
Remember me
Participants are adults aged between 18 and 67 years recruited to the Australian Epilepsy Project [AEP; epilepsyproject.org.au; 8]. The AEP recruits individuals with drug-resistant focal epilepsy (DRE), with newly diagnosed epilepsy (< 6 months; NDE), or with a first unprovoked seizure (FUS), as well as healthy volunteers. All participants are required to have a functional level of English; exclusion criteria are a moderate or severe intellectual disability and/or contraindications for 3 T MRI. Additionally, healthy volunteers cannot have a history of seizures or epilepsy, a history of other neurological conditions (e.g., acquired brain injury, neurodegenerative disorder), and/or an active severe or progressive illness. Individuals with a history of seizures (DRE, NDE, and FUS) were referred by neurologists in private or public health services across Australia. Healthy volunteers were recruited via word of mouth, advertisements and social media.
The main analyses compared TENT cognitive scores in the DRE (n = 452) and healthy volunteer groups (n = 531; Figs. 2 and 3A, B). Secondarily, we examined the sensitivity of certain TENT measures to antiseizure medications (ASMs), age, unilateral structural damage, and age of epilepsy onset; and examined convergent validity by comparing TENT scores to scores on traditional in-person measures (see below; Fig. 3C, D and Table 3). To achieve these secondary aims, we incorporated additional data from people newly diagnosed with seizures (NDE = 287; FUS = 105).
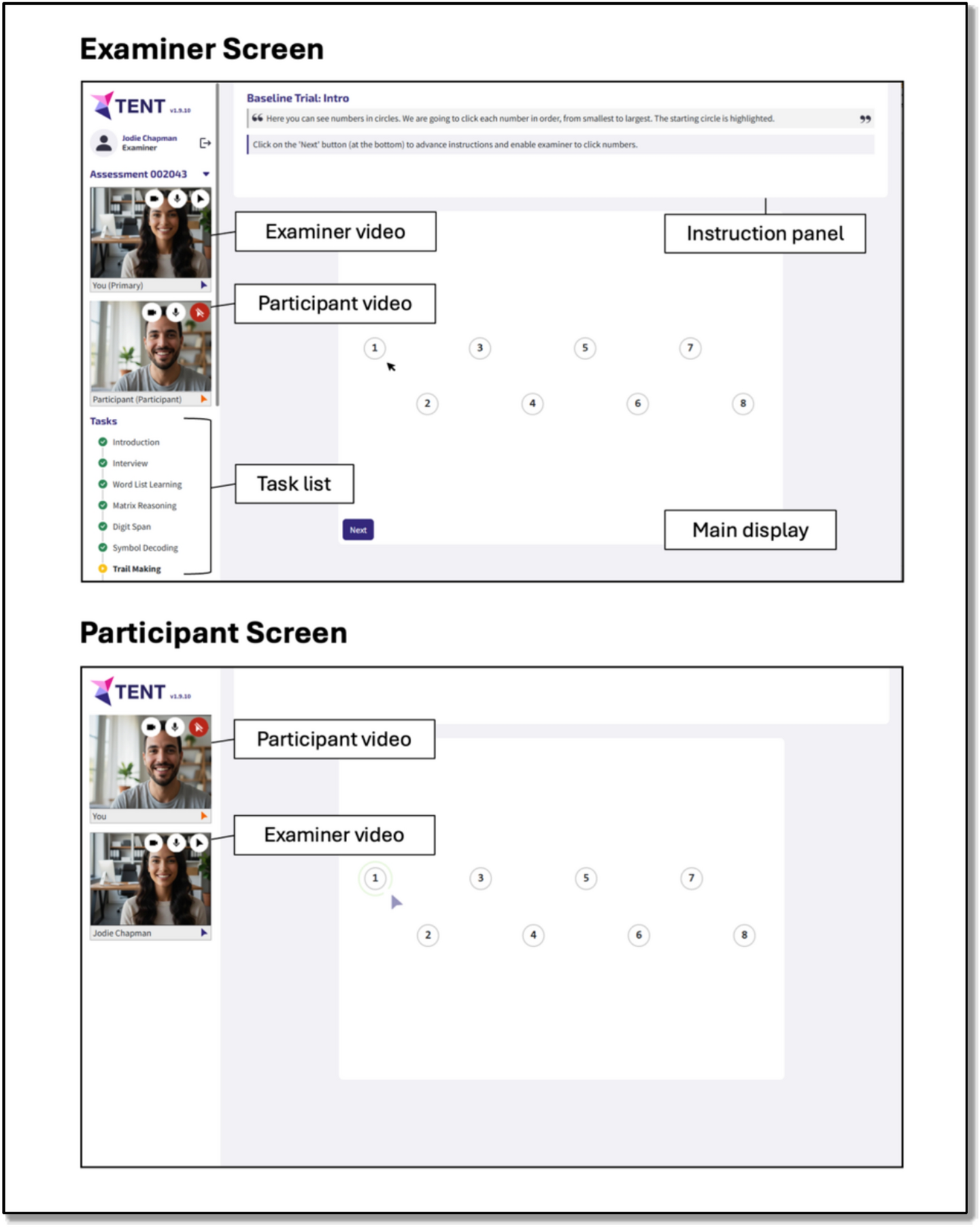
Software design and implementationTENT is custom-built videoconference-integrated browser-based software, compatible with a camera and microphone enabled desktop/laptop (with a connected mouse), or tablet device with a connected mouse/keyboard. The cognitive tasks described below are administered via the software, and responses are recorded therein. The layout is illustrated in Fig. 1. Video feeds of the participant and examiner are visible to both parties throughout the entire session as tiles at the left of their screens. The participant additionally sees the examiner’s video feed on the main display when the task allows (i.e., when no stimulus material is displayed).
