
Remember me
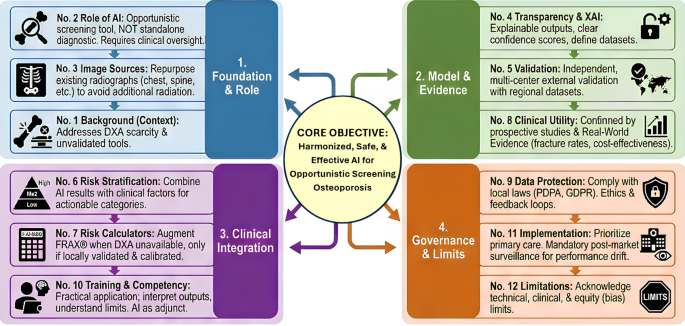
The consensus statements underscore that AI has a valuable but supporting role in osteoporosis care, particularly as a tool for opportunistic screening in the Asia-Pacific context [22]. Given the underdiagnosis of osteoporosis in the region due to various reasons such as limited DXA and human resources, AI can help identify at-risk individuals from data that are already available in the healthcare system in a time-effective manner. Statement 1 highlights the rationale: many Asia-Pacific patients who could benefit from osteoporosis assessment are missed under current practice, and unregulated AI use could lead to inconsistent standards [23, 24]. By establishing a unified guidance, the consensus aims to channel AI development and deployment toward filling the diagnostic gap safely. It is important to note that the incremental value of AI opportunistic screening varies substantially across the Asia-Pacific region depending on DXA availability. In settings with low DXA density (much of South and Southeast Asia), AI screening offers clear incremental value by identifying high-risk individuals who would otherwise remain undiagnosed. In contrast, in high-DXA-density settings such as Japan and South Korea—where DXA accessibility and cost are comparable to opportunistic imaging—the marginal benefit is less straightforward. Routine deployment of AI opportunistic screening tools in such contexts may carry a meaningful risk of increasing false-positive referrals without a commensurate improvement in diagnostic yield, and health technology assessments should carefully evaluate whether AI screening is additive or merely duplicative of existing DXA pathways.
One of the most significant implications is the use of AI to analyze existing medical images for signs of low bone density or fractures (Statement 3). This approach can dramatically expand the screening reach. For example, an individual receiving a chest X-ray for a cough could simultaneously be screened for osteoporosis risk by an AI algorithm analyzing the thoracic spine or rib bone patterns on that X-ray [11]. Such opportunistic screening is particularly relevant in the Asia-Pacific region, where dedicated osteoporosis screenings are often not performed [22]. AI enables “missed” patients to be evaluated using scans performed for other purposes. Studies from within and outside the region support this strategy: a deep learning model was able to identify patients with osteopenia or osteoporosis with high accuracy [25]. Likewise, algorithms processing CT scans have shown a strong correlation with DXA measurements of BMD [26,27,28]. These findings demonstrate that AI can estimate or correlate with DXA-derived BMD values using more ubiquitous imaging modalities, providing a surrogate assessment in settings where DXA is unavailable. The consensus embraces this potential, suggesting that preexisting images (chest, abdomen, hip X-rays, etc.) be the primary data source for AI-based bone health assessments (Statement 3) to avoid unnecessary radiation exposure and leverage whatever imaging is available in resource-limited settings.
Moreover, AI can assist in fracture risk stratification by integrating imaging findings with clinical risk factors (Statements 6 and 7). This aligns with current clinical tools such as FRAX® (Fracture Risk Assessment Tool), which calculates 10-year fracture probability based on risk factors and BMD [29, 30]. The panel recommends that AI-derived BMD or other outputs may augment such risk calculators only under certain conditions; notably, the AI should be well-validated against DXA in the target population and calibrated to local fracture epidemiology (Statement 7). This caution is warranted because while AI models might estimate BMD, these estimates have an error margin larger than that of DXA and could misclassify some patients [30]. Nonetheless, in settings where DXA is unavailable, a validated AI tool could provide a provisional risk assessment to guide management. For instance, an AI that analyzes a hip X-ray to predict BMD could be used to feed a FRAX calculation, as long as it is shown to be accurate for that ethnic population and fracture data. This approach can potentially improve risk stratification in primary care: high-risk patients (e.g., an elderly woman flagged by AI as likely osteoporotic) can be referred for confirmatory DXA or started on preventive therapy sooner, while low-risk patients are reassured or advised on lifestyle changes [30]. One study demonstrated that a deep learning–based model (DeepSurv) achieved fracture-risk prediction performance comparable to that of the conventional FRAX tool in diabetic patients [31]. These findings indicate that AI has the potential to improve fracture-risk estimation in clinical subgroups where conventional tools have known limitations.
