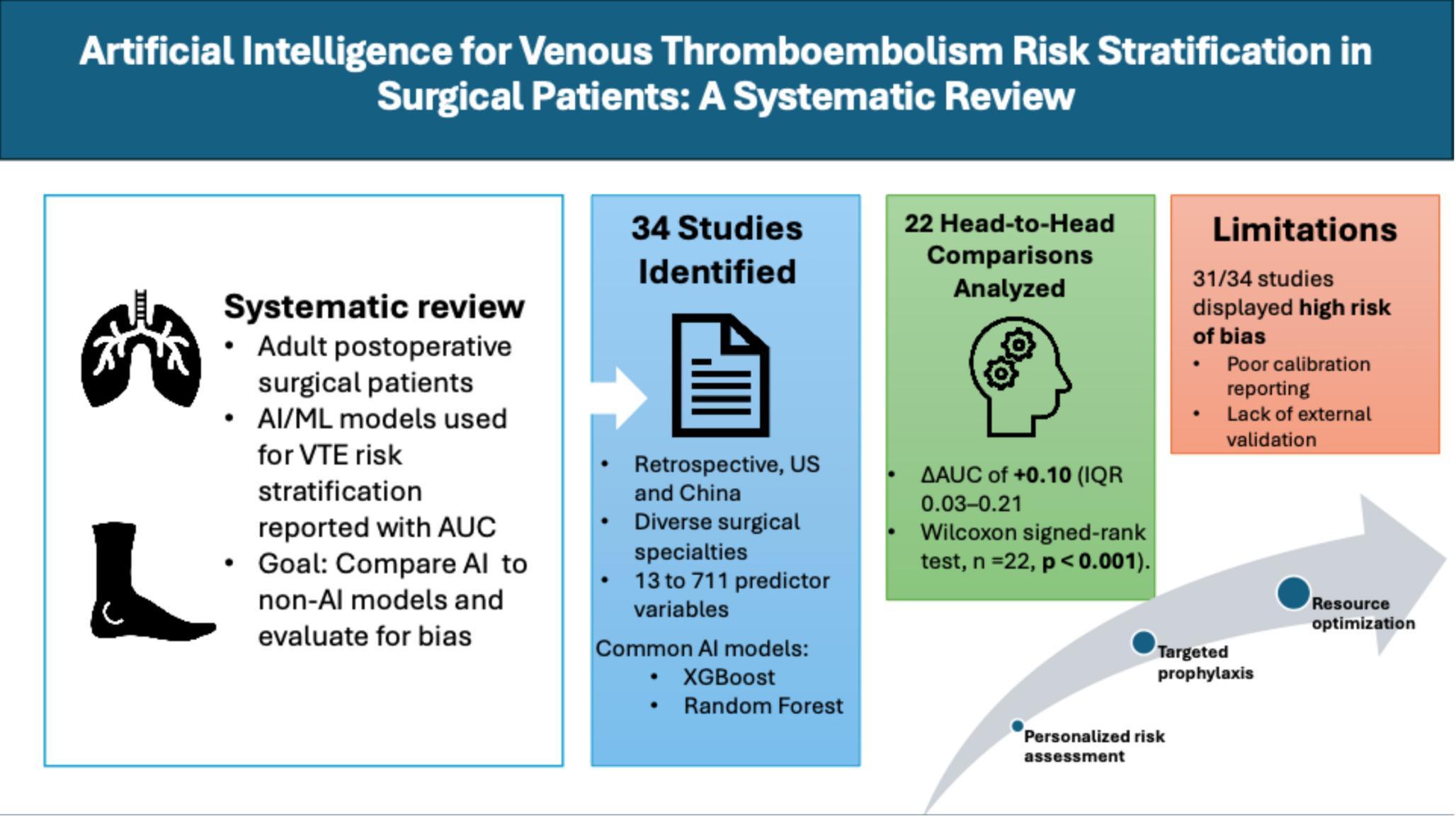
We identified 34 studies evaluating the use of AI models to stratify VTE risk in postoperative surgical patients. Interest in this topic increased over the study period, with two-thirds of the included studies published in the last three years. Twenty-two of the included studies compared AI models to non-AI models; however, these comparators were predominantly internally developed statistical models, such as logistic regression, with only three direct comparisons to validated risk assessment models. Our study displayed that, of the 22 head-to-head comparisons within the patient cohorts, AI-based models demonstrated consistently higher discrimination than non-AI models, as reflected by a positive median difference in AUC (Median ΔAUC of + 0.10, (IQR 0.03–0.21)) and a statistically significant Wilcoxon signed-rank test (n = 22, p < 0.001). A paired, nonparametric statistical approach was necessary given the bounded nature of AUC values, the limited number of head-to-head comparisons, and the heterogeneity of the included studies. By focusing on within-study differences and evaluating median effects, the Wilcoxon signed-rank test provides a conservative assessment of discrimination performance without assuming normality or cross-study comparability.