Fig. 1
Basic layout of the TENT software, showing examiner screen (top) and participant screen (bottom)
Examiner and participant screens differ. The examiner screen shows:
(1)On the left, an ordered task list, including the status of each task (i.e., completed, in progress, yet to commence). In the AEP, tasks are administered in a predefined order, but it is possible to navigate through the tasks flexibly if required, including omitting tasks where necessary (e.g., participant refusal).
(2)At the top, explicit task instructions. These include instructions the examiner is to read aloud verbatim to the participant and prompts for the examiner that facilitate task administration and scoring.
(3)On the main display, a real-time mirror of the participant’s screen and cursor to facilitate observation of task performance, and/or response buttons and text fields that the examiner can use to record participant responses.
The participant main display shows either a full screen video feed of the examiner or task stimuli. Depending on the task, participants respond either via mouse clicks or their keyboard or verbally with their responses recorded by the examiner via the examiner interface. Sessions were not audio/video recorded (though this could readily be achieved with appropriate ethics approval and participant consent).
TENT includes a screenshare feature, enabling the administration of cognitive tasks not built into the software.
MeasuresTENT tasks were selected and adapted from measures with an existing evidence base in the neuropsychological literature broadly, measures with demonstrated utility across the different stages of adult epilepsy (e.g., new onset and chronic), recommendations from international epilepsy organizations (e.g., NINDS Common Data Elements for Epilepsy [9]; EpiCARE European Reference Network [10], International League Against Epilepsy [11]), and to ensure coverage across cognitive domains commonly affected in epilepsy. Tasks were adapted or developed de novo for administration via TENT, drawing upon key principles and attributes underpinning conventional in-person materials with demonstrated utility. A summary of each task is provided in Table 1 (with more detail available in Supplementary Information).
Table 1 Cognitive tasks implemented in the TENT software (alphabetical) Additional cognitive tasks delivered via screen shareIntelligence was measured using the full-scale IQ (FSIQ-2) index from the Wechsler Abbreviated Scale of Intelligence Second Edition (WASI-II) [12], calculated from scores on the Vocabulary and Matrix Reasoning subtests. These measures were administered using the screenshare feature within the TENT software, with stimuli accessed via Q-Global, and responses recorded manually.
ProcedureThis research was completed in accordance with the Helsinki Declaration. Ethics approval for the AEP was granted by Austin Health Human Research Ethics Committee (HREC/68372/Austin-2022). Participants provided their informed consent prior to participation. Demographic and clinical data were obtained during eligibility screening, from the participants’ treating clinician, and/or from a medical history interview conducted as part of the AEP.
Trained research assistants conducted the cognitive testing sessions. Research assistants were either individuals with postgraduate training in clinical neuropsychology, or individuals with undergraduate training in psychology or experience working in clinical trials. Training involved (sequentially): (1) observation of a training examiner conducting a session, (2) a general introduction to TENT, including the rationale and methods underlying each task and a Standard Operating Procedures manual, (3) internal practice (mock) assessment(s) of colleagues, (4) an observed mock assessment(s), (5) an observed assessment(s) with a healthy volunteer, and (6) an observed assessment(s) with a participant with epilepsy, ultimately used to assess readiness to undertake independent data collection. Trained examiners are reobserved yearly to ensure compliance with standardized assessment procedures.
Participants completed assessment sessions either at home on their own device (n = 1282, 93.2%), or at a research site on a provided device while the research assistant conducted the session in a separate room (n = 93, 6.8%). The latter was the case when participants did not have an appropriate device or internet connection, or for other reasons were unable to complete the session at home. The TENT software automatically captured details of the participants’ browser (name, version, window size), operating system (name, version), and monitor resolution. In each session, the research assistant went through a checklist with participants to ensure the environment in which they were conducting the session was appropriate. This included, for example, ensuring they were alone in a private, distraction-free environment, that computer notifications were turned off, and confirming their location, phone number, and emergency contacts in the event of a seizure. For all neuropsychological measures, the administering research assistant characterized the completion of the test as ‘complete and reliable’, or impacted by other factors (e.g., distraction, refusal). Only data marked as ‘complete and reliable’ were included in analyses. During each task the examiner was also able to type in comments, embedded in the electronic data file, to facilitate the later interpretation of performances.
