
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Remember me
Blood pressure (BP) measurement and electrocardiography are two complementary methods widely used for cardiovascular monitoring and diagnosis. BP is influenced by cardiac mechanical function and systemic vascular resistance (Mousavi et al 2024). When the heart contracts, it creates a pulsatile pressure wave in the arterial system (Nichols et al 2022). The systolic blood pressure (SBP) represents the maximum and the diastolic blood pressure (DBP) reflects the minimum of the pressure wave in each cardiac cycle, both of which are time-varying due to natural fluctuations and measurement errors and biases, such as those caused by respiration (Pickering et al 2005, Mousavi et al 2024, Mukkamala et al 2025). Both tonic and cyclic fluctuations in the BP wave provide critical insights into cardiovascular health, making BP monitoring a standard in patient care and an effective tool for cardiovascular diseases (CVDs) diagnosis and management (Muntner et al 2019, Mousavi et al 2024). The guidelines for hypertension recommend that symptomatic individuals regularly monitor their BP (Reboussin et al 2018).
On the other hand, the electrocardiogram (ECG) measures the electrical function of the heart and captures the electro-physiological patterns of depolarization and re-polarization during each cardiac cycle (De Luna et al 2006, Kaplan Berkaya et al 2018). ECG recording is cost-effective, accurate and commonly available in most health centers and outside clinical settings using portable and wearable ECG monitors, making it suitable for long-term cardiac monitoring and CVD detection (Shah et al 2021, Neri et al 2023, Muzammil et al 2024).
Previous studies have attempted to estimate BP using machine learning (ML) or deep learning (DL) methods from only photoplethysmography (PPG) signals (Mousavi et al 2019, Ma et al 2023, Apple Inc. 2025), or from a combination of PPG with other biosignals such as the output signal of a Hall sensor (Lee et al 2011, Nam et al 2013), the modulated magnetic signature of the blood (Zhang et al 2016), ballistocardiography (Chen et al 2013, Kim et al 2018), and impedance plethysmography (Liu et al 2017, Huynh et al 2019). Researchers have further hypothesized the feasibility of estimating BP using only ECGs and electro-physiological features (Mousavi et al 2019, 2020, Bird et al 2020, Sato 2021, Landry and Mukkamala 2023). Rapid advancements in home care devices, such as portable ECG devices, smartwatches, and smartphones, have further motivated efforts to integrate BP measurement functionality into these technologies (Shah et al 2021). However, the literature is divided on whether BP can be accurately estimated from ECGs: those whose results support this hypothesis and those that do not.
Methodologically, the literature on the relationship between ECG and BP has addressed two main problems: (1) estimating BP values, and (2) predicting BP categories (e.g. normal vs. hypertensive cases) using simultaneous or recent ECG records (Angelaki et al 2022, 2024, Liang et al 2024). Technically, the first problem requires a regression-based ML framework, while the second is a classification task. In this study, we primarily focus on the BP prediction problem as our main objective, but we also present BP category estimation results on the same dataset to enable comparisons in future research.
In 2008, Ali Hassan et al (2008) developed a linear regression model to estimate SBP from heart rate (HR) extracted from 30 s ECG recordings of 10 normal-ECG subjects. BP values were also measured manually. For each individual, 20 records were used to develop the regression model and the 10 remaining ones were used for testing. To generalize SBP estimation for new subjects, the final model slope was obtained by averaging the individual regression slopes across all participants.
In 2018, Simjanoska et al (2018) developed an ML model for estimating BP using ECGs. The study analyzed 3129 ECGs with a length of 30 s, from 51 subjects, including both healthy and unhealthy individuals. The feature vector consisted of seven components: signal mobility, signal complexity, fractal dimension, entropy, autocorrelation, age, and hypertension classification. Four models were developed: one classification model to predict the hypertension group, and three regression models to estimate SBP, DBP, and mean arterial pressure (MAP). The mean absolute error (MAE) and standard deviation (SD) of the regression model were 7.72±10.22 mmHg for SBP and 9.45±10.03 mmHg for DBP. The group further extended their study by employing a different pre-processing approach, adjusting the cutoff frequency of filters, and utilizing ECGs with different lengths of 10, 20, and 30 s (Simjanoska et al 2020). The results showed an MAE and SD of 16.60±11.05 and 9.24±7.85 mmHg for SBP and DBP, respectively.
