
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Remember me
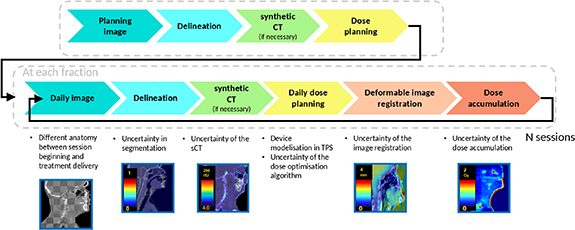
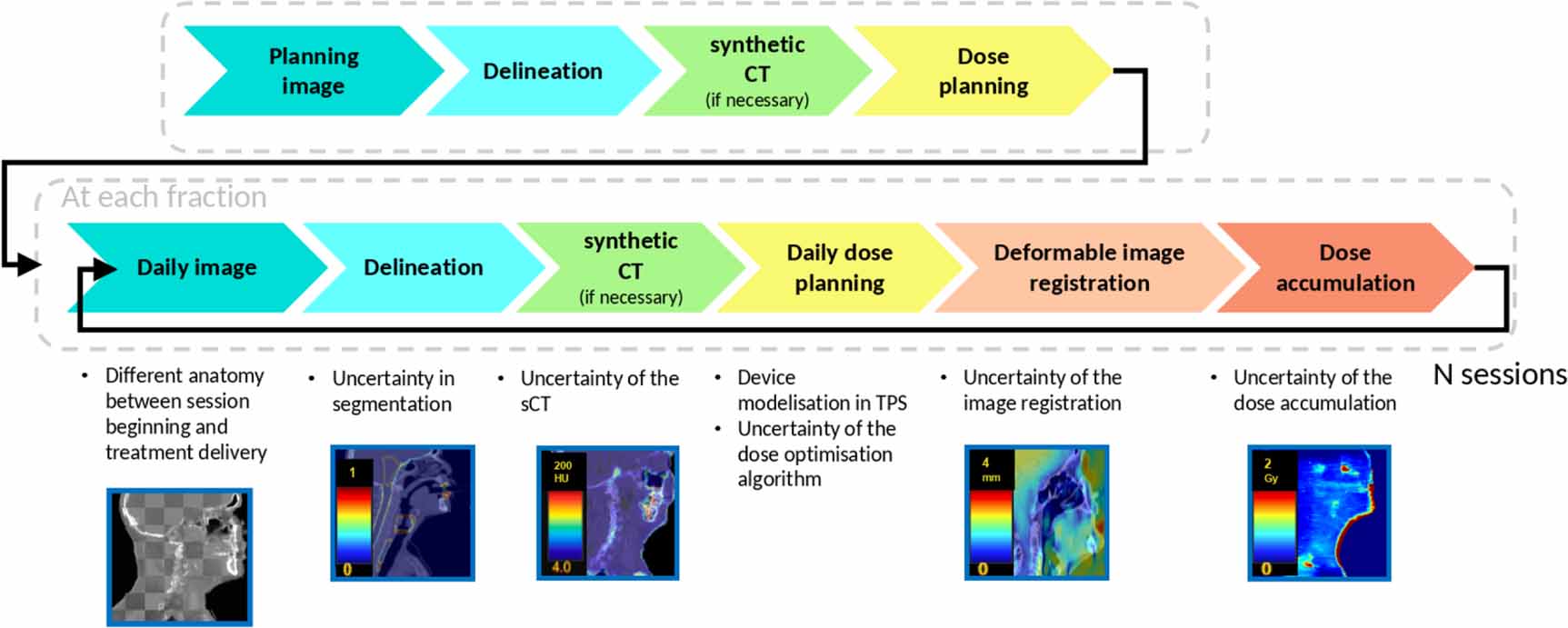
Radiotherapy (RT) extensively uses multimodal medical imaging at different steps of the workflow. The evolution of RT is towards a more precise treatment taking into account anatomical variations, called adaptive RT (ART), with the help of AI and automation tools (Dona Lemus et al 2024). Uncertainty quantification (UQ) (Claessens et al 2022, Huang et al 2024) has emerged as a pivotal topic for medical image processing, supporting quality assurance (QA) across critical tasks such as image synthesis, segmentation, dose prediction or image registration. Figure 1 illustrates the RT workflow, highlighting the interest of UQ at different steps. Deep learning-based segmentation is now widely adopted in clinical routine, however tools for UQ are still lacking (De Biase et al 2024, Gao et al 2025). Generation of synthetic CT (sCT) images from another imaging modality like magnetic resonance (MR) or cone beam CT (CBCT) images (Huijben et al 2024) is largely proposed for daily dose calculation (Spadea et al 2021, Altalib et al 2025) or MR-guided RT (Bahloul et al 2024, Texier et al 2024), but lacks uncertainty estimation. Dose accumulation is another uncertainty-prone step in RT, as it relies heavily on image registration (Chetty and Rosu-Bubulac 2019). Image registration aligns sequential images in a rigid or deformable manner (Zou et al 2022, Nenoff et al 2023, Chen et al 2025). Rigid image registration assumes only translational and rotational differences between scans, making it typically suitable for bone structure. However, deformable image registration (DIR) is necessary to capture spatially varying transformations like anatomical variations (Nenoff et al 2023, Boussot et al 2025). While DIR offers greater anatomical fidelity, it also introduces additional uncertainty due to its complexity and sensitivity to image quality and algorithmic assumptions.
