
Remember me

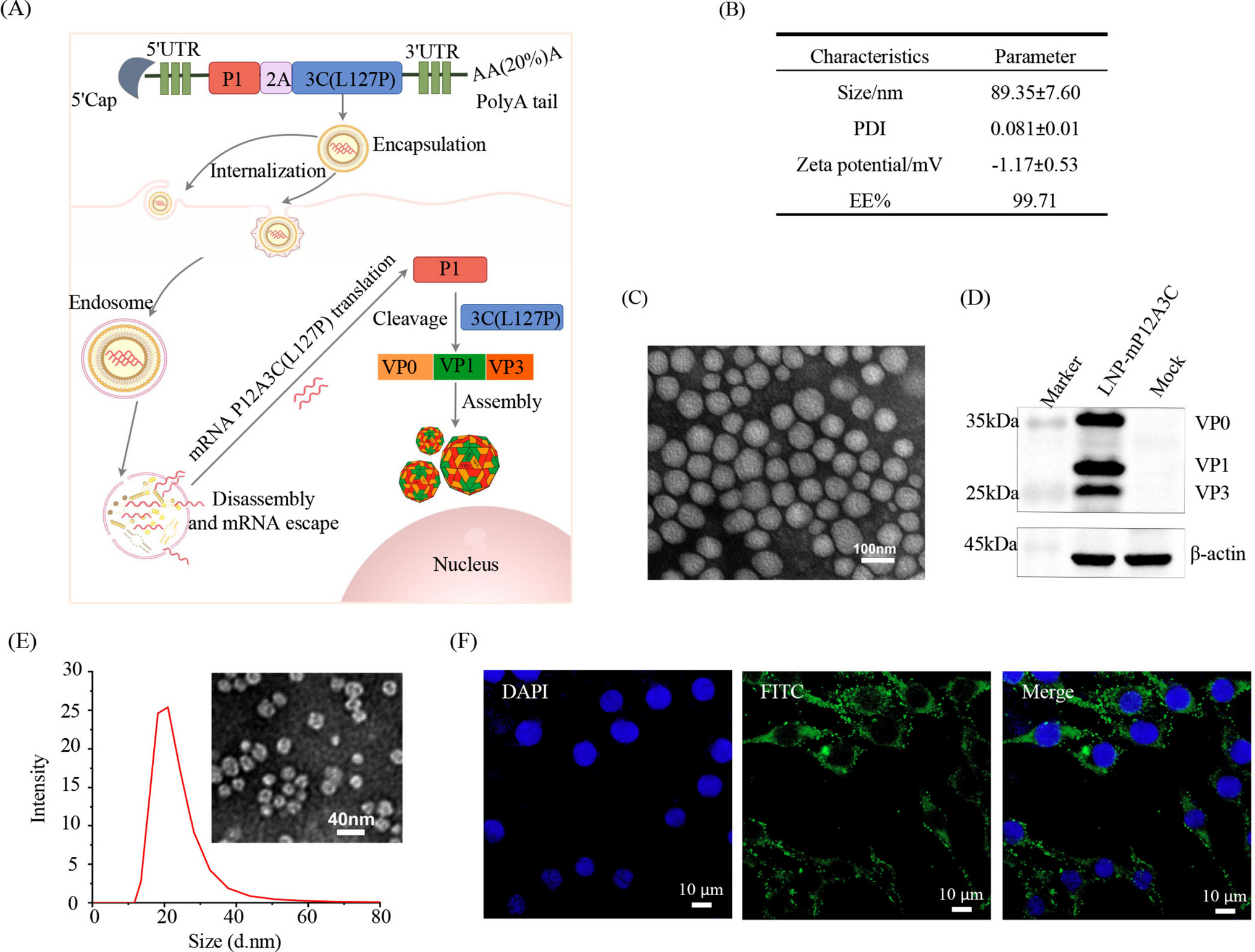
The CBS1807 strain of L. starkeyi was used in this study. GY medium (\(10\%\) glucose, \(1.0\%\) yeast extract) was used for the liquid culture, while YPD medium (\(2.0\%\) glucose, \(2.0\%\) peptone, \(1.0\%\) yeast extract, \(2.0\%\) agar) was used for the plate culture. Single colonies of L. starkeyi cultured on plates were inoculated into 50 mL of YPD medium in 200-mL baffled flasks and incubated with agitation at 130 rpm for 3 days at \(30^\circ \)C (pre-culture). The pre-culture solution was then inoculated into 50 mL of GY medium in a 200-mL baffled flask, with the initial cell concentration adjusted to \(OD600 = 1\). The cells were cultured with agitation at 130 rpm for 7 days at \(30^\circ \)C, and samples were collected every 8 h.