Regulatory science is also evolving in a direction that may broaden the translational pathway for BMD-centric innovations, including AI-enabled bone health assessment. On December 19, 2025, the US Food and Drug Administration (FDA) qualified total hip BMD (assessed by DXA) as a validated surrogate endpoint for phase 3 clinical trials of investigational therapies for postmenopausal women with osteoporosis at risk for fracture, defined as the percentage change from baseline at 24 months in total hip BMD [32]. This milestone signals increasing regulatory acceptance of BMD as an efficacy outcome (under specific conditions), which may create clearer opportunities to evaluate AI tools not only against DXA correlation metrics but also within BMD-driven clinical pathways. Nevertheless, it is critical to distinguish FDA-qualified DXA-derived total hip BMD from AI-estimated BMD: AI outputs should be treated as screening surrogates unless and until robust bridging evidence demonstrates equivalence, calibration, and clinical utility in the intended population (including device- and workflow-specific performance).
By following Statement 2’s guidance that based on current evidence, AI is most appropriately positioned as an aid for risk assessment rather than a standalone diagnostic instrument, healthcare providers can incorporate AI outputs into their decision-making without over-relying on them [33]. The consensus clearly positions DXA and clinical evaluation as the gold standards for diagnosis—consistent with international definitions of osteoporosis and national guidelines. AI’s role is to alert and inform. This delineation is crucial for maintaining clinical prudence: while AI might flag a patient as high risk, the physician still must confirm osteoporosis via DXA or recognize that AI’s suggestion of “osteoporosis” is not definitive. This approach is akin to using AI as a highly sensitive screening test that needs a specific confirmatory test [34]. It also helps manage patient expectations—if patients are made aware that an AI screening indicated they might have low bone density, they can be counseled that a formal DXA is needed to diagnose and that AI is not a “virtual DXA” [18]. In short, the consensus integrates AI into the existing care pathway, rather than replacing elements of it. This integration ensures that improvements in early detection (through AI) do not come at the cost of diagnostic accuracy or adherence to evidence-based treatment thresholds [35,36,37].
The consensus statements also highlight some forward-looking applications that can transform osteoporosis care. For example, wearable technologies (mentioned in the scope of Statement 1) could continuously monitor risk factors such as physical activity, gait stability, or even bone relevant biomarkers, feeding data to AI algorithms. Although still emerging, such approaches could enable “continuous fracture risk monitoring” in the community [38, 39]. It should be noted that the application of wearable technologies to bone health monitoring remains at an early investigational stage (Technology Readiness Level 3–4); current evidence is largely proof-of-concept, and wearables are included in the consensus scope as a forward-looking direction requiring dedicated validation before clinical deployment. One can envision AI-driven assessments from smartwatches or sensor insoles that gauge frailty or fall risk, prompting timely interventions [40]. The panel’s inclusion of wearables acknowledges this potential. AI may analyze mobility patterns from a wearable device to predict if a patient’s fracture risk is increasing (due to declining gait speed or balance), triggering a clinic visit [41]. Another novel application area is AI-driven treatment decision support (Statement 1 scope). This may involve algorithms that support clinicians in determining the most appropriate therapeutic strategies (e.g., calcium/vitamin D supplementation and exercise) through the synthesis of patient-specific risk factors, individual preferences, and evidence-based guidelines [42]. While few systems currently do this, the consensus anticipates a future where AI might suggest, for instance, that a high-risk patient with certain comorbidities might best benefit from a specific osteoporosis medication, or that a patient with moderate risk could be monitored rather than medicated—all under physician oversight [43].
