
Remember me
This analysis included data from nine phase 1, 2, and 3 studies: one study in healthy participants (ARRAY-162-105, part 1 only), four studies in participants with melanoma (COLUMBUS [NCT01909453], POLARIS [NCT03911869], C4221010 [(NCT01436656], LOGIC 2 [NCT02159066] studies], two studies in participants with metastatic CRC (C4221001 [NCT01719380] and BEACON [NCT02928224] studies), one study in participants with NSCLC (PHAROS study [NCT03915951]), and one study in participants with other solid tumors [C4221005 (NCT01543698)] [4, 6,7,8,9,10,11,12,13]. Supplementary Table S1 provides an overview of these nine clinical studies, including their dosing schedules and plasma samplings. The majority of the concentration data included in this popPK analysis were from patients who were dosed on the basis of the approved labeling [1]. In several phase 1/2 dose escalation studies, such as Studies C4221010 and C4221001, a wide range of encorafenib daily doses from 50–700 mg were evaluated (Supplementary Table S1). All studies were conducted in accordance with the Declaration of Helsinki and the International Council of Harmonization Guideline for Good Clinical Practice and were approved by an institutional review board or ethics committee at each site. All participants provided written informed consent for study-related treatments and procedures.
2.2 SoftwareAnalyses were performed using nonlinear mixed effects modeling methodology as implemented in Nonlinear Mixed-Effects Modeling (NONMEM) version 7.5.0 (ICON Development Solutions, Ellicott City, MD). Perl-speaks-NONMEM version 5.3.0 was used for conducting predictive checks and covariate testing. R software version 4.2.1 (R Foundation for Statistical Computing, Vienna, Austria) was used for graphics, other statistical analyses, diagnostics, and data manipulation. The first-order conditional estimation method with interaction was used for the base model. However, the SAEM-IMP algorithm was used for the final model, which combines the stochastic approximation expectation-maximization (SAEM) framework with an importance sampling (IMP) step to improve precision in the likelihood approximation and enable reliable estimation of parameter uncertainty. For SAEM-IMP estimation with Mu-referencing, random effect variances estimated to be near zero were fixed to a small positive value (0.025) to maintain numeric stability of the stochastic approximation.
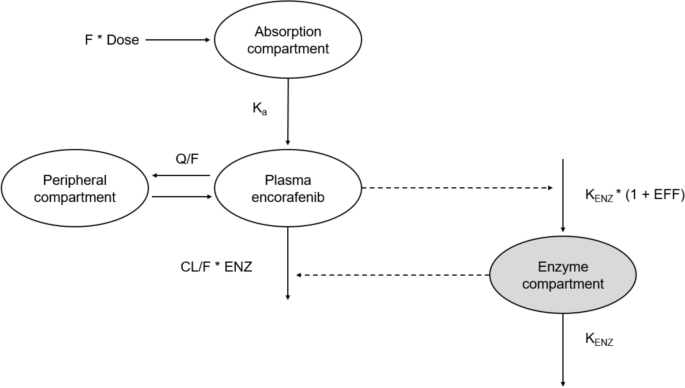
2.3 Base PopPK ModelSeveral PK models and structural approaches were evaluated to characterize the PK profile of encorafenib. These included a one-compartment model, a two-compartment model, and models incorporating transit absorption compartments. A base two-compartment model with linear elimination and first order-absorption was developed, which is in agreement with the prior encorafenib PK model [5]. Unlike the prior encorafenib popPK model (with time varying apparent clearance [CL/F]) developed to support the NDA, an encorafenib concentration-dependent autoinduction effect was incorporated in this global PK model instead of time–Emax. The autoinduction process in this model was described using an indirect-response, semi-mechanistic enzyme turnover model previously described in several publications [14,15,16]. Induction effect was modeled as an increase in the enzyme production rate as shown in Fig. 1. The equation used to describe the enzyme turnover, or change in the amount of enzyme in the enzyme pool over time, is presented below:
$$\begin\left(\fracA}_}}T}\right)=_}\times \left(1+\text\right)- _}\times _},\end$$
(1)
where AENZ is the ratio of enzyme amount to the baseline, kout is the first-order rate constant for the decrease in the ratio of enzyme amount to the baseline, T is the elapsed time since the start of encorafenib administration, kin is the zero-order rate constant for the production of enzyme, and effect (EFF) is the relationship between the encorafenib concentration and the induction of enzyme. To normalize the enzyme concentrations to unity at baseline, kin was set equal to kout.