Fig. 1
Illustration of z-stack images. Green points show the coordinate (X, Y, z) \((z=1,2,\cdots ,N_z)\), where X and Y are constants, and z changes along the depth direction. In this paper, we refer to an arbitrary image obtained by confocal microscopy at a given z-stack depth as a z-stack image. We denote a collection of z-stack images \((z=1, 2, \cdots , N_z)\) that capture the same region in the xy plane by a z-stack image set
Measurement of lipid production by an invasive methodThe invasive method was based on the literature (Kitahara et al 2023). Cell pellets from 1 mL of the culture medium were lyophilized, and the weight of the dried cells was determined. Intracellular lipids were extracted from the dried yeast cells. The dried cells were suspended in 200 \(\mu \)L of an ethanol/petroleum ether mixture (3:1, v/v) containing 1.8 g of zirconia beads (0.5 mm in diameter) and disrupted using a multi-bead shocker (MB1001C, Yasui Instruments, Osaka, Japan) under the following conditions: \(4^\circ \)C, 2700 rpm, ON TIME of 30 s, OFF TIME of 30 s, repeated for 30 cycles. Next, 800 \(\mu \)L of the ethanol/petroleum ether mixture was added to the cell lysate, and the mixture was stirred at room temperature for 10 min using a microtube mixer (Tommy Seiko) to extract lipids. The lipid extract was centrifuged at 14, 000 rpm for 10 min at \(4^\circ \)C, and the lipid content was measured using an E-test Wako TG kit (Fujifilm Wako Pure Chemicals Corporation, Osaka, Japan) according to the manufacturer’s instructions. At each time point, three independent flask cultures were prepared and used as biological replicates (\(N=3\)). For the invasive biochemical assays (lipid and dry cell weight), one measurement per flask was obtained.
The method for image processing proposed in this study can non-invasively estimate the lipid production status. The invasive biochemical method explained here was used as a reference method to verify the effectiveness of our method described in “Results and discussion.”
Data for image processingWe used a Nikon A1 confocal microscope.Footnote 1 The magnification of the object lens was 100 times, and the software was NIS-Elements ER ver.5.21.00. We manually determined the top and bottom for the shooting range, and the interval between adjacent z-stack images was set to 3 µm. As a result, the number of z-stack images for each shooting point was from 22 to 49. As shown in Fig. 1, the confocal microscope can obtain an image with a specific focal depth. In other words, it can block the out-of-focus light above and below the focal depth (Croix et al 2005; Elliott 2020). In addition, a position of the z-stack image was denoted by (x, y, z) \((x=1,2,\cdots ,N_x, \ y=1,2,\cdots ,N_y, \ z=1,2,\cdots ,N_z)\). Here, \(N_x\) and \(N_y\) are the width and height of the focal plane, and \(N_z\) is the z-stack depth. \(N_x\), \(N_y\), and \(N_z\) were set to 256, 256, and \(\\), respectively. Moreover, the pixel value at position (x, y, z) was denoted by v(x, y, z) \(\in [0, 255]\).
Fig. 2
Examples of ground truth candidates for different Th. Red circles show areas in which the same yeast moved. Yellow circles show areas in which yeast is observed in a small number of z-stack depths. In this study, we aimed to detect lipid droplets in the yellow circles, but not in the red circles
To prepare ground truths for extracting regions of lipid droplets, we stained L. starkeyi with BODIPY (Takayama 2021). Our microscope can simultaneously shoot brightfield images and fluorescence images without misregistration. We used brightfield images as input for detection and fluorescence images for defining ground truths. The fluorescence images allow us to vividly observe regions of lipid droplets only.