Importantly, the consensus calls for these innovations to be adapted to regional needs. “Regional adaptation” (Statement 2) implies that AI models and thresholds might need adjustment for different Asia-Pacific populations [44]. The epidemiology of osteoporosis varies widely across Asia. For instance, hip fracture rates are very high in parts of East Asia but lower in some other areas [4]. An AI predicting absolute fracture risk must account for those baseline differences—perhaps via calibration with local fracture incidence data (as Statement 7 suggests). Likewise, risk factors such as body size, diet, or genetics differ among Asian subpopulations, meaning that an AI trained predominantly on Western data might underperform if applied without modification. The consensus therefore encourages the development of localized reference standards (e.g., using local BMD reference databases and incorporating regional risk factors such as high prevalence of vitamin D deficiency and population-specific lifestyle factors). By doing so, AI tools will yield more accurate predictions for the populations they serve than using an AI tool without including population-specific risk factors and/or calibration. It should also be noted that the current consensus statements were developed primarily with reference to postmenopausal women, who represent the highest burden group and for whom the majority of AI validation data exist. AI model performance in men, individuals with glucocorticoid-induced osteoporosis (GIO), and those with secondary causes of bone loss is less well established, and validation data in these groups remain sparse. Direct application of current AI tools to these populations warrants caution pending dedicated validation studies. Future prospective studies should explicitly include these groups.
The immediate benefit of implementing this consensus will likely be improved early identification of osteoporosis. If health systems in the Asia-Pacific region adopt AI screening (for example, automatically running a validated AI on chest X-rays or CT scans of older patients), many more high-risk individuals can be funneled into appropriate care pathways. Early detection is critical—as noted, osteoporotic fractures (especially hip fractures) carry significant morbidity and mortality, with a one-year mortality rate of approximately 15% in some studies [45]. Treating osteoporosis with pharmacotherapy can substantially reduce fracture risk, so catching patients before the first fracture is a public health priority. The consensus-driven approach ensures that such AI-based screening would be performed in a standardized and clinically responsible manner across the region. AI-driven opportunistic screening via chest X-rays improved quality-adjusted life years and was cost-effective in an older population [17]. While real-world confirmation is still needed (addressed in Statement 8), AI-driven screening has the potential to improve early detection and address unmet diagnostic needs in the Asia-Pacific region.
Challenges and considerations in implementationWhile AI presents exciting opportunities, the consensus panel is emphatic that its implementation must overcome several challenges and adhere to strict standards to truly benefit patients [46]. One major theme in the statements is the need for rigorous validation and transparent reporting of AI performance (Statement 5). This arises from the recognition that many AI models perform impressively in initial studies but may not generalize well. The literature shows numerous examples where AI algorithms achieved high accuracy in a development dataset but failed to replicate those results externally. For instance, a systematic review by Yu et al. (2022) found that in 27 of 31 radiology AI studies (87%), external validation performance was significantly lower than internal performance, with median AUC decreasing by 0.06–0.12 across modalities [47]. In the osteoporosis AI literature specifically, Gatineau et al. (2024) documented that of dozens of published AI studies for osteoporosis, only 2 had undergone formal external validation [18]. These examples underscore the risk of over-optimistic internal performance metrics. In osteoporosis, this risk is heightened by heterogeneity in imaging techniques and patient demographics across the Asia-Pacific region. The consensus therefore mandates independent multicenter external validation before any AI tool is widely deployed (Statement 5). This means that if an AI is trained on scans from Thailand, it should be evaluated on data from other countries (such as India, Japan, and Malaysia) to guarantee that it continues to perform correctly. External validation is essential because, as noted, reduced algorithm performance on external datasets is common when models encounter shifts in population or imaging settings [47]. By requiring representative regional datasets, the panel is essentially saying an AI must prove itself on the diversity of real-world cases in Asia-Pacific—different ethnicities, ages, and clinical profiles—and not just in a controlled or homogeneous sample.
