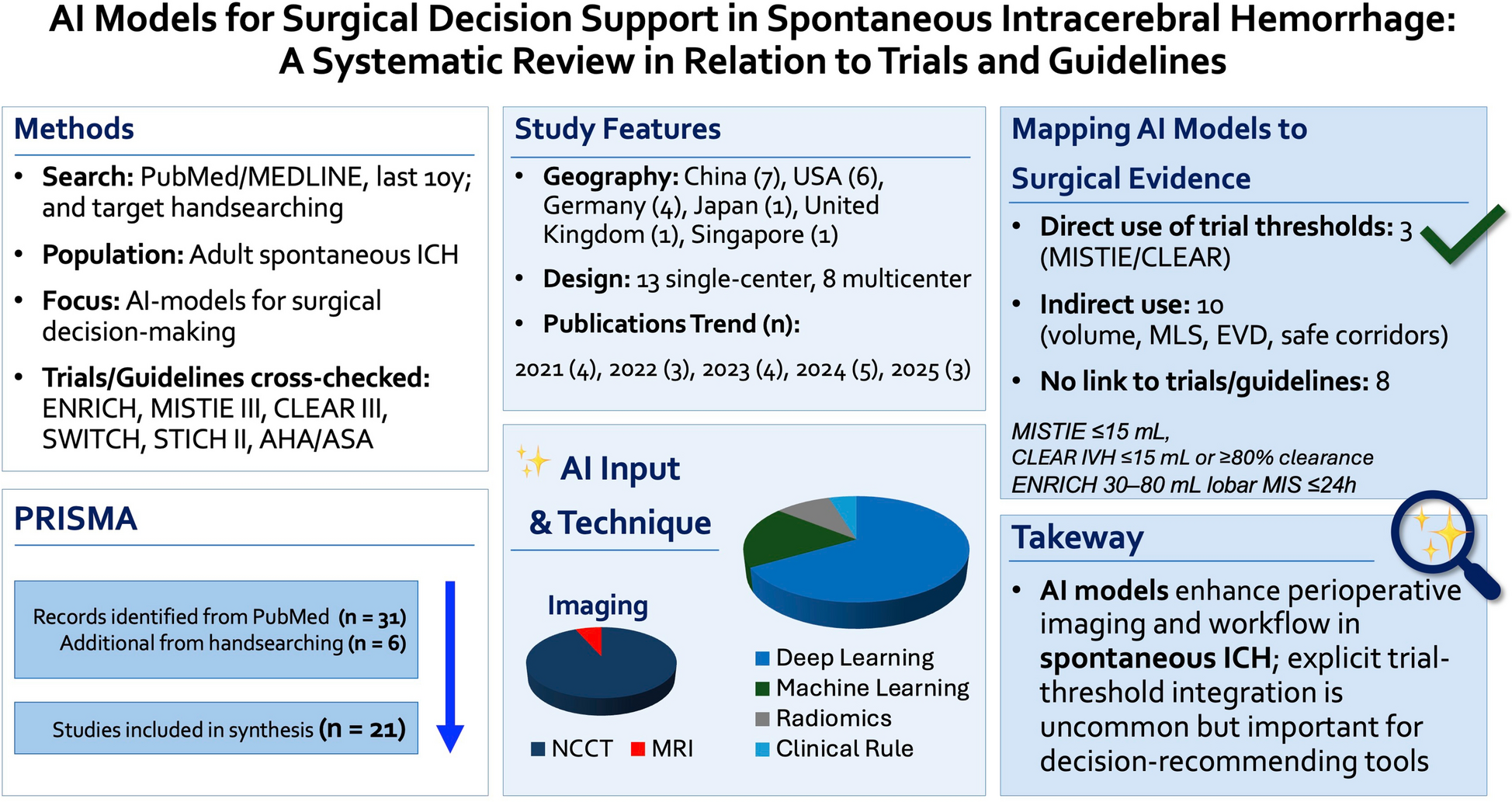
There is a growing number of publications evaluating AI-based models for analyzing spontaneous ICH in clinical practice. In our review, we identified 21 studies that met strict eligibility criteria, averaging approximately four publications annually over the past 5 years (four in 2021, three in 2022, four in 2023, five in 2024, and 3 in 2025 so far). This growth parallels the broader adoption of large language model (LLM) tools, such as ChatGPT and Gemini, which were introduced in late 2022. The widespread accessibility of AI through prompt-based interfaces seems to have accelerated the increased use of these technologies for clinical data analysis, including in the domain of spontaneous ICH.