Figure 1. Schematic representation of an online adaptive radiotherapy workflow and possible uncertainty quantification at each step. Key steps include image acquisition, segmentation, synthetic image generation (sCT), daily dose planning, deformable image registration, and dose accumulation. Each task introduces distinct sources of uncertainty that can impact clinical decision-making and propagate from one step to the next, illustrating the cumulative impact of segmentation through dose accumulation.
Download figure:
Standard image High-resolution imageIn this context, robust and accurate UQ enhances the reliability, safety, and clinical relevance of deep learning models across the RT workflow (Claessens et al 2022, Huang et al 2024). By offering insights into model confidence and identifying error-prone regions, UQ supports interpretability and promotes greater trust in AI-driven decision-making (Huang et al 2024). As such, UQ is increasingly viewed as essential for bridging the gap between algorithmic predictions and clinical practice in RT (Wahid et al 2024).
Uncertainty is broadly categorized into two types (Huang et al 2024): aleatoric uncertainty and epistemic uncertainty, each with distinct causes, implications, and management strategies. Aleatoric uncertainty arises from inherent variability or stochastic noise in the input data, regardless of its modality (e.g. images, clinical variables, or textual records). It reflects randomness in the data-generating process, such as acquisition noise, measurement errors, or inconsistencies in human annotation. In RT, this includes not only imaging artifacts and resolution limits but also inter-observer variability in manual delineations or contouring, which is typically considered an aleatoric source (Korreman and Ren 2025) of uncertainty because it reflects intrinsic variability in labeling rather than model ignorance.
Epistemic uncertainty arises from the model’s limitations, often due to insufficient or non-representative training data (Kendall and Gal 2017, Papernot and McDaniel 2018). This typically results from training datasets that lack sufficient diversity across clinical cases, imaging modalities, or protocols, leading to gaps in the model’s understanding. Another contributing factor is model bias, which can lead to overfitting or poor generalization to unseen data (i.e. data outside the training cohort), particularly when models are trained on single-center or imbalanced datasets.
Unlike aleatoric uncertainty, epistemic uncertainty is reducible through targeted interventions. Expanding datasets to include diverse and multicenter data, representing a wide range of patient demographics, imaging protocols, acquisition systems, and centers, can mitigate biases and improve generalizability. Additionally, employing advanced model architectures, such as transfer learning, domain adaptation, and ensemble methods, can address knowledge gaps and enhance the model’s robustness and reliability.
Quantifying epistemic uncertainty is essential to identify scenarios in which the model may be less reliable, such as underrepresented anatomical regions, unseen center in learning cohort or rare clinical cases.