The panel also stresses comprehensive performance reporting: metrics such as area under the ROC curve (AUC), area under the precision–recall curve (AUPRC), sensitivity, specificity, and calibration should all be reported (Statement 5). This addresses a prevalent issue where studies might tout a single metric (often “accuracy”) which can be misleading. For example, in a class-imbalanced scenario, accuracy alone can be high (for example, if few people have osteoporosis, a fundamental model stating “no osteoporosis” for everyone may be 90% correct because 90% do not have it, but it fails to discover any true cases). Reporting AUC and calibration gives a fuller picture of how well the model distinguishes risk and whether its probability outputs are reliable [48]. The consensus echoes emerging AI reporting guidelines such as TRIPOD-AI for prediction models and CONSORT-AI for clinical trials involving AI, urging investigators and developers to follow these standards [49, 50]. By aligning with international frameworks FDA, European Medicines Agency (EMA), Pharmaceuticals and Medical Devices Agency (PMDA) regulatory guidance and World Health Organization (WHO)/International Osteoporosis Foundation (IOF) recommendations), the statements push for a high quality of evidence. In practice, this means that any AI tool should ideally undergo the kind of evaluation we expect of medical devices or new diagnostic tests: preferably a prospective trial (if used in patient care decisions) or at least a thorough validation on unseen data according to a predefined protocol [51].
Another challenge is ensuring model transparency and explainability, as elaborated in Statement 4. “Black-box” algorithms can undermine clinician and patient trust, and make it difficult to identify errors or biases. The consensus advises that AI systems incorporate explainable AI (XAI) features such as visual heatmaps showing which areas of an X-ray contribute to a low BMD prediction, or provide a confidence score with the result [52, 53]. This is in line with broader AI ethical principles that call for transparency and accountability in AI decisions. For instance, the WHO’s six principles for AI in healthcare include transparency, explainability, and intelligibility of AI systems [54]. In practical terms, if an AI report on a patient’s radiograph says “High risk of osteoporosis,” it should also include additional info like “because cortical bone thickness appears reduced at these points (highlighted on image)” or “model confidence: 85%.” Such features help the clinician understand and trust the result, or potentially question it if it contradicts clinical exam. The consensus also calls for clear definitions of terms such as accuracy, precision, and reliability to avoid confusion (Statement 4). This may seem technical, but it matters when AI results are communicated. Clinicians should know, for example, the difference between the AI’s precision (consistency) and accuracy (closeness to true value)—an AI might be very consistent but consistently off by a margin in BMD estimation, which has different implications than random error. The panel’s desire for clarity ensures that end users of AI (doctors and radiographers) are not deceived by overly optimistic statements.
Data quality is another crucial consideration. Statement 3 notes that AI accuracy depends on standardized imaging protocols and adequate quality. If images are noisy, low-resolution, or taken with varied techniques, AI predictions can be erroneous. Many healthcare facilities in low-resource settings may have older X-ray machines or less standardized acquisition, which could degrade AI performance. Therefore, implementing AI might require investments in quality control—e.g., ensuring X-ray machines are calibrated and images meet certain resolution criteria, or the AI might need a quality-check module to reject images that are not suitable (for instance, an algorithm might flag “image too low quality for analysis”) [55]. Additionally, patient position and artifacts can impact measurements such as femoral geometry on X-rays, so training radiographers on proper techniques remains important even when AI is involved [56]. The agreement basically warns that AI is not magical—“garbage in, garbage out” remains true. Efforts to deploy AI should go hand-in-hand with improving image quality and consistency across sites.