Geographically, the studies primarily originated from major AI players, including the USA and China, with additional contributions from Germany, Japan, and Singapore. The cohorts ranged from single-case reports to multicenter electronic medical record datasets involving over 8000 patients, showing both the diversity and scope of available data sources. Recognizing concerns about selection bias in AI training caused by nonuniform data inputs, our review emphasizes that the included studies utilized a variety of clinical and imaging datasets. This variation may reduce, to some degree, the risk of overfitting or biased results from narrowly focused patient groups.
Regarding methodology, most studies relied exclusively on imaging inputs, predominantly noncontrast CT, with only one study using MRI for trajectory planning [34]. A smaller group combined imaging features with limited clinical variables. Deep learning frameworks were the most common analytical approach (14/21 studies), while the remainder employed classical machine learning or radiomics-based methods. Since deep learning is a subset of machine learning, these findings indicate that machine learning remains the primary analysis method in this field. In addition, all studies used retrospective data, indicating that AI tools were not applied for real-time prediction but for analyzing existing clinical datasets. This is particularly important, considering the broader challenges of prospective predictive AI, where factors such as numerous variables, randomness, and principles from game theory can reduce predictive accuracy. In contrast, retrospective analyses of real-world clinical data, as in the reviewed studies, can provide more reliable insights.
The identified models addressed a variety of perioperative tasks, including postoperative quality assurance (such as residual hematoma volume, drain position, and changes in midline shift), trajectory planning for catheter or endoscopic access, postsurgical prognosis, workflow optimization and timing, complication-risk prediction, and treatment-effect modeling. The most common applications focused on imaging-derived surgical endpoints—specifically residual hematoma volume, drain positioning, and midline shift dynamics—highlighting the fundamental role of imaging in postoperative evaluation. This pattern aligns with the historical development of AI, where imaging-based outcome assessment has been the earliest and most consistent application.
Alignment with Surgical Trials and Guidelines
Most AI models for spontaneous ICH are developed independently of randomized trial protocols and are not expected to explicitly reproduce trial eligibility criteria or guideline decision rules. Accordingly, the absence of direct trial encoding should not be interpreted as a deficiency. Instead, the purpose of this review was to provide a descriptive crosswalk between AI-derived inputs and outputs and the constructs used in major surgical trials and guidelines. Of the 21 included studies, 3 demonstrated direct evidence anchored to randomized surgical trials, 10 were indirectly anchored through trial-relevant constructs, and 8 had no comparison with trial or guideline criteria.
Across the included studies, AI models most frequently targeted variables aligned with trial- and guideline-relevant constructs, including hematoma and intraventricular hemorrhage volumetry, midline shift, residual clot volume after evacuation, catheter or drain placement, and workflow or time-to-intervention metrics. These variables correspond to technical endpoints and perioperative targets used in trials such as MISTIE III, CLEAR III, and ENRICH, even when trial-specific thresholds were not explicitly encoded. Fewer models addressed functional outcomes in a manner directly comparable to primary trial endpoints (e.g., mRS at 90–180 days), and explicit implementation of enrollment windows or decision thresholds from ENRICH, STICH II, or SWITCH was rare.
Several AI applications identified in this review automate measurements that are traditionally time-consuming or subject to interobserver variability, including volumetry, residual volume targets, IVH clearance, and midline shift. Automating these measurements may improve consistency in real-world practice, support quality assurance, and facilitate trial workflows or post hoc analyses. When AI systems are intended to recommend interventions (rather than automate measurements), it is helpful to specify a priori how outputs will be evaluated—for example, against trial/guideline constructs when appropriate and/or against independently learned decision boundaries—so that benefit, safety, and generalizability can be assessed transparently.
Beyond replicating established thresholds, AI models often incorporate additional imaging features, radiomic patterns, or multivariable risk profiles not explicitly used in existing trials. When consistently observed across independent cohorts, these predictors may inform future trial design by enabling eligibility enrichment, refining imaging-based surrogate endpoints, or identifying patient subgroups most likely to benefit from specific surgical strategies. In this context, the value of AI lies not in strict adherence to historical trial criteria but in providing data-driven insights that can be prospectively tested within rigorous trial frameworks.