Follow-up online surveys about the participants’ experience using the TENT software were collected in a subset of participants (n = 262 healthy volunteers, 251 DRE, 165 NDE and 63 FUS), as these were introduced later during data collection. Specifically, participants were asked, “How would you rate the online neuropsychology experience, between 1 and 5?” on a scale from 1 (Did not enjoy) to (Excellent). A free text field was also available for qualitative feedback.
Assessment of convergent validityA subset of participants also underwent in-person clinical neuropsychological assessment as part of their routine clinical care. For these participants, we were able to compare performances (where available, and without a neurosurgical procedure occurring between assessments) on standard cognitive tasks administered during these clinical assessments with TENT measures assaying similar cognitive constructs (i.e., convergent validity). Specifically, we compared: scores on TENT Word List Learning and Word List Delay with scores on a clinically acquired Rey Auditory Verbal Learning Task (RAVLT; [13, 14]; median interval between tests = 80.5 days; IQR = 174.8 days; AEP preceded clinical in 41 of 86 cases); scores on TENT Figural Learning with delayed (10 + min) recall scores on the Rey Complex Figure Test (RCF) [15]; median interval between tests = 73 days; IQR = 192.5 days; AEP preceded clinical in 24 of 43 cases); and scores on TENT Confrontation Naming with scores on the Boston Naming Test (BNT) [16]; median interval between tests = 76.5 days; IQR = 137.8 days; AEP preceded clinical in 24 of 40 cases). We have also reported elsewhere on the convergent validity of scores on the Symbol Decoding and Trail Making tasks relative to their traditional pen-and-paper in-person formats [17]. Convergent validity of reaction time tasks was assessed by comparing reaction times on the Spatial n-Back task in TENT to the reaction times on the same measure during the subsequent AEP MRI scan (as measured via a Cedrus high temporal precision button box; median interval between tests = 9 days; IQR = 13.8 days).
Statistical analysesRaw scores on metrics derived from TENT tasks were converted to z-scores by fitting a series of Bayesian hierarchical regression models (to be described in detail elsewhere). In brief, for each test metric, all AEP participants’ (those with a history of seizures and healthy volunteers) raw scores were fit simultaneously in a single model that estimated the overall effects of age (in years), level of education (in years), and assigned sex (categorical), plus group specific (categorical: history of seizures, healthy volunteer) deviances from these overall effects, separate intercepts for group (history of seizures, healthy volunteer), and an offset for English not as a primary language status, where indicated (categorical: English first language, English not first language). For each test metric, underlying empirical data distributions were fit using (truncated) Gaussian, Gamma, or negative Binomial distributions as appropriate.
The hierarchical Bayesian regression model for each test metric was fit using partial pooling (i.e., the parameter estimates for the seizure history and healthy volunteer samples were informed and constrained by one another). We used python version 3.12 and the Bayesian modeling framework pymc. From these models, an individual’s raw score can be expressed as a z-score capturing its deviation from the model predicted score for any of the observed groups. Thus, models effectively express each raw score as a standardized deviation from a predicted score based on (adjusted for) age, assigned sex, level of education, English not as a primary language status, and group membership. In the following, we report all scores as z-scores relative to the healthy volunteer group.
Further downstream analyses were conducted in R version 4.4.2 within R Studio version 2024.12.1 + 563. The criterion validity of TENT measures was assessed by comparing z-scores in the DRE group with healthy volunteers, and by evaluating whether demographic or clinical factors (e.g., age, ASM load) affected performance, each done by using boxplots and scatterplots for visualization. Sensitivity to the laterality of mesial temporal lesions was assessed by comparing, via MANOVA, memory and naming measures (Word List Learning, Word List Delay, Figural Learning, Confrontation Naming) in patients with either unilateral hippocampal sclerosis (HS) or prior anterior temporal lobectomy (ATL). Sensitivity to worse cognitive outcomes in those with earlier epilepsy onset was evaluated by running a principal components analysis (PCA) on the metrics derived from the TENT-integrated tasks (excluding WASI-II measures) and correlating scores on the first principal component against age at seizure onset. Convergent validity was assessed by calculating the Pearson correlation between TENT scores and scores obtained during in-person assessments. The convergent validity of reaction times were assessed by calculating the intra-class correlation coefficient (ICC) between (log transformed) TENT derived reaction times and Cedrus response box derived reaction times. ICCs were estimated using the ICC function from the “psych” package version 2.5.3 (type = ICC3, a two-way mixed effects model assessing for consistency [18]). To evaluate the usability of TENT, comparison of participant scores obtained from assessments administered by different groups of examiners (those with and without postgraduate neuropsychology training) were compared using Bayesian t-tests, with Bayes factors (obtained via the BayesFactor package, version 0.9.12.4.7, in R) used to evaluate evidence in favor of the null hypothesis of no difference between examiners, and Bayesian equivalence tests [using the ttestBF function in the BayesFactor package and specifying nullInterval = c(− 0.1,0.1)] to evaluate evidence that any observed differences between examiner groups fell in the range −0.1 to 0.1. We also evaluated the rates of valid data on TENT Tasks. Acceptability was evaluated by looking at the quality ratings and participant qualitative feedback.
Comments (0)