A significant challenge in the Asia-Pacific deployment of AI is ensuring equity and avoiding bias (Statement 12’s equity limitations, and Statement 9’s emphasis on fairness). The “digital divide” exists: urban tertiary hospitals may have advanced information technology infrastructure to run AI tools, whereas rural clinics may lack even reliable internet or picture archiving systems (e.g., PACS (Picture Archiving and Communication System)) [57]. If AI is only implemented in wealthy centers, it could widen health disparities, benefiting patients who already have more access. The consensus insists on prioritizing deployment in primary care and underserved regions (Statement 11)—which implies making the technology accessible and user-friendly in those settings. For example, an AI tool might need to be embedded in a lightweight application that can run offline or on portable devices for rural outreach. In regions without advanced information technology infrastructure, AI tools can be run in a cloud-based server. Additionally, algorithmic bias must be addressed: if an AI was trained mostly on, say, postmenopausal women from one ethnic group, its performance on men or on other ethnicities might be poor, potentially leading to underestimation or overestimation of risk in those groups. There is evidence that using Caucasian BMD reference standards can misclassify Asian patients; similarly, an AI might inherit such biases if not retrained on local data [58]. The panel’s recommendations to use local reference databases and to continuously collect feedback (Statements 7 and 9) serve as safeguards. We suggest a feedback loop where if clinicians notice systematic errors (e.g., AI missing osteoporosis in very petite individuals or in men), these cases should be reported back to developers so the model can be improved. This is a form of active bias mitigation—acknowledging that the first version of any AI might not be perfect, but with real-world testing and iterative updates (retraining with more diverse data), it can become fairer and more robust.
Data governance and privacy pose another set of challenges. Statement 9 addresses compliance with local and international data protection laws. Asia-Pacific countries enforce various regulations (for example, Singapore’s PDPA and Europe’s GDPR (General Data Protection Regulation)) which influence many global practices, such as the HIPAA (Health Insurance Portability and Accountability Act) for any collaboration with US entities) [59]. AI development often requires large datasets, and sometimes cross-border data sharing (to obtain enough cases of certain populations). However, many nations are increasingly concerned about data sovereignty—patient data may not be allowed to leave the country or even the hospital network. This complicates multicenter collaborations [60]. The consensus suggests acknowledging and addressing these restrictions explicitly. Solutions might include federated learning approaches (where AI models are trained on-site in each location and only model weights are shared, not raw data) or establishing secure regional data hubs with proper agreements [61]. Additionally, compliance means having robust patient consent processes and de-identification for any data used in AI training [60, 62]. A related point is that AI algorithms, once deployed, should also protect patient privacy—e.g., if an AI platform is cloud-based, it must ensure secure transmission and storage of medical images (encryption, etc.) [62]. The consensus aligning with WHO and OECD (Organisation for Economic Co-operation and Development) AI principles also implies the need for accountability: if an AI makes a significant error that harms a patient, there should be clarity on responsibility (the clinician? the hospital? the AI vendor?) [63]. Currently, regulatory agencies are grappling with this. The US FDA has begun treating some AI algorithms as medical devices requiring approval, and similar regulatory pathways are developing in Asia [64]. The consensus essentially prepares the stakeholders to consider these issues: only use AI that meets regulatory approval where required and maintain monitoring postimplementation.
Regulatory frameworks for AI in healthcare across the Asia-Pacific regionThe regulatory classification of AI as a medical device (Software as Medical Device (SaMD)) varies considerably across the Asia-Pacific region, and understanding this landscape is essential for responsible AI deployment. In Japan, the Pharmaceuticals and Medical Devices Agency (PMDA) governs AI-based medical devices under the Pharmaceutical and Medical Device Act, with a dedicated SaMD pathway for AI/ML-based diagnostic tools requiring premarket review. In South Korea, the Ministry of Food and Drug Safety (MFDS) has published dedicated AI medical device guidelines since 2019, classifying AI diagnostic tools by risk level and requiring clinical performance evaluation. In Australia, the Therapeutic Goods Administration (TGA) regulates SaMD under an updated framework (2023), aligned with International Medical Device Regulators Forum (IMDRF) guidance. In Singapore, the Health Sciences Authority (HSA) has issued a regulatory framework for software-based medical devices. In Taiwan, the Taiwan Food and Drug Administration (TFDA) has issued AI medical device guidance documents requiring performance and explainability reporting. In China, the National Medical Products Administration (NMPA) has issued AI medical device classification guidelines, with a risk-tiered approval pathway. Across the region, these frameworks broadly align with IMDRF SaMD guidelines and the IMDRF AI/ML SaMD action plan, though the pace of implementation differs. A key distinction from the US FDA’s approach is that several Asian jurisdictions currently require a full pre-market submission for AI diagnostic tools rather than the FDA’s pre-determined change control plan for AI/ML devices, which may affect the speed of iterative model updates post-deployment. A significant regulatory gap exists in lower-middle-income Asia-Pacific countries where formal AI medical device classification frameworks are nascent or absent, reinforcing the tiered compliance framework recommended in Statement 9 and the need for minimum baseline standards applicable across all resource settings.