Limitations
This review has limitations that warrant acknowledgment. All included studies were retrospective, which restricted their ability to inform real-time clinical decision-making and left them vulnerable to the inherent biases of observational data. The heterogeneity of AI methodologies—ranging from classical machine learning to deep learning and radiomics-based approaches—precluded quantitative synthesis, necessitating a descriptive analysis rather than a meta-analysis. While the geographic diversity of studies suggests broad global interest, the predominance of single-center cohorts limits external generalizability. Only a few studies explicitly evaluated model outputs against trial- or guideline-defined constructs (e.g., enrollment criteria, technical targets, or prespecified endpoints), which constrained this crosswalk’s ability to compare AI-derived decision boundaries with established evidence frameworks (without implying that such concordance is required for AI model validity). Future prospective multicenter studies should prioritize external validation, calibration, and prespecified benchmarking against clinically meaningful outcomes (including trial endpoints where relevant), rather than assuming concordance with historical thresholds.
Clinical ImplicationsClinical Correlation with the Review findings
This review indicates that contemporary AI in ICH surgery is most effective when it focuses on imaging-derived perioperative endpoints—such as hematoma/IVH volumetry, drain detection/coverage, residual volume, and midline shift—because these variables are routinely obtained, time-sensitive, and tightly coupled to operative assessment. In this context, even models that are only indirectly aligned can offer valuable clinical support by improving measurement consistency, reducing interobserver variability, and standardizing postoperative quality assurance without dictating treatment decisions.
How Alignment Influences Real-World Decision-Making
The relevance of trial alignment depends on the intended clinical role. For tools used as bounded assistants (such as segmentation, volumetry, quality assurance, and workflow triage), the absence of explicit RCT thresholds does not diminish their value; clinicians can incorporate outputs into existing decision frameworks. For AI systems providing treatment recommendations (such as surgery/no surgery, timing, or technique), it is useful to specify how the decision boundary will be evaluated relative to existing evidence (including trials/guidelines when relevant) and/or independent performance targets. In addition, deployment should incorporate safeguards to prevent automation bias (e.g., human-in-the-loop review, transparent reporting of uncertainty, and ongoing monitoring). Importantly, strict adherence to historical trial criteria should not be seen as a ceiling on innovation; instead, it should serve as a reference baseline against which new strategies can be compared prospectively.
Need for Multimodal and Temporal Integration
A common gap across studies is the limited integration of nonimaging information. Surgical ICH decisions are inherently multimodal and time-dependent, involving neurological examinations, severity scales, physiology, deterioration trajectories, and time-to-intervention. Future systems should therefore go beyond imaging-only pipelines and intentionally integrate clinical, physiological, and temporal data with radiologic features and trial-defined targets, enabling models that mirror real-world bedside decision-making pathways rather than isolated imaging tasks.
Ethics, Translational Informatics, and Evidence-Based Implementation
Translating AI tools into neurocritical care requires more than just technical performance: models must undergo external testing on independent datasets, be monitored for performance drift, and be deployed with clear accountability and clinician oversight. Ethical considerations include interpretability proportional to risk, mitigation of automation bias, and transparency regarding model limitations and data provenance. Trial-grade repositories and benchmarking resources (including VISTA-ICH) can facilitate reproducible evaluation and external testing, helping shift AI from promising retrospective tools toward evidence-based instruments that can be safely integrated into surgical decision support.
Can AI Assist in Clinical Decision-Making for ICH Management, and Might it Eventually Reshape Surgical Indications in a Similar Way to CT Scanning?
Our synthesis suggests that while AI has shown promise in technical endpoints (such as volumetric precision and postoperative quality assurance), its integration into surgical decision frameworks remains incomplete. To advance, AI systems intended for higher-stakes decision support should move beyond isolated imaging outputs toward multimodal, time-aware modeling and be evaluated prospectively for clinical impact. For such systems, trial/guideline constructs can serve as useful external benchmarks, but models may also define independent decision boundaries that require separate validation for safety, benefit, and generability.

Comments (0)