While AI models demonstrated improved discrimination, certain non-AI models also achieved strong predictive performance, notably the Logistic Regression model in Zhang et al. [18], with an AUC of 0.992, suggesting that well-designed non-AI tools may remain valuable in particular clinical contexts. A common theme throughout the evaluated studies was that AI-informed VTE risk stratification may improve predictive accuracy and enable more personalized perioperative VTE prophylaxis for high-risk patients. Although this review focused on surgical patients, prior systematic reviews have examined AI and ML applications for VTE risk prediction in non-surgical and general hospitalized populations. Wang et al. [26] conducted a meta-analysis of 12 studies across diverse patient cohorts, finding a pooled AUC of 0.98 for AI models. Similarly, Chiasakul et al. performed a systematic review and pooled analysis of 20 studies in hospitalized patients, finding that AI models consistently outperformed conventional risk assessment tools for VTE prediction. The mean AUC for AI versus conventional methods was 0.79 (95% CI: 0.74–0.85) versus 0.61 (95% CI: 0.54–0.68), respectively (p < 0.001) [10]. Our findings align with the existing literature and reinforce the expanding utility of AI and ML for VTE risk stratification across diverse patient populations in both surgical and non-surgical settings.
While our findings indicate that AI-based approaches outperform non-AI comparators within the same cohort, they must be evaluated in the context of several limitations. In this review, logistic regression models were categorized as non-AI statistical comparators. While logistic regression can be broadly considered a supervised learning method from a computational perspective, it is not an established clinical risk assessment tool designed for bedside use. Direct comparisons between AI-based models and validated clinical risk scores, including the Caprini score, were unavailable in most included studies. This substantially limits conclusions about the clinical superiority of AI-based models over established bedside risk assessment tools, which are specifically designed to guide perioperative VTE risk stratification and thromboprophylaxis decision-making. Furthermore, most logistic regression models used as non-AI comparators were newly developed and internally evaluated within their respective studies rather than representing externally validated clinical prediction models. As such, observed performance differences should be interpreted as study-specific benchmarking against internally derived statistical models rather than definitive evidence of superiority over validated clinical risk assessment instruments.
Although AI models demonstrated improved discrimination compared with non-AI models in the evaluated studies, judging clinical readiness based on discrimination alone is insufficient, as superior discrimination does not guarantee accurate risk estimation. Many studies emphasized discrimination metrics, such as AUC, without consistently reporting sensitivity and specificity at clinically meaningful thresholds, thereby limiting insight into trade-offs between false negatives and false positives. Because prophylaxis decisions require balancing missed VTE events against bleeding risk, the absence of threshold-based performance metrics constrains the clinical interpretability of these models.
Of the 34 included studies, only 12 (35.3%) reported calibration metrics, further limiting real-world applicability. Calibration contextualizes discrimination by assessing whether predicted probabilities correspond to observed event rates and can be meaningfully applied to threshold-based clinical decision-making. These models must not only identify higher-risk patients but also assign accurate absolute risk estimates. Without calibration, a model may correctly rank patients by relative risk while systematically over- or underestimating absolute risk, potentially leading to inappropriate prophylaxis decisions.
In addition, the absence of external validation in many AI models is concerning, as it increases the risk of overfitting and limits generalizability. Accordingly, the near-perfect discrimination reported by models such as those by Zhang et al. [18] (AUC = 1.000), Ding et al. [27] (AUC = 0.982), and Wei et al. [17] (AUC = 0.979) should be interpreted with caution. Findings of near-perfect discrimination in retrospective clinical datasets may reflect overfitting, data leakage, or limited external validity rather than true out-of-sample performance. The lack of prospective validation further exacerbates these limitations, as model performance may differ when applied to prospectively collected data and real-world clinical workflows.
31 of the 34 studies (91%) demonstrated high bias in model development, with all but one failing in the Analysis criteria of the PROBAST. The studies primarily failed in this domain due to inadequate reporting of calibration metrics, as previously mentioned, or to internal validation that consisted solely of a random data split. Few studies evaluated how model outputs would be integrated into perioperative workflows or assessed downstream clinical impact. In particular, the implications of AI-based risk stratification for thromboprophylaxis decision-making remain unclear, as most models were not linked to actionable treatment plans, changes in prophylaxis intensity, or patient-centered outcomes such as VTE incidence or bleeding risk. Thus, the clinical relevance of improved discrimination remains uncertain in the absence of evidence demonstrating meaningful influence on perioperative management. Although the models rated well on applicability, as seen in Appendix 4 must be cautious about early clinical adoption, as applicability in this context is limited to the cohort on which the models were trained and tested. This once again stresses the need for improved calibration and external validation reporting to increase transparency of these models.