The statements on training and communication (Statement 10) highlight that human factors are as important as technical factors. Many clinicians and radiologists in the region may not have had formal training in AI concepts. A survey by the American Medical Association found that while physician use of AI is increasing, many still have concerns and knowledge gaps about AI in practice [65]. The consensus recommends structured training focusing on practical competencies—how to interpret AI outputs and integrate them into patient care. This could mean developing short courses or workshops for healthcare professionals on topics such as: understanding AI confidence levels, recognizing scenarios where AI might be less reliable (e.g., unusual patient anatomy or imaging artefacts), and explaining AI findings to patients. The delightful metaphor provided (“bus drivers don’t need to know how gearboxes work, only how to shift gears”) captures an important point: clinicians do not need to be data scientists, but they do need to know when and how to use the AI “gearbox.” For example, a primary care doctor receiving an AI-based report should know that a “red flag” from the AI is a call to action (e.g., refer for DXA or specialist consult), while a “green flag” (low risk) still does not guarantee that the patient is fine if other clinical risk factors suggest otherwise. Training should also emphasize that AI is an adjunct—a second pair of eyes—not an oracle. This mindset will help clinicians maintain their own clinical judgment, thereby reducing over-reliance on AI and preventing de-skilling [66].
From an implementation standpoint, the consensus advocates for the integration of AI into existing clinical workflows and information systems (Statement 11). This is a nontrivial challenge: many healthcare IT systems in the Asia-Pacific region are not fully interoperable, and AI tools often start as standalone software. If using AI requires multiple extra steps (e.g., exporting an image to a separate application, then importing results back), busy clinicians may ignore it. Thus, seamless integration with PACS and HIS (Hospital Information System) is crucial [67, 68]. Multilingual accessibility is another important point the panel made: Asia-Pacific’s linguistic diversity means AI interfaces and reports should be available (or translatable) in local languages, not just English. Otherwise, critical information might be lost on the end-user [44].
Monitoring and feedback loops (Statement 11) are highlighted to ensure that AI remains safe over time. Unlike a static medical device, AI software can “drift”—for example, if an algorithm is deployed in 2019 and in 2025, the patient population’s characteristics have shifted (perhaps due to new treatment patterns, post-COVID health changes, etc.), the AI might start performing worse. Therefore, postmarket surveillance akin to pharmacovigilance is recommended [69]. This could involve periodic audits of AI performance metrics, user reports of any errors, and even a system for end-users to flag cases where the AI was wrong (as mentioned, clinicians reporting discordant AI vs. DXA results to the vendor; Statement 9). The consensus effectively preempts this by advising it as best practice. One outcome of monitoring could be the decision to retrain the AI model after a certain time with new data. The feedback from clinicians is invaluable in this process—it grounds AI development in reality. For example, if multiple doctors report that the AI tends to miss fracture in patients with osteoarthritis (perhaps because osteophytes confuse it), the developers know what specific issue to address in the next version. This collaborative improvement cycle is how AI can become safer and more accurate over time [70].