In 2020, Miao et al (2020) developed a DL model for estimating BP from ECG, utilizing a residual network and long short-term memory, to capture both time and spatial information from ECGs. The model was trained and tested on the public Multiparameter Intelligent Monitoring in Intensive Care (MIMIC-III) database, which includes ECG and invasive BP information from individuals in critical care units (Johnson et al 2016). The pre-processed dataset consisted of 1711 subjects and 897 743 records, each with a length of 2.5 s. The developed approach achieved a ME with a SD of 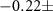 5.82 mmHg for SBP and
5.82 mmHg for SBP and 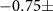 5.62 mmHg for DBP. The correlation coefficients between the estimated and actual values were 0.88 and 0.71 for SBP and DBP, respectively. Table 1 presents the results of studies based on ML and DL approaches for estimating BP using ECGs.
5.62 mmHg for DBP. The correlation coefficients between the estimated and actual values were 0.88 and 0.71 for SBP and DBP, respectively. Table 1 presents the results of studies based on ML and DL approaches for estimating BP using ECGs.
Table 1. Comparison of studies using machine learning and deep learning (DL) models for blood pressure estimation based solely on ECG data.
DataSBP (mmHg)DBP (mmHg)Study# Records# SubjectsECG len.# FeaturesMESTDMAESTDρMESTDMAESTDρ (Simjanoska et al 2018) 201831295130 s7——7.710.2———9.510.0— (Mousavi et al 2018) 201866022015 s———12.812.2———6.06.4— (Simjanoska et al 2020) 202031295130/20/10 s7——16.611.1———9.27.9— (Banerjee et al 2022) 20222000—16 s—0.89.16.0——0.16.23.5—— (Wuerich et al 2022) 2022—9424 s345.97.20.9————3.75.20.92 (Syah et al 2023) 202356—20 s3——2.81.50.95——2.92.10.93 (Aldein et al 2023) 20234904—32 s———64.5———2.53.7— (Kuzmanov et al 2024) 2024130 461—30 s———10.9————6.6—— (Aldein et al 2025) 202512 00094232 s———5.504.28———2.503.80— (Miao et al 2020) 2020897 74317112.5 sDL–0.110.07.1—0.880.06.34.6—0.71 (Fan et al 2021) 202121 422—10 sDL0.110.87.7——0.15.94.4—— (Fan et al 2020) 202121 422—10 sDL0.210.87.2——1.25.93.9——At the same time, some research has questioned the feasibility of ECG-based BP estimation. Sato et al (2021) and Landry and Mukkamala (2023) are two studies in this category, which based on the electrophysiology of BP and ECG and the shortcomings in the reported results in the literature, have debated that accurate ECG-based BP estimation is unfeasible. They have not conducted any independent experiments to support this claim.
This study aims to explore the feasibility of estimating BP using only ECGs using ML models trained on a large ambulatory dataset, while addressing shortcomings in former methodologies. A comprehensive set of 278 engineered features, derived from the time, frequency, and time–frequency domains of the ECGs, and used as inputs to regression models for BP estimation. The models are designed to be demographic-aware by incorporating the sex and age of subjects, which are known to significantly influence BP values (Mousavi et al 2024). All ECGs are standardized to a fixed length of 30 s to ensure consistency across records. Detailed data cleaning, sub-sampling, and standard cross-validation techniques are used to ensure that the results are not biased. Our findings most strongly support studies that have concluded accurate ECG-based BP estimation is unfeasible.
2.1. DatabaseThe data used in this study consists of ECG and BP measurements from two databases collected over two years from August 2019 to March 2021 by AliveCor (Mountain View, CA, USA), using the following devices:
(i)
OMRON Complete (Omron Healthcare, Kyoto, Japan), which is an integrated BP monitor and single-lead ECG;
(ii)
KardiaMobile (AliveCor, Mountain View, CA, USA) for collecting single-lead ECGs and independent BP readings from portable BP devices (Omron Healthcare, Kyoto, Japan).
To note, the ECG and BP were self-recorded asynchronously in non-clinical settings, with variable numbers of BP and ECG per subject and varying time gaps between the two modalities (varying between seconds and hours). The ECG dataset comprises 180 790 records from 10 624 subjects, with a minimum time gap of 30 seconds between two consecutive ECG recordings for each unique subject. ECGs were recorded at a sampling frequency of 300 Hz. The BP dataset consists of 21 227 729 measurements, corresponding to 297 965 subjects. A total of 10 346 subjects, which were common between the ECG and BP datasets, were shortlisted for this study.