Although aleatoric and epistemic uncertainties are conceptually distinct, they frequently coexist in practical applications. In practice, disentangling them is non-trivial, as both contribute simultaneously to the predictive variability (Tyralis and Papacharalampous 2024). Their separation typically depends on modeling assumptions, heteroscedastic likelihoods for aleatoric terms or Bayesian weight distributions for epistemic uncertainty, and is valuable because each type requires distinct mitigation strategies: epistemic uncertainty can be reduced through broader and more representative training data, while aleatoric uncertainty is constrained by measurement noise or intrinsic ambiguity in the acquired images
Several recent reviews have explored UQ techniques in medical imaging (Huang et al 2024, Wahid et al 2024). This study aims to review the recent literature by introducing a structured classification framework for UQ methods, categorizing them based on their applicability to RT tasks such as segmentation, registration, sCT generation, dose prediction, and dose accumulation. It also synthesizes recent advances in deep learning architectures, emerging hybrid approaches, and novel applications within RT. By addressing these critical areas, this review provides a comprehensive and clinically relevant overview that bridges the gap between methodological innovation and practical implementation in uncertainty-aware RT.
A comprehensive literature search was conducted in PubMed and Google Scholar to identify relevant studies published between January 2020 and June 2025. The selection process focused on research articles related to UQ in RT, using the following keywords: ‘uncertainty’, ‘radiotherapy’, and either ‘segmentation’, ‘registration’, ‘synthetic image generation’, ‘image-to-image translation’, ‘dose prediction’, or ‘dose accumulation’. Studies were included if they contributed to methodological advancements, clinical applications, or emerging trends in uncertainty-aware RT. The review prioritizes peer-reviewed articles presenting novel deep-learning approaches, hybrid techniques that integrate multiple uncertainty estimation strategies, and innovative frameworks that enhance the accuracy and reliability of RT processes. Additionally, studies exploring the integration of UQ into ART workflows were considered. The final selection aims to provide a comprehensive and up-to-date overview of the state-of-the-art methodologies and their clinical relevance in addressing uncertainties in RT.
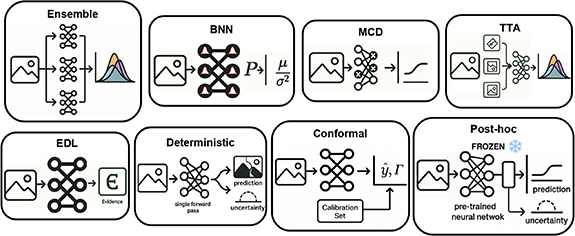
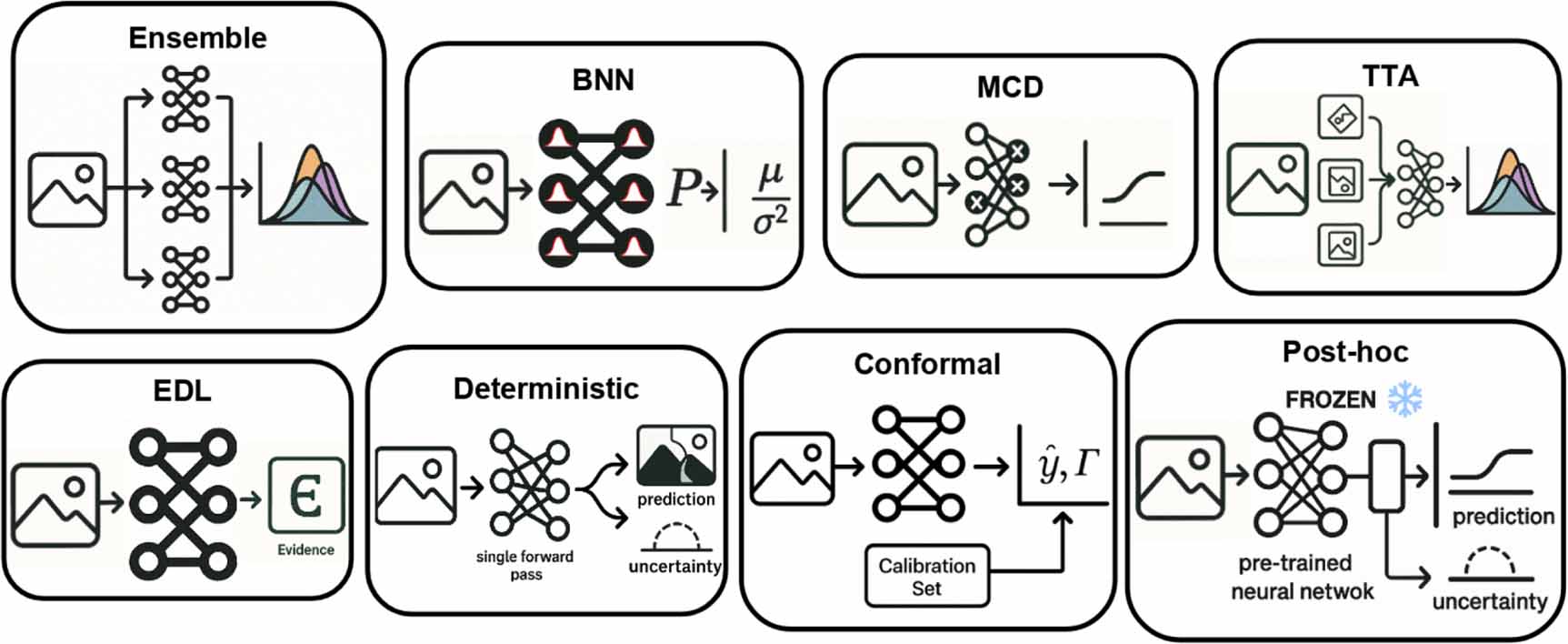
A range of techniques has been developed to quantify uncertainty in deep learning models (Wahid et al 2024). Figure 2 presents the main UQ methods. Table 1 summarizes the main UQ methods, specifying the type of uncertainty estimated, along with their principal advantages and limitations. In this review, we distinguish between aleatoric uncertainty, epistemic uncertainty, and predictive uncertainty (Tyralis and Papacharalampous 2024), which represents the total combined uncertainty when both components are jointly estimated, without being explicitly separated or disentangled.
Figure 2. Schematic illustration of the main uncertainty quantification (UQ) methods in deep learning. Each diagram represents a simplified flow from input to output, highlighting the structural differences between ensemble, Bayesian neural networks (BNN), Monte Carlo dropout (MCD), test-time augmentation (TTA), evidential deep learning (EDL), deterministic, conformal prediction, and post-hoc approaches. The consistent visual format highlights the comparative nature of these strategies across different UQ paradigms.