Cost and economic considerations are also a challenge. Statements 8 and 11 mention evaluating cost-effectiveness and performing local health economic analyses. Introducing AI has upfront costs—software licensing, hardware (perhaps GPUs for processing), integration expenses, training staff, etc. Healthcare budgets in many Asia-Pacific countries are constrained [71]. It is generally agreed that cost-effectiveness must be demonstrated through the use of local data. For instance, an AI screening program implemented in a country with a very low fracture incidence may be less cost-effective than one in a country with a high incidence, unless the cost of AI remains substantially low. Conversely, in regions where current screening practices are nearly absent, even moderately effective AI could substantially impact fracture prevention and reduce costs by preventing fracture treatments. To make Statement 8’s requirement for clinical utility demonstration more operational, meaningful benefit should be assessed against a framework of evaluable endpoints: (1) incremental change in osteoporosis diagnosis rate (new DXA-confirmed diagnoses per 1000 patients screened versus usual care); (2) reduction in time-to-first-treatment among newly diagnosed patients (months from AI screening flag to pharmacotherapy initiation); (3) proportion of fragility fractures preceded by an AI-generated risk alert (retrospective audit metric); and (4) incremental cost-effectiveness ratio (ICER) expressed as cost per quality-adjusted life year (QALY) gained relative to local willingness-to-pay thresholds, which vary across the region (approximately 1–3 × GDP per capita in most Asia-Pacific countries). These endpoints are proposed as minimum reporting requirements for real-world implementation studies. The consensus recommends reviewing the outcomes and economics every 3–5 years (Statement 11). This means that if AI technology becomes cheaper or more effective, or if epidemiology changes, the guidelines on who to screen and how might be updated. The 3–5 year review interval aligns with the typical guideline update cycle used by major clinical bodies (e.g., International Osteoporosis Foundation, NICE) and reflects the pace at which meaningful new evidence from prospective studies is likely to accumulate. In addition to scheduled reviews, event-driven reviews should be triggered by: (a) documented AI performance drift exceeding predefined thresholds; (b) significant changes in fracture epidemiology or DXA availability at the regional level; or (c) major regulatory changes in AI medical device classification across Asia-Pacific jurisdictions.
Finally, multistakeholder collaboration is emphasized (Statement 11) as an overarching need to tackle these challenges. Healthcare providers can work with tech companies to co-design AI tools that fit clinical workflows and address real-world pain points. Patients and public health officials can help guide AI deployments in a way that maximizes reach to those in need (for instance, focusing on community health centers or screening programs). This multistakeholder approach is vital to overcome inertia and address concerns from all angles—from legal liability to ethical use to technical support [72].
The consensus statements naturally point toward several future directions in both research and policy to fully realize AI’s benefits for osteoporosis in the Asia-Pacific region. First, prospective clinical trials and real-world implementation studies are urgently needed (as highlighted in Statement 8). Another future direction is the use of federated learning and collaborative networks across the Asia-Pacific region to train AI models without breaching data privacy (tying into Statement 9). For example, hospitals in various nations could work together to develop a model by training on local data and communicating only model parameters (not patient data) with a central aggregator. In this way, an “Asia-Pacific osteoporosis AI” could be developed that learns from the heterogeneity of the region while respecting data sovereignty. Early examples of such federated approaches in medicine are appearing and given the emphasis on cross-border restrictions in the consensus, this could be a key strategy moving forward. It will require coordination and trust between institutions, and possibly facilitation by international bodies (perhaps IOF or the Asia Pacific Consortium on Osteoporosis (APCO) could spearhead such an initiative for bone health AI, such as how they do audits and frameworks). Furthermore, in Asia-Pacific region, where medical curricula vary greatly, there may be initiatives (possibly spearheaded by major organizations or regional associations) to build modules on AI in osteoporosis/bone health. Trainees may learn how to understand an AI-generated bone report or how to critically evaluate an AI tool’s validation paper. The consensus’ attitude on training (Statement 10) supports this trend, and as a result, healthcare firms should explore upskilling their personnel concurrently with AI adoption.
Despite its promise, AI in osteoporosis care remains constrained by several important limitations (Statement 12) that must temper expectations. Technically, AI performance depends heavily on image quality and dataset representativeness; algorithms trained on narrow datasets may fail when confronted with new imaging devices, ethnicities, or disease patterns [20]. Clinically, AI is a screening adjunct, not a diagnostic replacement—false negatives could delay treatment, while false positives could increase unnecessary testing. Furthermore, algorithmic bias may exacerbate inequities if underserved populations are underrepresented in training data, reinforcing the “digital divide” across the Asia-Pacific region [73]. Economically, cost-effectiveness remains uncertain, as many AI tools have yet to prove their real-world impact on fracture reduction [31, 74]. Therefore, continuous post-market validation, transparency about model uncertainty, and equitable access must be prioritized to ensure that AI enhances rather than undermines clinical care. This awareness of AI limitations forms the ethical cornerstone of safe adoption and u
Comments (0)