2.2. Data cleaningThe data cleaning process is summarized in figure 1. Accordingly, records were selected from the matched dataset based on the following criteria:
(i)
The analysis was limited to adult male and female subjects aged between 18 and 90 years at the time of ECG recording. Subjects with unknown sex or with age outside![$[18,90]$](https://content.cld.iop.org/journals/0967-3334/46/11/115005/revision2/pmeaae1926ieqn3.gif) were excluded from the analysis.
were excluded from the analysis.(ii)
Records with misreported DBP values higher than SBP were removed. Then, thresholds were applied to define valid BP ranges. Valid BP ranges were set to DBP between 20–200 mmHg and SBP between 30–300 mmHg. These thresholds are consistent with the pre-processing approach used in our previous study, which analyzed approximately 75 million BP values from the general population (Mousavi et al 2024).(iii)
The dataset included ECG classification labels generated by AliveCor’s proprietary ECG analysis software, which labels signals as ‘sinus rhythm’, ‘atrial fibrillation’, ‘bradycardia’, ‘tachycardia’, ‘unclassified’, ‘too short’, ‘unreadable’ and missing values. Records labeled as ‘unreadable’ or with missing labels were removed.
(iv)
For consistency, ECG record lengths were fixed to 30 s, and the records shorter than 30 s were excluded from the analysis. Previous studies indicate that this duration is sufficient for capturing essential ECG features, especially for rhythm analysis and heart rate variability (HRV) (Munoz et al 2015). 98% of the ECG database complied with this requirement. For consistency, the ECGs longer than 30 s were truncated to the first 30 s.(v)
The ECG and BP data were collected asynchronously, resulting in varying time gaps between the ECG and BP measurements of the same subject. Given that both signals naturally fluctuate over time, we defined a maximum allowable time gap such that BP variability within this window would be minimal—ensuring that estimating BP from ECG remained both meaningful and clinically relevant. To determine this threshold objectively, we referred to acceptable BP error margins from BP device standards and reported rates of short-term BP variability in the literature. Presumably, as long as the time-gap between ECG and BP collection is within these thresholds, any BP change during that interval would fall within an acceptable error margin—making the ECG-BP pairing valid for estimation purposes.According to the Association for the Advancement of Medical Instrumentation (AAMI) standard, the mean BP error in BP measurement devices should be less than 5 mmHg (Stergiou et al 2018). To identify the time window during which a 5 mmHg change in BP might occur, relevant literature was reviewed. Most studies reported mean BP differences over 30 min or longer intervals (Mancia et al 1983, Graham et al 1995, Clement et al 2003, Kario et al 2003, Okamoto et al 2009, Sayk et al 2010, Mancia 2012). From these studies, reported mean BP differences and their corresponding time windows were extracted to estimate the ‘rate of BP variation’ over time. Using these rates, the time intervals corresponding to the negligible 5 mmHg change were calculated by dividing 5 mmHg by the rate of change. The resulting estimates ranged from 3.5 to 38 min. The minimum value (3.5 min), was considered as the acceptable short-term window, which we considered as the maximum allowable time gap between ECG and BP recordings.(vi)
Many subjects had multiple BP measurements within the acceptable BP-ECG time interval window. For each subject and ECG, all BP measurements within the acceptable time window of (3.5 min) were averaged. Averaging BP measurements within short time windows is a standard procedure in clinical practice, which results in more accurate BP measurements (Mousavi et al 2024), and reduction of measurement biases (Nateghi and Sameni 2025).Figure 1. Data cleaning and workflow process for developing machine learning models to estimate blood pressure using only ECGs. Abbreviations: valid label: ‘sinus rhythm’, ‘atrial fibrillation’, ‘bradycardia’, ‘tachycardia’, ‘too short’, ‘unclassified’, invalid label: ‘unreadable’ and missing values. Additionally, in the final stage up to 6 records per subject were selected, based on the median number of records per subject after excluding an outlier with 3500 records and subjects with only one record.