Download figure:
Standard image High-resolution imageTable 1. Overview of uncertainty quantification (UQ) methods including advantages and limitations.
UQ MethodUncertainty TypeAdvantagesLimitationsBayesian Neural Networks (BNN)Aleatoric & Epistemic Principled probabilistic modeling
Principled probabilistic modeling Computationally intensive
Computationally intensive  Complex training and tuning
Complex training and tuning  Sensitive to prior and approximationMonte Carlo Dropout (MCD)Epistemic
Sensitive to prior and approximationMonte Carlo Dropout (MCD)Epistemic Easy to implement in existing models
Easy to implement in existing models Multiple forward passes required
Multiple forward passes required  No retraining required
No retraining required May yield uncalibrated estimates
May yield uncalibrated estimates  Increased inference timeEnsemble MethodsEpistemic
Increased inference timeEnsemble MethodsEpistemic Robust and accurate uncertainty
Robust and accurate uncertainty High training and storage costs
High training and storage costs  Robust to overfitting
Robust to overfitting Slow inference due to multiple modelsTest-Time Augmentation (TTA)Aleatoric
Slow inference due to multiple modelsTest-Time Augmentation (TTA)Aleatoric Enhances robustness to noise/artifacts
Enhances robustness to noise/artifacts Does not explicitly model uncertainty
Does not explicitly model uncertainty  No changes to model architecture
No changes to model architecture Task-dependent effectiveness
Task-dependent effectiveness  Increased inference timeEvidential Deep Learning (EDL)Predictive
Increased inference timeEvidential Deep Learning (EDL)Predictive Efficient inference (single pass)
Efficient inference (single pass) Needs careful regularization
Needs careful regularization  May overestimate confidencePost-hoc/Auxiliary NetworksTypically Epistemic
May overestimate confidencePost-hoc/Auxiliary NetworksTypically Epistemic Works with pretrained models
Works with pretrained models Dependent on auxiliary network quality
Dependent on auxiliary network quality  Modular and low overhead
Modular and low overhead Limited generalizability across datasetsConformal PredictionPredictive
Limited generalizability across datasetsConformal PredictionPredictive Model-agnostic, theoretical guarantees
Model-agnostic, theoretical guarantees May yield wide prediction intervals
May yield wide prediction intervals  Minimal distributional assumptions
Minimal distributional assumptions Calibration set must be representativeDeterministicAleatoric (primarily)
Calibration set must be representativeDeterministicAleatoric (primarily) Single-pass inference (fast)
Single-pass inference (fast) May underestimate epistemic errors
May underestimate epistemic errors  Captures spatially varying data noise
Captures spatially varying data noise Often needs calibration for interpretabilityHybridAleatoric & Epistemic
Often needs calibration for interpretabilityHybridAleatoric & Epistemic Combines complementary paradigms
Combines complementary paradigms Increased implementation complexity
Increased implementation complexity  Improved robustness and calibration
Improved robustness and calibration May require multiple training objectives3.1. Bayesian methods
May require multiple training objectives3.1. Bayesian methodsBayesian methods (Goan and Fookes 2020) treat model parameters, θ, as random variables with prior distributions. The posterior distribution, 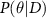 , is derived using the Bayes theorem (equation (1)):
, is derived using the Bayes theorem (equation (1)):

where 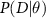 is the likelihood,