We describe the specific processing steps for defining ground truths below. First, fluorescence images were denoted by F(x, y, z). Bright regions can be considered candidates of ground truths. Thus, we applied Otsu’s binarization method (Otsu 1979) to each of F(x, y, z) to obtain the binary image B(x, y, z). However, this may result in over-detection of background regions when the entire image is dark. In the case of over-detection, the average of each of B(x, y, z) becomes larger than the appropriate candidate of ground truths. Thus, we further applied Otsu’s binarization method (Otsu 1979) to the averages calculated for each of B(x, y, z), removing the over-detected images from B(x, y, z). Binarization was performed for each cultivation time. Then, the remaining images were denoted by T(x, y, z), where elements corresponding to lipid droplets are 1 and the other elements are 0.
In addition, T(x, y, z) may include over-detection of moving yeasts. We removed this type of over-detection to obtain the ground truth image A(x, y) as follows:
$$\begin A(x, y) = 1 & \ \ \ \text \ \ \ \sum _^ T(x, y, z) \ge Th, \\ 0 & \ \ \ \text . \end\right. } \end$$
(1)
Here, Th is the threshold. We show examples of ground truth candidates for different Th in Fig. 2. As red circles in the figure show, small Th is likely to over-detect lipid droplets for moving yeast. In contrast, as yellow circles show, large Th is likely to under-detect lipid droplets for yeast observed in a small number of z-stack depths. In this study, we determined \(Th = 5\) by considering this trade-off relationship based on our visual inspection. However, users can set another Th depending on how much over-detection and under-detection are allowed.
We prepared pairs of z-stack brightfield images and corresponding ground truths every 8 h of culture time from 8 h to 168 h. The number of z-stack brightfield image sets was 210, and the number of all images was 3, 360.
Fig. 3
Z-stack images with different focal depths contain regions of lipid droplets with a different brightness level. a Z-stack image. b Z-stack image with a focal depth deeper than that of a. c Lipid droplets in the oleaginous yeast. We show lipid droplets in white and other regions in black
Optical properties of L. starkeyiOur finding is illustrated in Fig. 3. In regions of lipid droplets, the brightness changed significantly along the z-stack depth. In other regions, such as the background, cell wall, and vacuole, the brightness did not change significantly. This indicates that the refractive index of lipid droplets differs from those of other organelles. Previous studies have reported that the refractive index of lipid droplets differs from that of the cytoplasm in cells (Kim et al 2016; Beuthan et al 1996). To the best of our knowledge, this study is the first to quantify the visual characteristics of confocal microscopy z-stack images of L. starkeyi. The next section details how this unique feature of lipid droplets, that is, the large brightness change along the z-stack direction, is implemented in the proposed method.
Method for extracting regions of lipid dropletsWe consider the fixed position in the xy plane, which is denoted by (X, Y), where X and Y are constants. The brightness change along the z-stack depth at this position is quantified by observing v(X, Y, z) \((z = 1, 2, \cdots , N_z)\). To this end, we introduce the following metrics into our method:
$$\begin C(X, Y)= & \frac, \end$$
(2)
$$\begin V(X, Y)= & \frac \sum _^ \ ^ . \end$$
(3)
In these equations, G(X, Y), L(X, Y), and \(\mu (X, Y)\) are defined as follows:
$$\begin G(X,Y)= & \max \, \end$$
(4)
$$\begin L(X,Y)= & \min \, \end$$
(5)
$$\begin \mu (X,Y)= & \frac \sum _^ v(X,Y,z). \end$$
(6)
Fig. 4
Calculation of two parameters of visual features, i.e., Michelson contrast in Eq. 7 and variance in Eq. 8. a Target image. b Result of calculating Eq. 7. c Result of calculating Eq. 8. d Ground truths for regions of lipid droplets. We show lipid droplets in white and other structures in black
Here, C(X, Y) and V(X, Y) are the Michelson contrast (Liu et al 2015; Xu and Nakajima 2013) and variance, respectively. Furthermore, normalization is performed so that we can subsequently input the values into the deep learning model as follows:
$$\begin M_1(X, Y) = 255 \times C(X, Y), \end$$
(7)
$$\begin M_2(X, Y) = 255 \times \frac \in S_X, \tilde \in S_Y}\, \tilde)\}} \in S_X, \tilde \in S_Y}\, \tilde)\} - \underset \in S_X, \tilde \in S_Y}\, \tilde)\}}, \end$$
(8)
where \(S_X = \\) and \(S_Y = \\). The specific implications for the above equations are explained below.