Fig. 1 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Encorafenib pharmacokinetic model. Encorafenib autoinduction was modeled with an enzyme turnover model, in which the EFF of encorafenib concentration in the central compartment increased the KENZ. EFF is described as sigmoid Emax function in Eq. 2. CL clearance, EFF effect, ENZ enzyme pool, KENZ enzyme production rate, Q apparent intercompartmental clearance, V apparent volume of distribution
Linear and sigmoid maximum effect (Emax) models for EFF were tested. The EFF of encorafenib drug concentration on enzyme production was best described through an Emax relationship described below:
$$\beginEFF= \frac_}\times _}^}}_^+ _}^},\end$$
(2)
where EC50 is the encorafenib concentration (CP) when half Emax is observed, and \(\gamma\) represents the steepness of the relationship.
To most accurately model the concentration-dependent autoinduction and facilitate model building, base model development started with two studies (Studies C4221001 and C4221010) containing extensive serial PK data across a wide range of encorafenib dose levels before reaching steady state (Supplementary Table S1 and Fig. 2). Base model development started with data from the first cycle of Studies C4221001 and C4221010 (N = 143) with stepwise addition of data from the remaining studies, followed by the addition of the entire time course of observations available from all studies to reach the final base popPK model.
Fig. 2 The alternative text for this image may have been generated using AI.
The alternative text for this image may have been generated using AI.Encorafenib observed concentration versus time by study and dose levels. The concentration-time profiles are presented on semi-log scales for better visualization
2.3.1 Random Effects ModelInter-individual variabilities (IIVs) in the PK parameters were modeled using multiplicative exponential random effects of the form:
$$\begin_=\theta \times ^_},\end$$
(3)
where θ is the typical value of the parameter and ηi denotes the IIV random effect accounting for the ith individual’s deviation from the typical value having zero mean and variance ω2. The approximate percentage coefficient of variation (%CV) was reported as:
$$\begin\%CV= \sqrt^}\times 100\%.\end$$
(4)
The vector of IIV random effects has variance-covariance matrix omega (Ω). The diagonal Ω matrix was applied first and other (unstructured) Ω block structures (off-diagonal element) were also explored by examining the potential correlations among all the empirical Bayes estimates of the IIV random effects. Only diagonal Ω matrix was applied since the correlation for all the empirical Bayes estimates or “posthoc” of the IIV random effects was low (R2 < 0.6). Residual variability (intraindividual random effect) was modeled using a proportional model:
$$\begin_=_\times \left(1+W\times _\right)+W\times _\end,$$
(5)
where Yij denotes the observed concentration for the ith participant at time tj, the Fij denotes the corresponding model-predicted concentration, and εij denotes the intra-individual random effect, assumed to have a mean of zero and variance (σ2) of 1. As σ2 was fixed to 1, multiplying ε by W, W was estimated as two of the thetas (θs).
2.3.2 Evaluation of Covariates and Full Model DevelopmentCovariates evaluated in this analysis were based on clinically relevant parameters and known information from prior encorafenib modeling experiences [5]. These covariates included demographic characteristics (age, body weight, sex), baseline laboratory values (total bilirubin, total protein, albumin, aspartate aminotransferase [AST], alanine aminotransferase [ALT], lactate dehydrogenase [LDH]), baseline disease characteristics (Eastern Cooperative Oncology Group performance status [ECOG PS], tumor type), concomitant medication use (absence or weak, strong CYP3A inhibitors or inducers), and treatment type (monotherapy versus combination with binimetinib versus other combinations). Covariates were graphically plotted against individual ηs to identify any relationships. Covariates were screened for pairwise correlation and, if strong correlation existed, only one was selected for evaluation based on physiological or clinical relevance and graphical assessment. Demographic characteristics, baseline laboratory values, baseline disease characteristics, concomitant medication use, and treatment type were tested on the CL/F term. Demographic characteristics were tested on Vc/F and Ka.