is the likelihood, 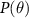 is the prior, and P(D) is the evidence.
is the prior, and P(D) is the evidence.
Since exact Bayesian inference is computationally intractable for neural networks, approximations like Bayesian neural networks (BNNs) and variational inference are commonly used (Mukhoti et al 2020, Seligmann et al 2023, Wang et al 2023, Li et al 2024). BNNs introduce distributions over the network weights, allowing the model to output uncertainty as well as predictions. Variational inference optimizes an approximate posterior 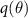 to minimize the Kullback–Leibler (KL) divergence with the true posterior according to the following equation:
to minimize the Kullback–Leibler (KL) divergence with the true posterior according to the following equation:
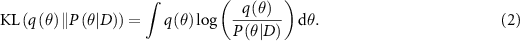 3.2. Sampling and dropout-based methods
3.2. Sampling and dropout-based methodsSampling and dropout-based methods introduce stochasticity into deterministic models to estimate uncertainty by performing multiple forward passes during inference. These methods leverage the variability in predictions across these passes to quantify epistemic uncertainty.
Monte Carlo dropout (MCD). MCD (Gal and Ghahramani 2016) applies dropout not only during training but also during inference to simulate stochastic behavior. Multiple forward passes are performed, each with a different subset of neurons randomly frozen, allowing the model to produce a distribution of predictions. The uncertainty can be quantified from the distribution of stochastic predictions, commonly through their variance:
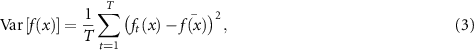
where T is the number of stochastic passes, 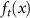 is the prediction at pass t, and
is the prediction at pass t, and 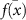 is the mean prediction across all passes. However, several other metrics can also be employed to quantify uncertainty (see 4 for further details).
is the mean prediction across all passes. However, several other metrics can also be employed to quantify uncertainty (see 4 for further details).
General sampling-based methods. Other sampling-based approaches extend this idea by introducing randomness in different parts of the model (Ayhan and Berens 2018, Zhao et al 2022, Franchi et al 2024), such as weight perturbations or latent variable sampling.
These techniques include latent space sampling, where uncertainty is estimated by generating multiple outputs through sampling in models such as VAEs and perturbation-based sampling, which involves adding random noise to the input or intermediate layers during inference to produce diverse predictions.
3.3. Ensemble methodsEnsemble methods (ENS) can involve multiple distinct models or a deep ensemble of the same model trained with different initializations, hyperparameters, or data subsets (Rahaman et al 2021, Balabanov et al 2023, Ramé et al 2023a, Kim et al 2024a). The predictions can be aggregated, and the uncertainty can be estimated based on the variance of the predictions, according to the following equation:
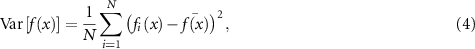
where N is the number of models in the ensemble, 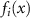 is the prediction from the ith model, and
is the prediction from the ith model, and 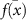 is the mean prediction. However, several other metrics can also be employed to quantify uncertainty (see section 4 for further details).
is the mean prediction. However, several other metrics can also be employed to quantify uncertainty (see section 4 for further details).