Download figure:
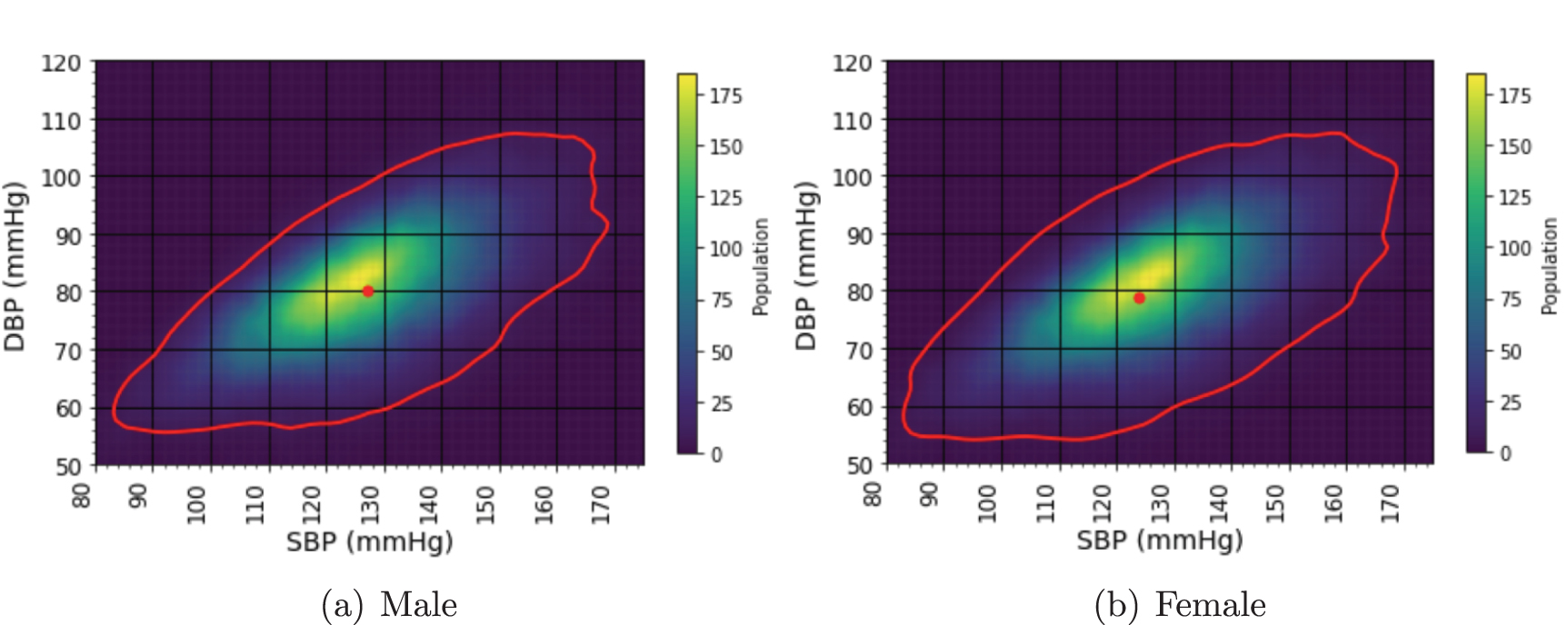
Standard image High-resolution imageThe final filtered dataset included 124 427 pairs of BP and ECG records from 7412 subjects. Table 2 summarizes the distribution of the final dataset by sex and ECG labels, where ‘Normal’ represents ‘sinus rhythm,’ while all other labels including ‘atrial fibrillation’, ‘bradycardia’, ‘tachycardia’, and ‘unclassified’ are considered ‘Abnormal’. Also, table 3 presents the statistical distribution of BP datasets by sex and ECG labels, and figure 2 illustrates the 95% percentile range contours for males and females BP distribution. The mean SBP and DBP for each group are marked with dots.
Figure 2. Comparisons of blood pressure distributions between sexes in the pre-processed data presented through heatmaps and contour plots, representing the 95% percentiles of the BP values within the contours. Dots indicate the mean SBP and DBP values. Mean SBP values are 127.1 and 123.8 mmHg, and mean DBP values are 80.2 and 78.9 mmHg for male and female subjects, respectively.
Download figure:
Standard image High-resolution imageTable 2. Distribution of the final processed ECG records based on sex and label.
Sex# Total# Abnormal# NormalFemale23 597284620 751Male100 83014 46286 368Table 3. Minimum, maximum, mean, and standard deviation of systolic and diastolic blood pressure (SBP and DBP, in mmHg) of the filtered dataset, categorized by sex and ECG label, for all records and those with sinus rhythm (normal).
