and normalized using the training set’s mean and standard deviation. Although originally in grayscale, each image was replicated across three channels (3 × 224 × 224) for compatibility with the pretrained model.
A custom CNN was developed with Python 3.8.10 and PyTorch 2.0.1, based on a ResNet10T [12] model from the timm library, pretrained on a large-scale image dataset. A two-dimensional architecture was chosen to prioritize methodological simplicity and scalability. Residual blocks with batch normalization and ReLU activations culminated in global average pooling. The pretrained feature extractor was kept up to its penultimate layer, followed by a custom head consisting of two Dropout layers (p = 0.3), a fully connected layer reducing 512 features to 8 with ReLU, and a final linear output producing a single logit. This architecture contains ~ 5.44 million trainable parameters.
Training used a batch size of 128 and binary cross-entropy loss with logits. Adam was employed (learning rate = 0.001, weight decay = 1 × 10−4, L1 penalty = 1 × 10−5), and an exponential scheduler (gamma = 0.9) reduced the learning rate each epoch for stability.
Evaluation and statistical analysisTo evaluate the model, slice-level predictions were first generated, with each MRI slice receiving a probability indicating the likelihood of containing the vascular anomaly. These per-slice probabilities were then aggregated to the study level by computing the mean probability for all slices belonging to a given MRI study. A suitable probability threshold was determined using the validation set, and this threshold was chosen to maximize the F1-score, which balances precision and recall, reflecting the clinical trade-off between false positives and false negatives. The same threshold was subsequently applied to internal and external test sets.
Several metrics were used to quantify performance at the patient level, including the binary cross-entropy loss, F1-score, precision, recall, and area under the receiver operating characteristic curve (AUC-ROC). While the slice-level analysis provided insights into how well individual images were classified, the study-level evaluation was more clinically meaningful, as it reflected the final diagnostic determination for each patient’s entire MRI examination.
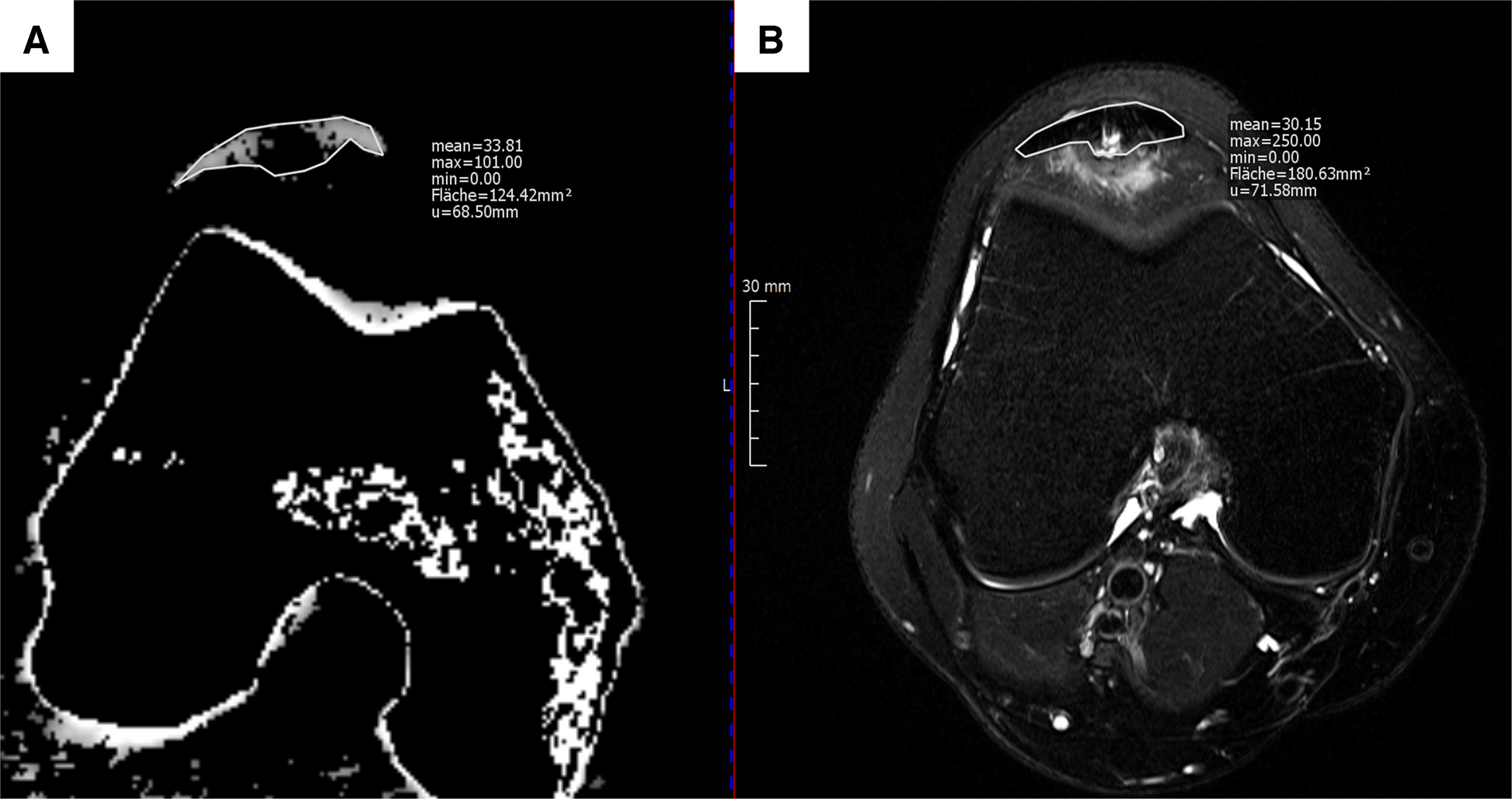
Sanity checkTo evaluate the model’s interpretability and gain insight into how the trained CNN identified the AATA, a Gradient-weighted Class Activation Mapping (GradCAM) analysis was conducted on a subset of the internal test set. Specifically, five AATA-positive cases that were correctly classified and five AATA-negative cases that were misclassified were selected for closer inspection. GradCAM was applied at the final convolutional layer of the model, capturing the spatial locations that contributed most strongly to the network’s decision.
These GradCAM heatmaps allowed visual verification of whether the network was focusing on anatomically meaningful areas consistent with the presence (or absence) of the tibial artery variant [13].
Comments (0)