\(M_1(X, Y)\):
C(X, Y) is computed using Eq. 2, and its minimum and maximum values are 0 and 1, respectively.
By multiplying C(X, Y) by 255, \(M_1(X, Y)\), whose minimum and maximum values are 0 and 255, respectively, is obtained in Eq. 7.
\(M_2(X, Y)\):
V(X, Y), whose value is greater than or equal to 0, is computed using Eq. 3.
In Eq. 8, min-max normalization is applied to V(X, Y), resulting in minimum and maximum values of 0 and 1, respectively.
By multiplying the normalized result by 255 in Eq. 8, \(M_2(X, Y)\), whose minimum and maximum values are 0 and 255, respectively, is obtained.
Fig. 5
Unique characteristics of lipid droplets. a Brightness change along the z-stack depth in regions of lipid droplets. b Brightness along the z-stack depth in regions of the cell wall. c Brightness change along the z-stack depth in vacuole regions. d Brightness change along the z-stack depth in background regions. In each figure, plots for ten positions are shown
\(M_1(X, Y)\) and \(M_2(X, Y)\) are typical metrics to represent the brightness change corresponding to lipid droplets. We can use the ordinary contrast ratio G(X, Y) /L(X, Y) as an alternative of \(M_1(X, Y)\). However, the ordinary contrast ratio is likely to be saturated owing to very small L(X, Y). Thus, in this study, we use the Michelson contrast as \(M_1(X, Y)\). Moreover, we use the variance as \(M_2(X, Y)\) to represent not only the maximum and minimum of v(X, Y, z) but also the distribution of pixel values. Because there are cells at various positions along the z-stack depth, bright positions along the z-stack depth depend on each cell. We notice that \(M_1(X, Y)\) and \(M_2(X, Y)\) are robust against this uncertainty.
We develop a semantic segmentation algorithm into which we input the calculated parameters of the visual features, i.e., \(M_1(X, Y)\) and \(M_2(X, Y)\). As shown in Fig. 4, Eq. 7 tends to extract regions of whole lipid droplets. However, Eq. 7 may also extract regions of other organelles. In contrast, Eq. 8 tends to accurately extract regions of lipid droplets only, although non-detection is also likely. Owing to the complementarity of the two kinds of contrast parameters, the proposed method can accurately distinguish lipid droplets from other organelles. This is an advantage of our method over existing methods into which we simply input pixel values.
We then combine the deep learning model with the parameters of the visual features in Eqs. 7 and 8. In this study, we adopt Mask R-CNN (He et al 2017), which is used in a previous study (Lu et al 2019), as the deep learning model. The model used in the experiments was “maskrcnn_resnet50_fpn,”Footnote 2 from the torch vision library. In this study, the experiment was conducted using a randomly initialized model that was not pre-trained. The number of classes was set to two, corresponding to regions of lipid droplets and regions of other structures. In the experiments shown in the next section, we set the number of epochs to 200. Early stopping was conducted if the F1 score for the validation set did not improve over 10 consecutive epochs. The stochastic gradient descent (SGD) method (Robbins and Monro 1951) was used for optimization, with a batch size of four. The learning rate was gradually reduced using CosineAnnealingLR.Footnote 3 Additionally, invalid annotations, such as isolated regions of approximately one pixel in the ground truth images, were removed prior to training.
Comments (0)