SexBP typeECG labelMinMaxMeanSTDMaleSBPAll60227127.116.0MaleSBPNormal65227127.315.8MaleDBPAll4016580.210.5MaleDBPNormal4016580.110.2FemaleSBPAll61215123.817.0FemaleSBPNormal62215124.016.7FemaleDBPAll4014778.911.0FemaleDBPNormal4014778.810.82.3. ECG pre-processingThe ECG records were band-pass filtered with a band-pass frequency between 0.1 Hz and 100 Hz, and a notch filter at 50 or 60 Hz, depending on the local power line frequency. The notch filter was designed using a second-order infinite impulse response filter (iirnotch in MATLAB) with a quality factor (Q) of 40 and was applied.
2.4. Feature extractionA total of 280 features were extracted, comprising 128 interpretable features extracted from the ECG records using a codebase developed by our team (Sameni 2006–2025); 150 features extracted using the Black Swan codebase (Zabihi et al 2017); the time gap between the ECG and the average time of the corresponding BP measurements (within 3.5 min time windows); and the subject age. To enable the replication of the implemented process, the complete feature set is described below.
(i)
Beat signal-to-noise ratio (SNR): To quantify beat-to-beat morphological consistency in the ECG over the 30 s segment, a SNR index was computed and assigned to each beat. R-peaks were first detected using the OSET robust R-peak detector function peak_det_likelihood (Sameni 2006–2025), and individual beats were segmented using a window of W samples centered around each R-peak. Robust weighted average (RWA) and robust beat median (RBM) beats were then calculated, following the method in Leski (2002). For each beat, the residual was computed as the difference from the RWA or RBM beat, and the beat SNR was defined as the power ratio between the original beat and the mean/median-based residuals. These SNRs capture both morphological deviations and measurement noise.(ii)
HRV and HR metrics: After ECG R-peak detection, R-R intervals were computed and converted to instantaneous HR values in beats per minute (bpm). The HR sequence was next summarized using the mean, median, 5th percentile, and 95th percentile. HRV was assessed using the standard deviation of R-R intervals and the root mean square of successive differences (Clifford et al 2006).(iii)
Time interval measurements: Fiducial points for each beat were extracted using the fiducial_det_lsim function from OSET (Sameni 2006–2025). Using these points, key ECG time intervals were calculated, including the QRS complex duration, QT interval, PR interval, ST interval, PR segment level, and ST segment level. Additional intervals were computed between specific peak pairs: P–R, Q–R, S–R, and T–R, to capture more detailed temporal relationships between waveform components. Corrected QT intervals (QTc) were also derived using the Bazett (QTc-B) and Fridericia (QTc-F) corrections (Luo et al 2004).(iv)
Amplitude and morphological area metrics: Amplitude and area-based features were computed using fiducial points marking the onset, peak, and offset of each ECG waveform component. For each component, the amplitude and the area under the curve (sum of ECG values from onset to offset) were calculated. In addition, we computed the amplitude ratio of the R peak to other major peaks (P, Q, S, and T), and the amplitude difference between the S and T peaks across the ST segment.
(v)
Amplitude-to-timing ratios: For each beat, the difference between the R-peak amplitude and the amplitude of other peaks was divided by the time interval between the R peak and the corresponding peak, providing a measure of waveform shape (slope).
(vi)
Signal mobility and complexity: Mobility was computed as the ratio of the variance of the first derivative of the ECG to the variance of the ECG (Simjanoska et al 2018, 2020, Fuadah and Lim 2022). Complexity was calculated as the ratio of the variance of the second derivative to the variance of the first derivative, divided by the mobility value (Simjanoska et al 2018, 2020, Fuadah and Lim 2022).(vii)
Singular value decomposition (SVD) metrics: SVD has been shown to encode ECG beat variability (Zheng et al 2021). ECG beats were segmented around each R-peak with a window of the median beat-to-beat interval, and stacked to form a 2D matrix (number of beats times number of samples of the segmented beats) using the event_stacker function from OSET (Sameni 2006–2025), where each row represents one beat. SVD was then applied to this matrix to extract singular values. The resulting values were normalized by the largest singular value and used as features to capture the similarity and reproducibility of ECG beats across the segment. The number of non-zero singular values of a rectangular matrix is smaller than or equal to the minimum of its rows and columns, which in our case was the number of beats used to construct the stacked beat matrix. To ensure a fixed feature length across all subjects and records, the SVD-based feature vector was set to a length of 45, corresponding to the maximum number of beats over 30 s across all subjects. Shorter vectors were zero-padded to reach this length.(viii)
Black-Swan: This set includes 150 features developed by a top-performing team in the PhysioNet Challenge 2017 for atrial fibrillation classification (Zabihi et al 2017). The features span multiple domains, including time, frequency, time-frequency, phase space, and meta-level representations. This set has also been successfully applied in other ECG classification tasks (Bahrami Rad et al 2021, 2024, Koscova et al 2024).The amplitude, interval, and morphological features described above were computed per beat. These beat-wise values were then summarized using the mean, median, and SD to form fixed-length feature vectors.