Data augmentation (Shorten and Khoshgoftaar 2019) is a widely used technique to enhance model robustness by artificially increasing the diversity of the training dataset. This is achieved through transformations such as rotations, scaling, noise addition, cropping, flipping, and contrast adjustments. While traditionally employed during training, these transformations can also be applied during inference, an approach known as TTA. In this setting, multiple augmented versions of the input are generated and passed through the model, producing a set of predictions. The variability among these predictions serves as an empirical estimate of uncertainty.
Beyond basic transformations, advanced data augmentation techniques further enhance model generalization and robustness (Mixup (Thulasidasan et al 2019, Pinto et al 2022), Outlier Sample Generation (Wang et al 2023, Zhu et al 2023), Domain-Specific Augmentation (Hariat et al 2024)).
By simulating perturbations common in clinical imaging, such as motion artifacts or contrast variation, TTA provides a practical means to estimate uncertainty and identify predictions that may require clinical attention.
3.5. Evidential deep learning (EDL)EDL is an efficient UQ method (Zhao et al 2019, Amini et al 2020, Yu et al 2024) that predicts both the mean and variance of a distribution in a single forward pass. This approach models uncertainty as evidence, leveraging a probabilistic framework to capture both aleatoric and epistemic uncertainties.
In classification tasks, EDL often utilizes a Dirichlet distribution (Yu et al 2024) parameterized by evidence scores ![$ \boldsymbol = [\alpha_1, \alpha_2, , \alpha_K] $](https://content.cld.iop.org/journals/0031-9155/71/1/01TR01/revision2/pmbae2a9fieqn46.gif) , where K is the number of classes. The expected class probabilities are computed as:
, where K is the number of classes. The expected class probabilities are computed as:
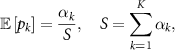
where S is the total evidence, representing the model’s confidence in its predictions. Higher S corresponds to lower epistemic uncertainty, while lower S indicates higher uncertainty.
The loss function for EDL typically includes a regularization term to discourage overconfident predictions with low evidence:
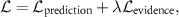
where 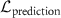 ensures accurate predictions (such as Negative Log Likelihood), and
ensures accurate predictions (such as Negative Log Likelihood), and 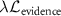 penalizes uncertainty estimates when evidence is insufficient.
penalizes uncertainty estimates when evidence is insufficient.
Post-hoc methods involve estimating uncertainty after the primary model has been trained, often using a secondary model or calibration techniques. These methods do not require modifications to the original training process, making them particularly useful for leveraging pretrained models.
Auxiliary networks (Besnier et al 2021, Ganaie et al 2022, Shen et al 2023) are secondary models trained to predict the uncertainty of the primary model’s outputs. These networks take the primary model’s predictions or intermediate representations as input and output uncertainty estimates.
3.7. Conformal predictionConformal prediction is a framework for quantifying uncertainty by providing prediction intervals that provide formal guarantees on coverage probabilities (Tibshirani et al 2019, Angelopoulos et al 2020, Bates et al 2023). Conformal prediction makes minimal assumptions about the underlying data distribution, making it widely applicable across different tasks and model architectures.
The key idea behind conformal prediction is to compute prediction intervals (for regression) or prediction sets (for classification) that contain the true label or value with a user-defined confidence level 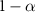 , where α is the tolerated error rate. This is achieved by calibrating the model’s predictions on a calibration set and constructing intervals that reflect the model’s uncertainty.
, where α is the tolerated error rate. This is achieved by calibrating the model’s predictions on a calibration set and constructing intervals that reflect the model’s uncertainty.
For regression tasks, the prediction interval Γ ![$ [\hat_}, \hat_}] $](https://content.cld.iop.org/journals/0031-9155/71/1/01TR01/revision2/pmbae2a9fieqn50.gif) is computed such that:
is computed such that:
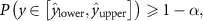
where y is the true target value.