The included studies demonstrated substantial heterogeneity, particularly in terms of surgical specialties and procedures. Our analysis captured a diverse range of surgical procedures, such as cardiac operations requiring cardiopulmonary bypass, orthopedic interventions (lower limb fractures, hip/knee arthroplasty), gastrointestinal surgeries (colorectal carcinoma, gastric cancer), neurosurgical cases (sellar region tumors), gynecological procedures (hysterectomy for various malignancies), and general surgical cases (inguinal hernia repair). Eight studies failed to specify precise surgical types, while several others covered multiple distinct procedures. This wide variation in surgical contexts presents significant challenges when interpreting findings, as baseline VTE risk profiles differ substantially between lower-risk ambulatory procedures and high-risk oncological surgeries. The pathophysiological mechanisms driving VTE risk likely vary by surgical approach, with different relative contributions from Virchow’s triad components across surgical specialties. Consequently, predictors that perform well in one surgical context may be irrelevant in another, limiting our ability to draw generalizable conclusions about optimal model architectures or input variables.
This heterogeneity also complicates the practical implementation of AI models, as healthcare systems must decide whether to adopt specialty-specific models or develop a single, generalizable model applicable across diverse surgical contexts. These challenges highlight a critical consideration in AI model development: whether to pursue generalizable models applicable across surgical contexts or precise models tailored to individual procedures or patient populations. A study on postoperative VTE risk prediction across multiple surgical types found that a generalizable deep learning model performed well in multi-center validation (AUC 0.79) but had lower specificity in smaller subgroups [24]. Analysis of the included studies demonstrated that specific AI models often achieve higher AUC values and sensitivity, while generalizable models can be utilized across different surgical fields. Current risk assessment models, such as the Caprini score, fit only the generalizable model, thereby reducing their effectiveness in specific populations. Neither approach is inherently superior; generalizable models excel at broad applicability, while specific models offer greater accuracy in targeted contexts.
The identified studies were geographically restricted to the United States (17) and China (17). This raises concerns about the generalizability of the findings to healthcare systems with different patient characteristics, clinical practices, and documentation standards. Most studies relied on single-center, retrospective data from distinct patient populations or healthcare settings, without external validation. This limitation is particularly problematic for VTE prediction models, as risk factors and their relative importance may vary across different populations and surgical practice patterns. Another important limitation of these studies is the heterogeneity in follow-up duration, which compromises the comparability of VTE incidence estimates and overall model performance. A meta-analysis of 6258 studies found that the risk of VTE remains roughly 10.1% in the fourth week postoperatively, highlighting the importance of adequate follow-up duration [28]. Regarding outcomes, most studies did not differentiate between DVT and PE when developing prediction models. While both are manifestations of VTE, they have distinct risk factor profiles, clinical presentations, and disease outcomes [29] that may benefit from separate predictive approaches for optimal accuracy. This lack of distinction represents a significant limitation in the current literature, as composite VTE outcomes may mask significant differences between these two manifestations, potentially leading to suboptimal risk stratification for specific patient populations.
While these limitations warrant careful consideration, they do not diminish the role that AI models can serve in improving VTE risk stratification. Traditional VTE risk assessment tools, such as the Caprini score, rely on a standardized set of general factors that, while clinically validated [5], lack the specificity and nuance that AI models can achieve. The Caprini model assigns points based on broad categories such as age (1–5 points), BMI > 25 (1 point), major surgery (2–5 points), history of prior VTE (3 points), malignancy (2 points), and immobilization (1–2 points). These parameters, while important, treat all patients within the same broad clinical categories as similar and fail to account for the complex interactions between patient-specific physiological markers and procedural details. In contrast, AI models can detect subtle patterns by incorporating novel variables, thereby enabling more precise risk stratification. For instance, the HbA1c levels reported by Ali et al. [30] offer insight into glycemic control, while direct bilirubin levels in Ding et al. [27] provide specific information about liver function that conventional risk assessment models do not capture. AI models can also differentiate VTE risk based on specific surgical approaches, such as open versus minimally invasive [31]. In contrast, the Caprini score only accounts for “major surgery” without accounting for variations in technique. Laboratory values such as albumin [21] and hematocrit [32] were utilized as objective, quantifiable measurements of physiological status that supersede the non-AI models’ assessment of general health status. Mobility, for example, could be assessed using the AMPAC score, which may provide additional insight into functional status and offer predictive value for VTE [33]. By analyzing these detailed factors, AI models can create highly personalized risk profiles that reflect the multifactorial and patient-specific nature of VTE development, enabling more tailored prophylaxis strategies that are not currently possible with the one-size-fits-all approach of traditional scoring systems. Despite promising discrimination performance in head-to-head comparisons, the current evidence does not support premature clinical adoption of AI-based postoperative VTE risk prediction models. Most included studies relied on retrospective, single-center datasets and lacked calibration reporting and external validation across independent cohorts. Few models were evaluated across diverse surgical populations, healthcare systems, or geographic settings, limiting confidence in their generalizability. Moreover, temporal validation was rarely performed, raising concerns about model robustness to evolving clinical practices, patient demographics, and perioperative care pathways. Collectively, these limitations underscore the need for improved calibration reporting and rigorous external, temporal, and geographically diverse validation before AI-based VTE risk models can be considered for routine clinical implementation. Prospective studies comparing these models to established conventional methods and implementing them in clinical practice through real-time EMR integration will be essential to demonstrate their real-world impact on patient outcomes and resource utilization.

Comments (0)