2.5. ML modelsDecision tree-based regression models were used for their performance, their ability to handle feature sets with missing values, and their capacity to model complex and nonlinear relationships in data (Podgorelec et al 2002). This includes extreme gradient boosting, random forest (RF), CatBoost, and light gradient boosting machine (LightGBM).
2.6. Model developing and data splittingOur previous studies have shown that, at the population level, males exhibit higher BP than females (Mousavi et al 2024). Therefore, our SBP and DBP estimation models were trained separately for each sex group. Furthermore, for each sex group, two distinct BP models were trained using: (1) only normal-labeled ECG records and (2) all records. This allowed us to investigate whether BP estimation performance differs when trained exclusively on normal ECGs versus both normal and abnormal cases. As a result, four distinct models were developed for each of SBP and DBP (male-normal/all and female-normal/all). See table 3 for the breakdown.
For training and validation, we used subject-level data splitting rather than record-level to avoid inter-subject data leakage between training and validation, ensuring that the results are generalizable to other datasets. Accordingly, all models were trained using leave-subject-out five-fold cross-validation. The preprocessed dataset (detailed in figure 1) was randomly split into five sets of subjects. In each fold, the model was trained on data from four sets and tested on the left-out set. In this cross validation scheme, each subject appeared only once in the test set and four times in the training set (i.e. in 4/5 folds). In terms of ECG-BP recording pairs, the subjects had varied numbers of recordings: over 26% of the subjects had only one pair; the median was six pairs per subject; and, in an extreme case, one subject had 3689 measurement pairs. To address this imbalance and reduce the risk of biasing the ML models toward subjects with more measurements, the number of ECG-BP pairs per subject was capped at six in the train and test datasets. For subjects with more than six recordings, six pairs were randomly selected during cross-validation to make the best use of the available data. For subjects having six or fewer ECG-BP pairs, the same pairs were used for training across all folds. Therefore, most of the 124 427 pairs of ECG-BP measurements listed in figure 1 eventually contributed to the training/testing procedure.
In each fold, the model predictions were stored and after completing all five folds for each model, the predictions from all folds were aggregated to calculate and report the performance metrics. The training and test sets used for training each fold were identical across all the studied regression/classification models to accomplish a fair comparison.
2.7. Evaluation metricsThe performance of the developed ML models was evaluated using various metrics, including mean error (ME), SD of ME, MAE, SD of MAE, and correlation coefficient, to enable comparison with other studies. Specifically, the correlation coefficient reflects the strength of the linear relationship between the estimated and actual BP values. The correlation coefficient can be either positive or negative, implying a direct or inverse relationship. The absolute correlation coefficient ranges from 0, indicating no linear relationship, to 1, indicating a perfect relationship (Martin Bland and Altman 1986).
3.1. ECG-based BP estimationTable 4 summarizes the performance of the ML models in estimating DBP and SBP using only ECGs, based on sex and ECG labels (across all and normal-only ECG records). The best results, based on the correlation coefficient metric, were achieved in estimating DBP with a value of 0.38 using CatBoost and normal-ECG records of males, and in estimating SBP with a value of 0.35 using RF and all-ECG records of females.
Table 4. Performance of regression models (random forest (RF), CatBoost, and light gradient boosting machine (LightGBM)) for estimating systolic (SBP) and diastolic (DBP) blood pressure using 30 s ECGs with a 280-feature set, split by ECG labels and subject sex. The models were trained and validated using leave-subject-out cross validation (compare and contrast with record-wise dataset partitioning in table 6). The number of records per subject was limited to a maximum of six (median of the number of ECG-BP pairs per subject) to avoid biasing results by over-representing individuals with more data.
DataSBP (mmHg)DBP (mmHg)LabelSex# Subjects# Test-recordsMAESTDMESTDρModelMAESTDMESTDρModelAllMale523620 10711.829.690.0315.290.29LightGBM7.626.240.049.850.37LightGBMAllFemale2176736412.5910.220.2516.210.35RF8.036.330.1910.230.38RFNormalMale498218 67811.649.490.3215.010.30RF7.436.080.039.600.38CatBoostNormalFemale20786868
Comments (0)