For classification, conformal prediction generates prediction sets  , which include one or more classes that collectively meet the required confidence level:
, which include one or more classes that collectively meet the required confidence level:
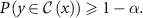 3.8. Deterministic methods
3.8. Deterministic methodsDeterministic UQ approaches (Durasov et al 2022, Charpentier et al 2023, Mukhoti et al 2023) aim to estimate uncertainty directly within a single forward pass, without the need for stochastic sampling or multiple model instances. These methods generally extend the model architecture, training and post-training scheme, or the loss function to learn an uncertainty map alongside the main prediction.
A common strategy is the use of heteroscedastic loss, which allows the model to predict both a mean and a variance for each voxel or pixel. This variance represents the aleatoric uncertainty and is learned jointly with the main task objective. The model thus captures spatially varying noise and ambiguity inherent in the imaging data (Kendall and Gal 2017, Bragman et al 2018).
3.9. Hybrid methodsHybrid methods combine elements from multiple UQ paradigms, such as Bayesian inference, ensemble diversity, or deterministic uncertainty modeling, to achieve more comprehensive and reliable uncertainty estimates. These approaches often aim to capture both aleatoric and epistemic components or to leverage uncertainty signals to guide model training and adaptation.
A representative example is the uncertainty-aware mean teacher (UAMT) framework (Zhang et al 2021, Wang et al 2024), which integrates Bayesian uncertainty estimation. In UAMT, the teacher network provides pseudo-labels to the student model, while voxel-level uncertainty, typically computed via MCD, modulates the consistency loss.
Beyond UAMT, hybrid UQ strategies include architectures that fuse evidential and Bayesian formulations, combine deterministic and stochastic inference, or integrate uncertainty-aware modules into self-supervised or domain adaptation frameworks.
Beyond numerical quantification, recent studies highlight the need to identify the causes of uncertainty (Seoni et al 2023) in order to strengthen confidence in clinical AI systems. Causal inference frameworks (Jiao et al 2024) could help disentangle the contributions of imaging noise, interobserver variability, and model bias to overall uncertainty. By replacing correlation-based models with stable and interpretable causal models, these methods make it possible to distinguish genuine causal factors from spuriously correlated variables. This enables a decomposition of error sources and can support targeted mitigation strategies for uncertainty, thereby improving the interpretability and intrinsic robustness of AI systems in radiation therapy, a field that demands low tolerance for error.
In section 5, we will explore how these methods are applied to various tasks in medical image analysis, drawing upon insights from two comprehensive reviews (Huang et al 2024, Wahid et al 2024) to provide an in-depth exploration of their practical utility and growing significance in modern clinical workflows.
Accurate and reliable assessment of uncertainty is essential for ensuring the robustness and clinical trustworthiness of AI-driven models in RT workflows. A wide range of quantitative metrics has been proposed to evaluate how well uncertainty estimates reflect both prediction accuracy and model confidence across different imaging tasks. Table 2 summarizes the main categories of evaluation methods and their associated metrics, as detailed in appendix. These include coverage metrics, predictive entropy, calibration metrics, and scoring functions. Additional measures, including ROC-AUC for misclassification and out-of-distribution (OOD) detection and qualitative visual assessment by clinicians, provide complementary insight into the interpretability and clinical relevance of uncertainty estimates.
Table 2. Main evaluation methods for uncertainty quantification in radiotherapy, and examples of associated metrics/tools. abbreviations : OOD : out-of-distribution.
Evaluation MethodDescriptionMetrics/ToolsCoverage MetricsMeasure the proportion of true outcomes within predicted uncertainty intervals or compute sample variance across predictions (Kuleshov et al 2018, Laves et al 2020, Balderas et al 2024, Huet-Dastarac et al 2024, Mossina et al 2024).Coverage probability, variance, prediction intervals.Predictive EntropyQuantify total predictive uncertainty using the entropy or dispersion of the probability distribution of the model output (Dai and Tian 2013, Mehrtash et al 2020, Hamedani-KarAzmoudehFar et al 2023, Mehta et al 2024).Shannon entropy, voxel-wise entropy mapsCalibration MetricsAssess the alignment between predicted confidence and observed (Laves et al 2020, Mehrtash et al 2020, Mukhoti et al 2021).Expected Calibration Error, Thresholded ECE, Uncertainty Calibration Error (Guo et al 2017, Minderer et al 2021)Scoring Functions
Comments (0)