The significance of covariates was tested using a stepwise covariate model building procedure (SCM). Categorical covariates were included by a linear model. Continuous covariates were included by a power model centered on the median value of the population in the analysis. The addition of an individual covariate parameter was performed at a prespecified significance level of α = 0.05 with the likelihood ratio test (LRT) to assess the significance of a covariate or covariates in the model in a stepwise fashion. The model was then subjected to a backward elimination algorithm, using LRT to assess the significance of a covariate or covariates in the model when eliminated from the full model. The test for elimination of an individual covariate parameter, given that others are kept in the model, was performed at a prespecified significance level of α = 0.001. Covariates were removed from the full model in a stepwise fashion, and the change in objective function value (OFV) was calculated.
2.3.3 Final popPK ModelThe final model was obtained from the last stage of the elimination algorithm in the SCM, in which all of the remaining covariate parameters, when tested one at a time, resulted in a statistically significant result for the LRT (i.e., p < 0.001). To obtain the most parsimonious and stable final model, the candidate covariate model resulting from the backward elimination step in the SCM was subjected to a separate NONMEM run with $COV to examine any sign of model over parameterization (e.g. condition number) and poorly estimated parameters.
2.3.4 Assessment of Model Adequacy and Predictive PerformanceAt all stages of model development, assessment of model adequacy was conducted through multiple approaches. Goodness of fit (GOF) for different models was evaluated on the basis of the change in OFV, condition number, visual inspection of different diagnostic plots, precision of the parameter estimates, and decreases in inter-individual variability and residual variability. Standard diagnostic GOF plots included population predictions (PRED) and individual predictions (IPRED) versus dependent variable, individual weighted residuals (IWRES), conditional weighted residuals (CWRES); normalized prediction distribution error (NPDE) versus time; IWRES, CWRES, and NPDE versus PRED, ETAs versus continuous covariates, ETAs versus categorical covariates (box plots), density plots of ETAs, and ETA correlation plot. Confidence intervals (95% CI) around the parameter estimates were generated for standard errors generated on the basis of asymptotic standard errors from the NONMEM covariance step. Both η-shrinkage (1 − standard deviation [ηEBE]/ω) and ε-shrinkage (1 − standard deviation [IWRES]) were evaluated to assess the validity of using post hoc individual parameter estimates for model diagnosis [17]. The performance of the final model was evaluated by simulating data using the parameter estimates from the final model (fixed and random effects) and by conducting a prediction-corrected visual predictive check (VPC).
2.3.5 Missing Data and ImputationsAll patients with at least one post-dose encorafenib plasma concentration value were included in the analysis. Plasma concentration values that are below the limit of quantification represented < 10% of the dataset and were excluded from the analysis using the M1 method [18, 19]. Baseline continuous covariate values that had < 10% of values (body weight, eGFR, total protein, albumin, bilirubin, AST, ALT, and LDH) were imputed with the population median value. Categorical covariates with < 10% missing values (ECOGPS) were assigned to the most common value. Race was not evaluated since 90% of participants were White (Table 1) and covariate assessment was not considered meaningful. Similarly, 99% of participants had either absence of use or concomitant administration of only a weak CYP3A inducer (Table 1); thus, concomitant CYP3A inducer category was not evaluated. Concomitant CYP3A inhibitor was evaluated as absence or weak CYP3A inhibitors versus use of concomitant moderate or strong CYP3A inhibitors. Tumor type was evaluated as melanoma versus CRC versus all other tumor types, which included healthy (1%), lung (7%), and other (5%).
Table 1. Summary of baseline covariates and demographics
Comments (0)